 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Imitative Models for Flexible Inference, Planning, and Control
Paper and Code
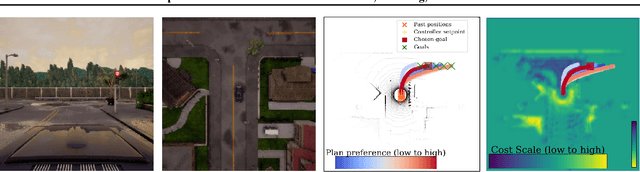
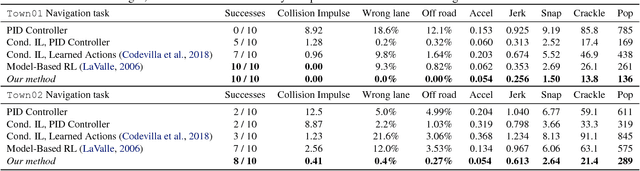
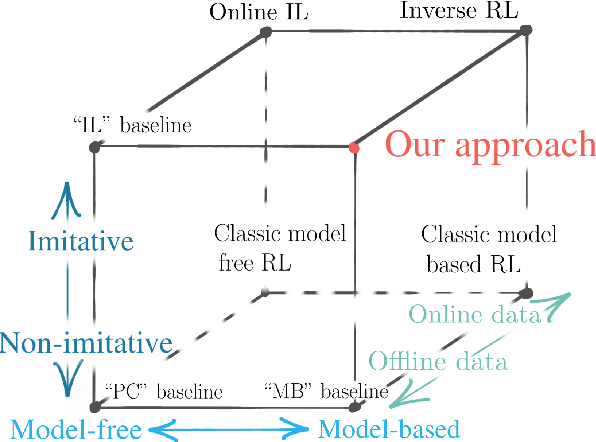

Imitation learning provides an appealing framework for autonomous control: in many tasks, demonstrations of preferred behavior can be readily obtained from human experts, removing the need for costly and potentially dangerous online data collection in the real world. However, policies learned with imitation learning have limited flexibility to accommodate varied goals at test-time. Model-based reinforcement learning (MBRL) offers considerably more flexibility, since a predictive model learned from data can be used to achieve various goals at test-time. However, MBRL suffers from two shortcomings. First, the model does not help to choose desired or safe outcomes -- its dynamics estimate only what is possible, not what is preferred. Second, MBRL typically requires additional online data collection to ensure that the model is accurate in those situations that are actually encountered when attempting to achieve test-time goals. Collecting this data with a partially trained model can be dangerous and time-consuming. In this paper, we aim to combine the benefits of imitation learning and MBRL, and propose imitative models: probabilistic predictive models able to plan expert-like trajectories to achieve arbitrary goals. We find this method substantially outperforms both direct imitation and MBRL in a simulated autonomous driving task, and can be learned efficiently from a fixed set of expert demonstrations without additional online data collection. We also show our model can flexibly incorporate user-supplied costs at test-time, can plan to sequences of goals, and can even perform well with imprecise goals, including goals on the wrong side of the road.