 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hamilton-Jacobi Reachability-Based Framework for Predicting and Analyzing Human Motion for Safe Planning
Oct 29, 2019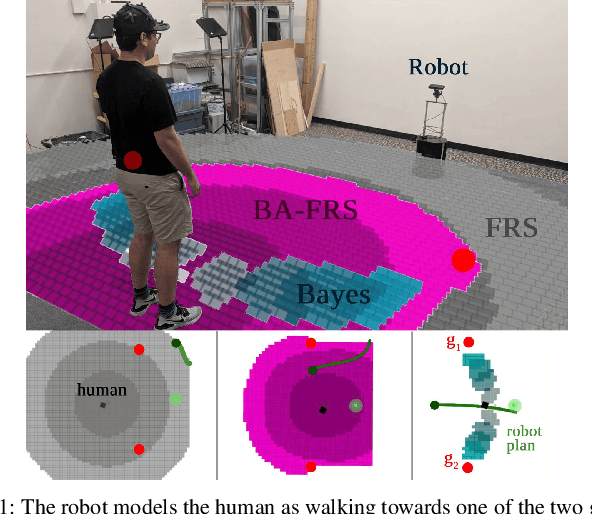
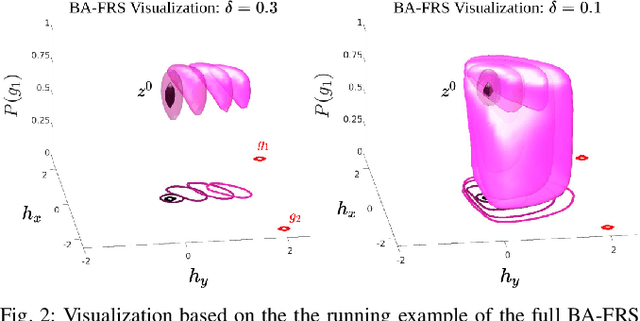
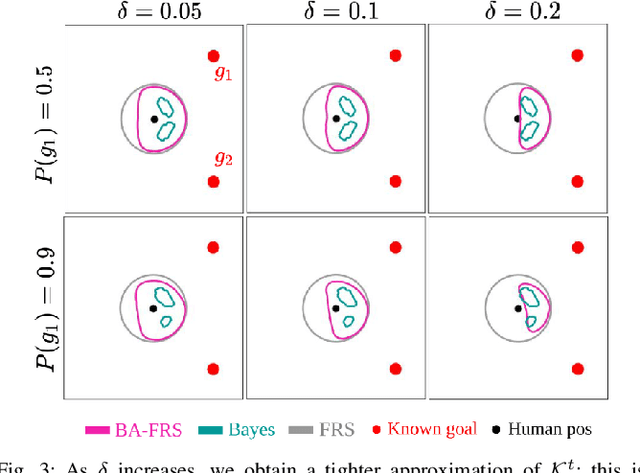
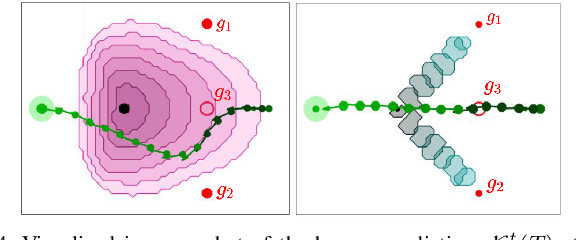
Real-world autonomous systems often employ probabilistic predictive models of human behavior during planning to reason about their future motion. Since accurately modeling the human behavior a priori is challenging, such models are often parameterized, enabling the robot to adapt predictions based on observations by maintaining a distribution over the model parameters. This leads to a probabilistic prediction problem, which even though attractive, can be computationally demanding. In this work, we formalize the prediction problem as a stochastic reachability problem in the joint state space of the human and the belief over the model parameters. We further introduce a Hamilton-Jacobi reachability framework which casts a deterministic approximation of this stochastic reachability problem by restricting the allowable actions to a set rather than a distribution, while still maintaining the belief as an explicit state. This leads to two advantages: our approach gives rise to a novel predictor wherein the predictions can be performed at a significantly lower computational expense, and to a general framework which also enables us to perform predictor analysis. We compare our approach to a fully stochastic predictor using Bayesian inference and the worst-case forward reachable set in simulation and in hardware, and demonstrate how it can enable robust planning while not being overly conservative, even when the human model is inaccurate.
Efficient Iterative Linear-Quadratic Approximations for Nonlinear Multi-Player General-Sum Differential Games
Sep 12, 2019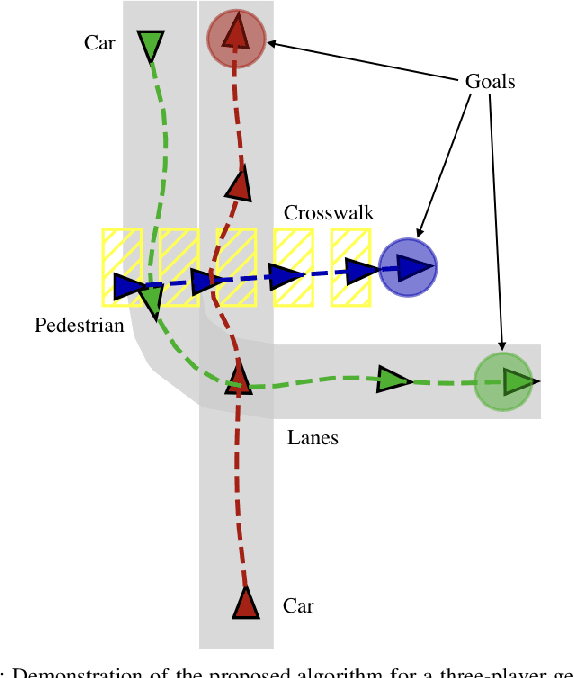
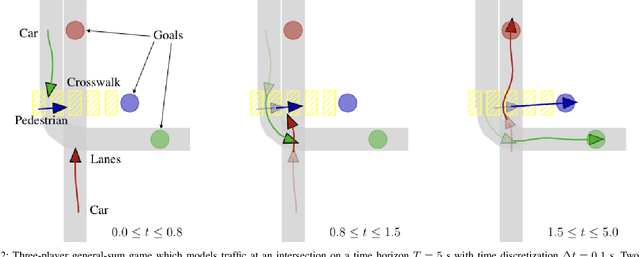
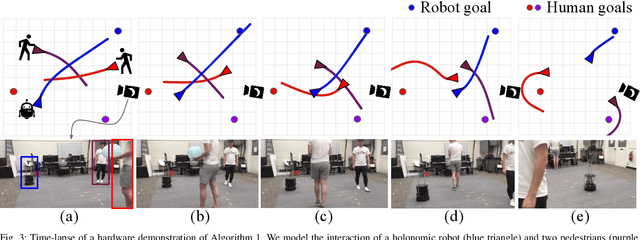
Differential games offer a powerful theoretical framework for formulating safety and robustness problems in optimal control. Unfortunately, numerical solution techniques for general nonlinear dynamical systems scale poorly with state dimension and are rarely used in applications requiring real-time computation. For single-agent optimal control problems, however, local methods based on efficiently solving iterated approximations with linear dynamics and quadratic costs are becoming increasingly popular. We take inspiration from one such method, the iterative linear quadratic regulator (ILQR), and observe that efficient algorithms also exist to solve multi-player linear-quadratic games. Whereas ILQR converges to a local solution of the optimal control problem, if our method converges it returns a local Nash equilibrium of the differential game. We benchmark our method in a three-player general-sum simulated example, in which it takes < 0.75 s to identify a solution and < 50 ms to solve warm-started subproblems in a receding horizon. We also demonstrate our approach in hardware, operating in real-time and following a 10 s receding horizon.
Learning a Prior over Intent via Meta-Inverse Reinforcement Learning
Oct 10, 2018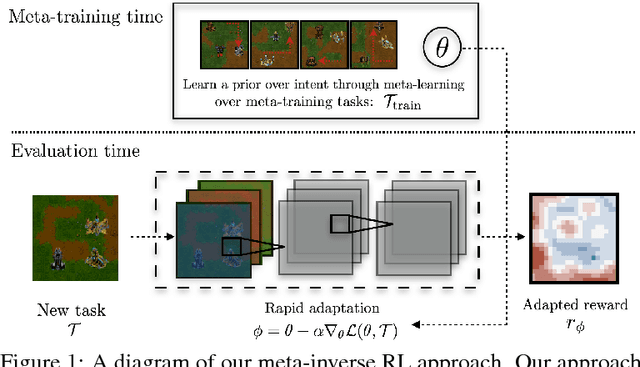

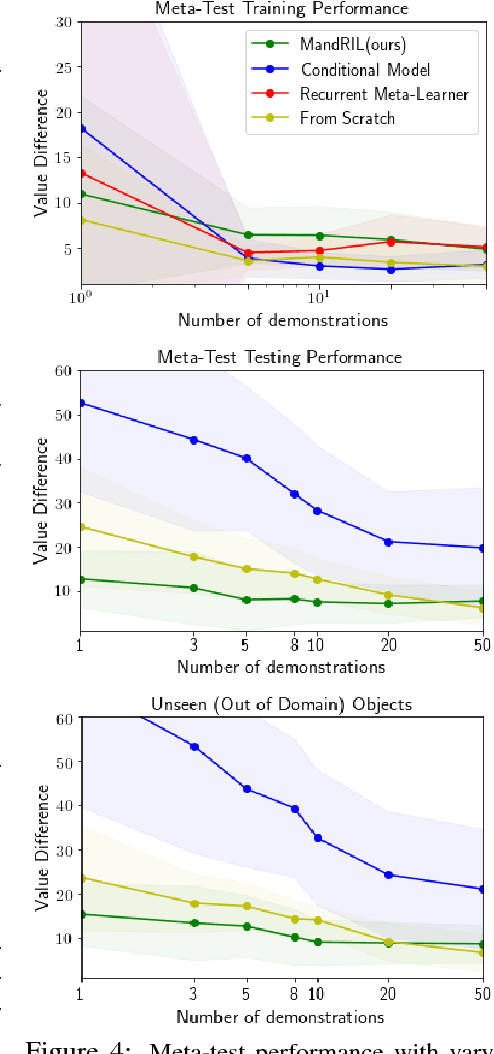
A significant challenge for the practical application of reinforcement learning in the real world is the need to specify an oracle reward function that correctly defines a task. Inverse reinforcement learning (IRL) seeks to avoid this challenge by instead inferring a reward function from expert behavior. While appealing, it can be impractically expensive to collect datasets of demonstrations that cover the variation common in the real world (e.g. opening any type of door). Thus in practice, IRL must commonly be performed with only a limited set of demonstrations where it can be exceedingly difficult to unambiguously recover a reward function. In this work, we exploit the insight that demonstrations from other tasks can be used to constrain the set of possible reward functions by learning a "prior" that is specifically optimized for the ability to infer expressive reward functions from limited numbers of demonstrations. We demonstrate that our method can efficiently recover rewards from images for novel tasks and provide intuition as to how our approach is analogous to learning a prior.
Simplifying Reward Design through Divide-and-Conquer
Jun 07, 2018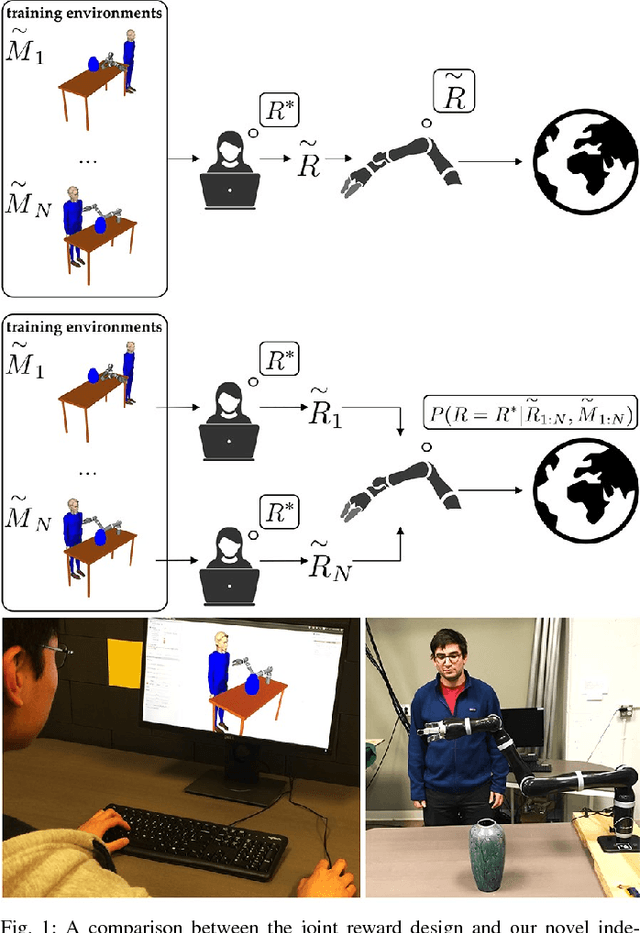
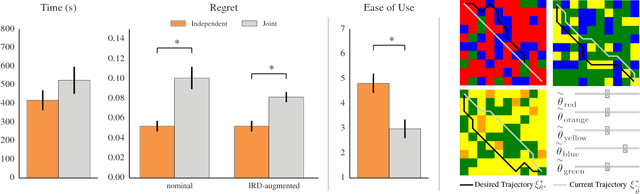
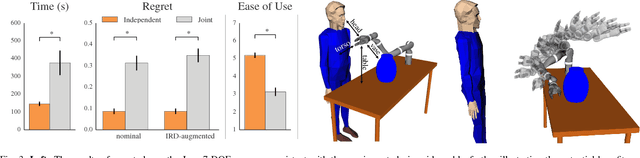
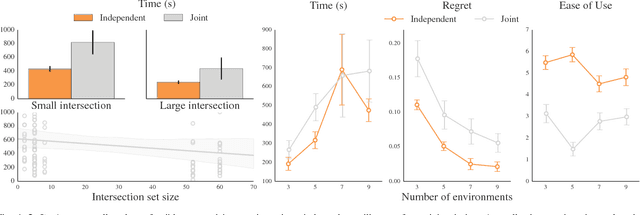
Designing a good reward function is essential to robot planning and reinforcement learning, but it can also be challenging and frustrating. The reward needs to work across multiple different environments, and that often requires many iterations of tuning. We introduce a novel divide-and-conquer approach that enables the designer to specify a reward separately for each environment. By treating these separate reward functions as observations about the underlying true reward, we derive an approach to infer a common reward across all environments. We conduct user studies in an abstract grid world domain and in a motion planning domain for a 7-DOF manipulator that measure user effort and solution quality. We show that our method is faster, easier to use, and produces a higher quality solution than the typical method of designing a reward jointly across all environments. We additionally conduct a series of experiments that measure the sensitivity of these results to different properties of the reward design task, such as the number of environments, the number of feasible solutions per environment, and the fraction of the total features that vary within each environment. We find that independent reward design outperforms the standard, joint, reward design process but works best when the design problem can be divided into simpler subproblems.