 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference Time Context Sparsity: Illusion or Opportunity?
May 22, 2026Sparsity has long been a central theme in LLM efficiency, but its role in context processing remains unresolved. As LLM workloads shift toward longer contexts and agentic interactions, the compute and memory bottlenecks of attention become increasingly critical, raising the question of whether these constraints are fundamental. Our position is that these constraints are artificial and unnecessary, and that the future of LLM inference lies in extreme but principled sparsity along the context dimension. This position is supported by several strands of empirical and theoretical evidence. First, we find the insistence on dense attention unreasonable, since in a long context a query effectively projects O(N) attention information into a hidden space of dimension d << N, making the process inherently lossy. Second, we perform an extensive study of sparsity in LLMs spanning 20 models across five model families, varying context lengths, and different sparsity levels. We empirically demonstrate a strong trend: current LLMs, despite not being trained for context sparsity, are remarkably robust to inference-time decode sparsity across tasks of varying complexity, including retrieval, multi-hop QA, mathematical reasoning, and agentic coding. Importantly, we also show that current hardware is already sufficient to realize substantial gains from this sparsity. For example, our sparse decode kernels accelerate large-context processing by up to 10x over FlashInfer at 50x sparsity levels on hardware such as the H100. Overall, these results position extreme context sparsity not as a heuristic, but as a principled foundation for LLM inference, training, and architecture design: one that is both feasible and beneficial, and a compelling direction for future systems.
RedunCut: Measurement-Driven Sampling and Accuracy Performance Modeling for Low-Cost Live Video Analytics
Dec 30, 2025Live video analytics (LVA) runs continuously across massive camera fleets, but inference cost with modern vision models remains high. To address this, dynamic model size selection (DMSS) is an attractive approach: it is content-aware but treats models as black boxes, and could potentially reduce cost by up to 10x without model retraining or modification. Without ground truth labels at runtime, we observe that DMSS methods use two stages per segment: (i) sampling a few models to calculate prediction statistics (e.g., confidences), then (ii) selection of the model size from those statistics. Prior systems fail to generalize to diverse workloads, particularly to mobile videos and lower accuracy targets. We identify that the failure modes stem from inefficient sampling whose cost exceeds its benefit, and inaccurate per-segment accuracy prediction. In this work, we present RedunCut, a new DMSS system that addresses both: It uses a measurement-driven planner that estimates the cost-benefit tradeoff of sampling, and a lightweight, data-driven performance model to improve accuracy prediction. Across road-vehicle, drone, and surveillance videos and multiple model families and tasks, RedunCut reduces compute cost by 14-62% at fixed accuracy and remains robust to limited historical data and to drift.
Atlas: Multi-Scale Attention Improves Long Context Image Modeling
Mar 16, 2025Efficiently modeling massive images is a long-standing challenge in machine learning. To this end, we introduce Multi-Scale Attention (MSA). MSA relies on two key ideas, (i) multi-scale representations (ii) bi-directional cross-scale communication. MSA creates O(log N) scales to represent the image across progressively coarser features and leverages cross-attention to propagate information across scales. We then introduce Atlas, a novel neural network architecture based on MSA. We demonstrate that Atlas significantly improves the compute-performance tradeoff of long-context image modeling in a high-resolution variant of ImageNet 100. At 1024px resolution, Atlas-B achieves 91.04% accuracy, comparable to ConvNext-B (91.92%) while being 4.3x faster. Atlas is 2.95x faster and 7.38% better than FasterViT, 2.25x faster and 4.96% better than LongViT. In comparisons against MambaVision-S, we find Atlas-S achieves 5%, 16% and 32% higher accuracy at 1024px, 2048px and 4096px respectively, while obtaining similar runtimes. Code for reproducing our experiments and pretrained models is available at https://github.com/yalalab/atlas.
Addressing Sample Inefficiency in Multi-View Representation Learning
Dec 17, 2023



Non-contrastive self-supervised learning (NC-SSL) methods like BarlowTwins and VICReg have shown great promise for label-free representation learning in computer vision. Despite the apparent simplicity of these techniques, researchers must rely on several empirical heuristics to achieve competitive performance, most notably using high-dimensional projector heads and two augmentations of the same image. In this work, we provide theoretical insights on the implicit bias of the BarlowTwins and VICReg loss that can explain these heuristics and guide the development of more principled recommendations. Our first insight is that the orthogonality of the features is more critical than projector dimensionality for learning good representations. Based on this, we empirically demonstrate that low-dimensional projector heads are sufficient with appropriate regularization, contrary to the existing heuristic. Our second theoretical insight suggests that using multiple data augmentations better represents the desiderata of the SSL objective. Based on this, we demonstrate that leveraging more augmentations per sample improves representation quality and trainability. In particular, it improves optimization convergence, leading to better features emerging earlier in the training. Remarkably, we demonstrate that we can reduce the pretraining dataset size by up to 4x while maintaining accuracy and improving convergence simply by using more data augmentations. Combining these insights, we present practical pretraining recommendations that improve wall-clock time by 2x and improve performance on CIFAR-10/STL-10 datasets using a ResNet-50 backbone. Thus, this work provides a theoretical insight into NC-SSL and produces practical recommendations for enhancing its sample and compute efficiency.
Attribute Diversity Determines the Systematicity Gap in VQA
Nov 15, 2023



The degree to which neural networks can generalize to new combinations of familiar concepts, and the conditions under which they are able to do so, has long been an open question. In this work, we study the systematicity gap in visual question answering: the performance difference between reasoning on previously seen and unseen combinations of object attributes. To test, we introduce a novel diagnostic dataset, CLEVR-HOPE. We find that while increased quantity of training data does not reduce the systematicity gap, increased training data diversity of the attributes in the unseen combination does. In all, our experiments suggest that the more distinct attribute type combinations are seen during training, the more systematic we can expect the resulting model to be.
Context-Aware Streaming Perception in Dynamic Environments
Aug 16, 2022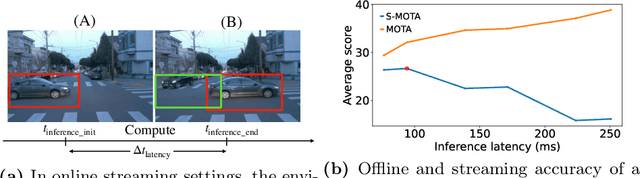
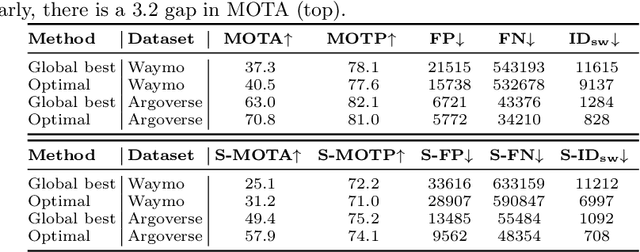
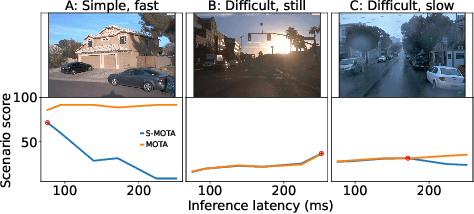
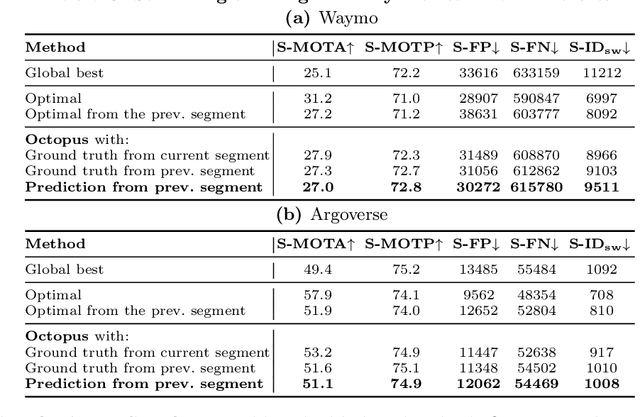
Efficient vision works maximize accuracy under a latency budget. These works evaluate accuracy offline, one image at a time. However, real-time vision applications like autonomous driving operate in streaming settings, where ground truth changes between inference start and finish. This results in a significant accuracy drop. Therefore, a recent work proposed to maximize accuracy in streaming settings on average. In this paper, we propose to maximize streaming accuracy for every environment context. We posit that scenario difficulty influences the initial (offline) accuracy difference, while obstacle displacement in the scene affects the subsequent accuracy degradation. Our method, Octopus, uses these scenario properties to select configurations that maximize streaming accuracy at test time. Our method improves tracking performance (S-MOTA) by 7.4% over the conventional static approach. Further, performance improvement using our method comes in addition to, and not instead of, advances in offline accuracy.
Investigating Power laws in Deep Representation Learning
Feb 11, 2022Representation learning that leverages large-scale labelled datasets, is central to recent progress in machine learning. Access to task relevant labels at scale is often scarce or expensive, motivating the need to learn from unlabelled datasets with self-supervised learning (SSL). Such large unlabelled datasets (with data augmentations) often provide a good coverage of the underlying input distribution. However evaluating the representations learned by SSL algorithms still requires task-specific labelled samples in the training pipeline. Additionally, the generalization of task-specific encoding is often sensitive to potential distribution shift. Inspired by recent advances in theoretical machine learning and vision neuroscience, we observe that the eigenspectrum of the empirical feature covariance matrix often follows a power law. For visual representations, we estimate the coefficient of the power law, $\alpha$, across three key attributes which influence representation learning: learning objective (supervised, SimCLR, Barlow Twins and BYOL), network architecture (VGG, ResNet and Vision Transformer), and tasks (object and scene recognition). We observe that under mild conditions, proximity of $\alpha$ to 1, is strongly correlated to the downstream generalization performance. Furthermore, $\alpha \approx 1$ is a strong indicator of robustness to label noise during fine-tuning. Notably, $\alpha$ is computable from the representations without knowledge of any labels, thereby offering a framework to evaluate the quality of representations in unlabelled datasets.
Learning from an Exploring Demonstrator: Optimal Reward Estimation for Bandits
Jun 28, 2021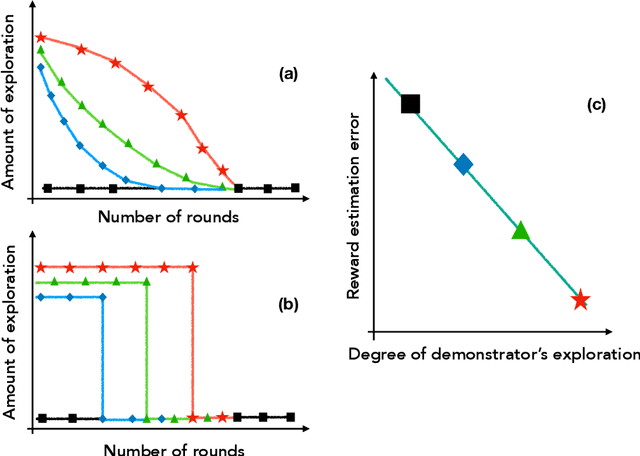
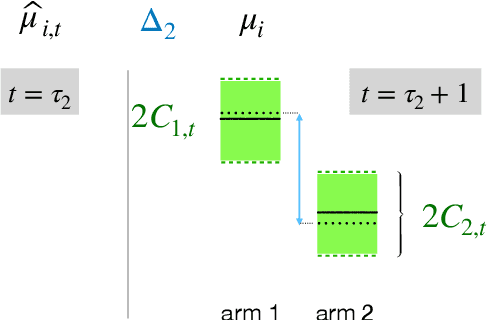
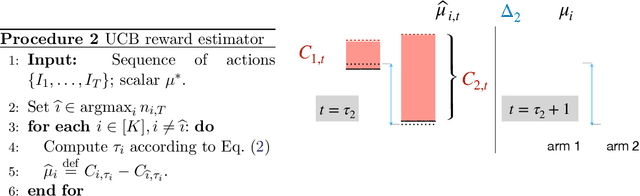
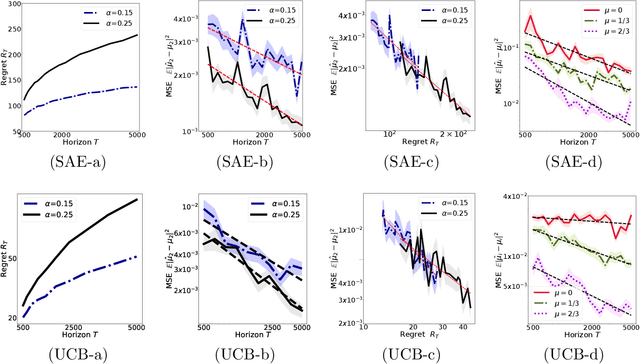
We introduce the "inverse bandit" problem of estimating the rewards of a multi-armed bandit instance from observing the learning process of a low-regret demonstrator. Existing approaches to the related problem of inverse reinforcement learning assume the execution of an optimal policy, and thereby suffer from an identifiability issue. In contrast, our paradigm leverages the demonstrator's behavior en route to optimality, and in particular, the exploration phase, to obtain consistent reward estimates. We develop simple and efficient reward estimation procedures for demonstrations within a class of upper-confidence-based algorithms, showing that reward estimation gets progressively easier as the regret of the algorithm increases. We match these upper bounds with information-theoretic lower bounds that apply to any demonstrator algorithm, thereby characterizing the optimal tradeoff between exploration and reward estimation. Extensive empirical evaluations on both synthetic data and simulated experimental design data from the natural sciences corroborate our theoretical results.
Discrete Flows: Invertible Generative Models of Discrete Data
May 24, 2019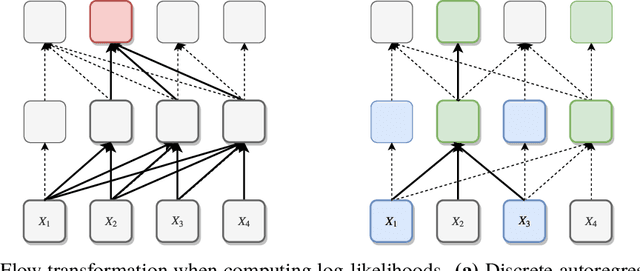

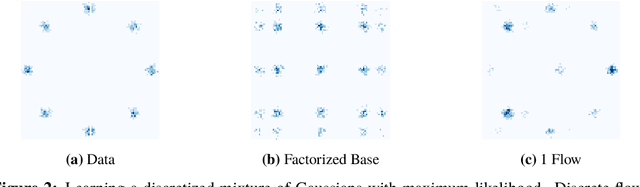
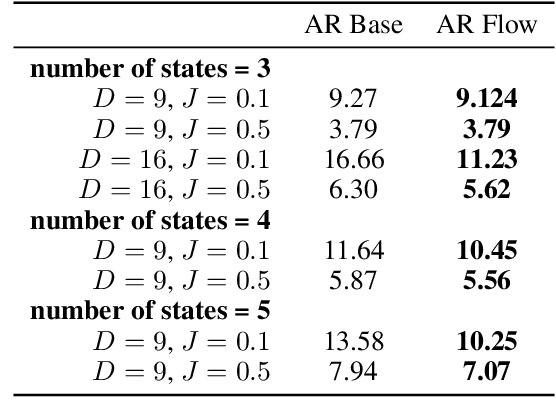
While normalizing flows have led to significant advances in modeling high-dimensional continuous distributions, their applicability to discrete distributions remains unknown. In this paper, we show that flows can in fact be extended to discrete events---and under a simple change-of-variables formula not requiring log-determinant-Jacobian computations. Discrete flows have numerous applications. We consider two flow architectures: discrete autoregressive flows that enable bidirectionality, allowing, for example, tokens in text to depend on both left-to-right and right-to-left contexts in an exact language model; and discrete bipartite flows that enable efficient non-autoregressive generation as in RealNVP. Empirically, we find that discrete autoregressive flows outperform autoregressive baselines on synthetic discrete distributions, an addition task, and Potts models; and bipartite flows can obtain competitive performance with autoregressive baselines on character-level language modeling for Penn Tree Bank and text8.
GANSynth: Adversarial Neural Audio Synthesis
Apr 15, 2019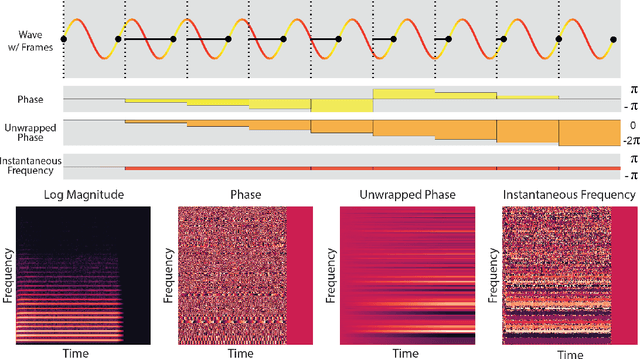
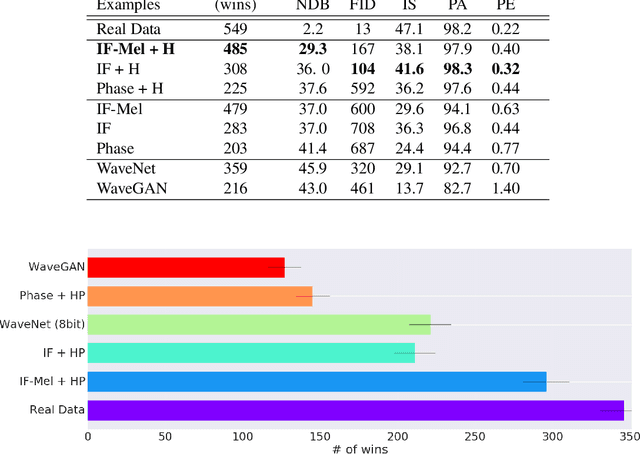
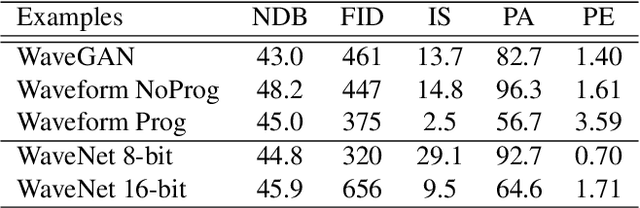
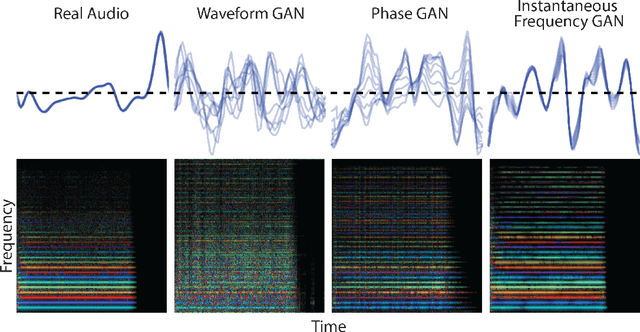
Efficient audio synthesis is an inherently difficult machine learning task, as human perception is sensitive to both global structure and fine-scale waveform coherence. Autoregressive models, such as WaveNet, model local structure at the expense of global latent structure and slow iterative sampling, while Generative Adversarial Networks (GANs), have global latent conditioning and efficient parallel sampling, but struggle to generate locally-coherent audio waveforms. Herein, we demonstrate that GANs can in fact generate high-fidelity and locally-coherent audio by modeling log magnitudes and instantaneous frequencies with sufficient frequency resolution in the spectral domain. Through extensive empirical investigations on the NSynth dataset, we demonstrate that GANs are able to outperform strong WaveNet baselines on automated and human evaluation metrics, and efficiently generate audio several orders of magnitude faster than their autoregressive counterparts.