 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability
Jul 13, 2021

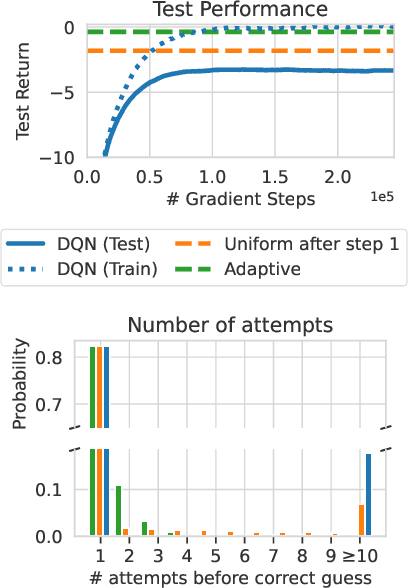
Generalization is a central challenge for the deployment of reinforcement learning (RL) systems in the real world. In this paper, we show that the sequential structure of the RL problem necessitates new approaches to generalization beyond the well-studied techniques used in supervised learning. While supervised learning methods can generalize effectively without explicitly accounting for epistemic uncertainty, we show that, perhaps surprisingly, this is not the case in RL. We show that generalization to unseen test conditions from a limited number of training conditions induces implicit partial observability, effectively turning even fully-observed MDPs into POMDPs. Informed by this observation, we recast the problem of generalization in RL as solving the induced partially observed Markov decision process, which we call the epistemic POMDP. We demonstrate the failure modes of algorithms that do not appropriately handle this partial observability, and suggest a simple ensemble-based technique for approximately solving the partially observed problem. Empirically, we demonstrate that our simple algorithm derived from the epistemic POMDP achieves significant gains in generalization over current methods on the Procgen benchmark suite.
Explore and Control with Adversarial Surprise
Jul 12, 2021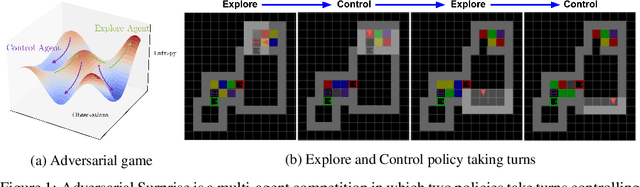
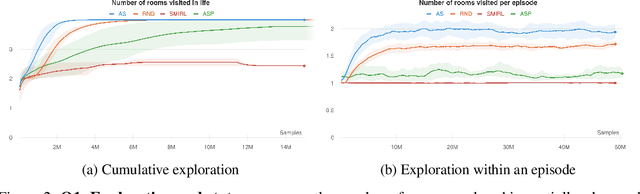
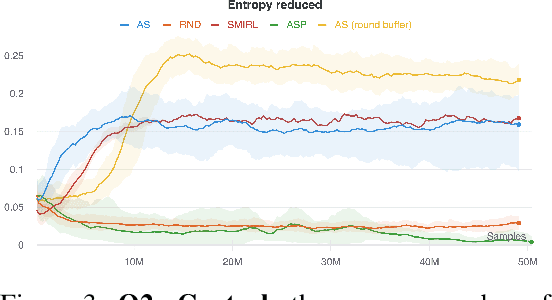
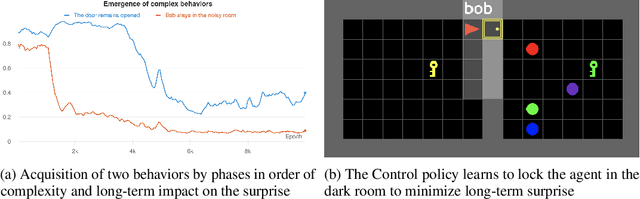
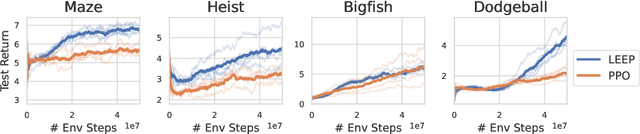
Reinforcement learning (RL) provides a framework for learning goal-directed policies given user-specified rewards. However, since designing rewards often requires substantial engineering effort, we are interested in the problem of learning without rewards, where agents must discover useful behaviors in the absence of task-specific incentives. Intrinsic motivation is a family of unsupervised RL techniques which develop general objectives for an RL agent to optimize that lead to better exploration or the discovery of skills. In this paper, we propose a new unsupervised RL technique based on an adversarial game which pits two policies against each other to compete over the amount of surprise an RL agent experiences. The policies each take turns controlling the agent. The Explore policy maximizes entropy, putting the agent into surprising or unfamiliar situations. Then, the Control policy takes over and seeks to recover from those situations by minimizing entropy. The game harnesses the power of multi-agent competition to drive the agent to seek out increasingly surprising parts of the environment while learning to gain mastery over them. We show empirically that our method leads to the emergence of complex skills by exhibiting clear phase transitions. Furthermore, we show both theoretically (via a latent state space coverage argument) and empirically that our method has the potential to be applied to the exploration of stochastic, partially-observed environments. We show that Adversarial Surprise learns more complex behaviors, and explores more effectively than competitive baselines, outperforming intrinsic motivation methods based on active inference, novelty-seeking (Random Network Distillation (RND)), and multi-agent unsupervised RL (Asymmetric Self-Play (ASP)) in MiniGrid, Atari and VizDoom environments.
Pragmatic Image Compression for Human-in-the-Loop Decision-Making
Jul 07, 2021

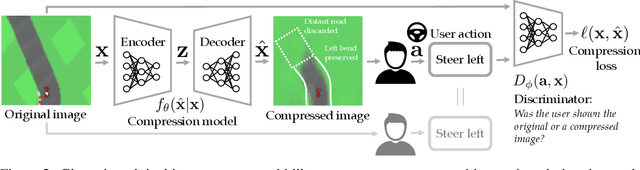
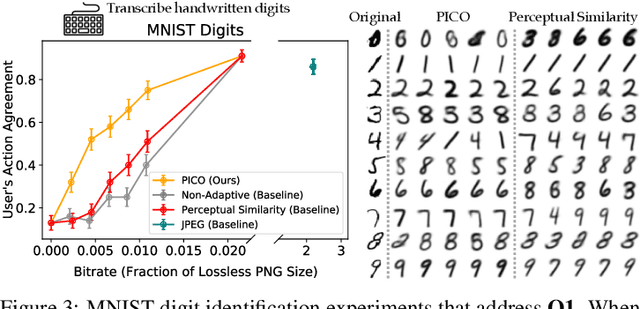
Standard lossy image compression algorithms aim to preserve an image's appearance, while minimizing the number of bits needed to transmit it. However, the amount of information actually needed by a user for downstream tasks -- e.g., deciding which product to click on in a shopping website -- is likely much lower. To achieve this lower bitrate, we would ideally only transmit the visual features that drive user behavior, while discarding details irrelevant to the user's decisions. We approach this problem by training a compression model through human-in-the-loop learning as the user performs tasks with the compressed images. The key insight is to train the model to produce a compressed image that induces the user to take the same action that they would have taken had they seen the original image. To approximate the loss function for this model, we train a discriminator that tries to distinguish whether a user's action was taken in response to the compressed image or the original. We evaluate our method through experiments with human participants on four tasks: reading handwritten digits, verifying photos of faces, browsing an online shopping catalogue, and playing a car racing video game. The results show that our method learns to match the user's actions with and without compression at lower bitrates than baseline methods, and adapts the compression model to the user's behavior: it preserves the digit number and randomizes handwriting style in the digit reading task, preserves hats and eyeglasses while randomizing faces in the photo verification task, preserves the perceived price of an item while randomizing its color and background in the online shopping task, and preserves upcoming bends in the road in the car racing game.
Multi-Robot Deep Reinforcement Learning for Mobile Navigation
Jun 24, 2021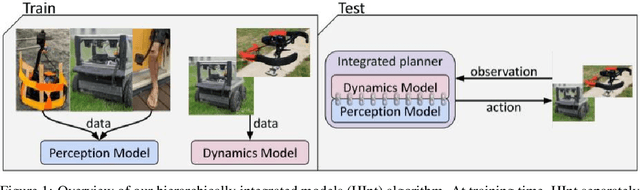
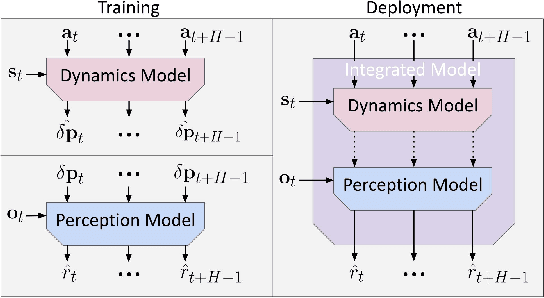

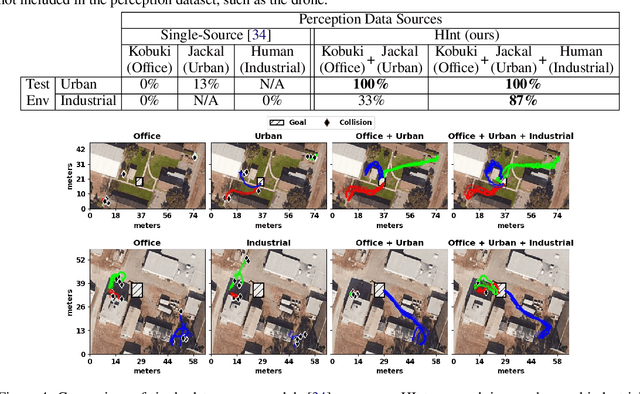
Deep reinforcement learning algorithms require large and diverse datasets in order to learn successful policies for perception-based mobile navigation. However, gathering such datasets with a single robot can be prohibitively expensive. Collecting data with multiple different robotic platforms with possibly different dynamics is a more scalable approach to large-scale data collection. But how can deep reinforcement learning algorithms leverage such heterogeneous datasets? In this work, we propose a deep reinforcement learning algorithm with hierarchically integrated models (HInt). At training time, HInt learns separate perception and dynamics models, and at test time, HInt integrates the two models in a hierarchical manner and plans actions with the integrated model. This method of planning with hierarchically integrated models allows the algorithm to train on datasets gathered by a variety of different platforms, while respecting the physical capabilities of the deployment robot at test time. Our mobile navigation experiments show that HInt outperforms conventional hierarchical policies and single-source approaches.
Model-Based Reinforcement Learning via Latent-Space Collocation
Jun 24, 2021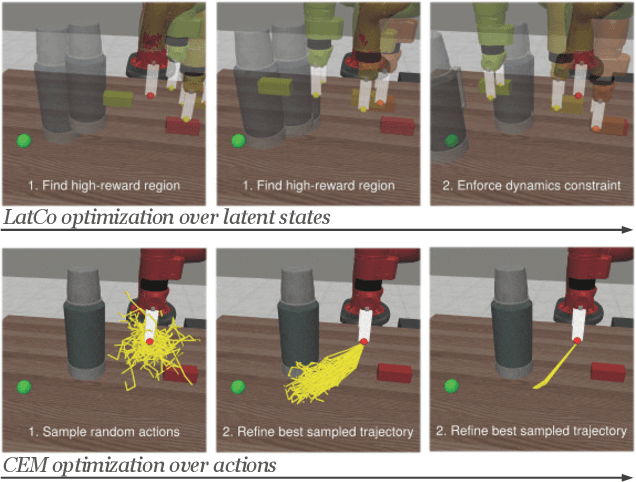
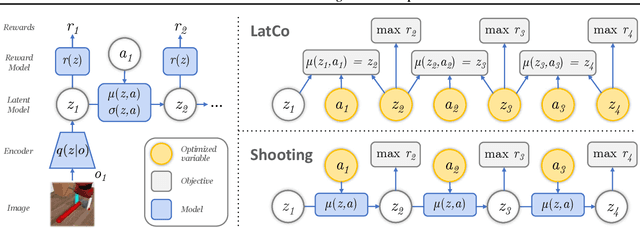

The ability to plan into the future while utilizing only raw high-dimensional observations, such as images, can provide autonomous agents with broad capabilities. Visual model-based reinforcement learning (RL) methods that plan future actions directly have shown impressive results on tasks that require only short-horizon reasoning, however, these methods struggle on temporally extended tasks. We argue that it is easier to solve long-horizon tasks by planning sequences of states rather than just actions, as the effects of actions greatly compound over time and are harder to optimize. To achieve this, we draw on the idea of collocation, which has shown good results on long-horizon tasks in optimal control literature, and adapt it to the image-based setting by utilizing learned latent state space models. The resulting latent collocation method (LatCo) optimizes trajectories of latent states, which improves over previously proposed shooting methods for visual model-based RL on tasks with sparse rewards and long-term goals. Videos and code at https://orybkin.github.io/latco/.
FitVid: Overfitting in Pixel-Level Video Prediction
Jun 24, 2021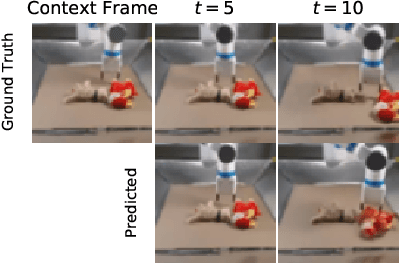


An agent that is capable of predicting what happens next can perform a variety of tasks through planning with no additional training. Furthermore, such an agent can internally represent the complex dynamics of the real-world and therefore can acquire a representation useful for a variety of visual perception tasks. This makes predicting the future frames of a video, conditioned on the observed past and potentially future actions, an interesting task which remains exceptionally challenging despite many recent advances. Existing video prediction models have shown promising results on simple narrow benchmarks but they generate low quality predictions on real-life datasets with more complicated dynamics or broader domain. There is a growing body of evidence that underfitting on the training data is one of the primary causes for the low quality predictions. In this paper, we argue that the inefficient use of parameters in the current video models is the main reason for underfitting. Therefore, we introduce a new architecture, named FitVid, which is capable of severe overfitting on the common benchmarks while having similar parameter count as the current state-of-the-art models. We analyze the consequences of overfitting, illustrating how it can produce unexpected outcomes such as generating high quality output by repeating the training data, and how it can be mitigated using existing image augmentation techniques. As a result, FitVid outperforms the current state-of-the-art models across four different video prediction benchmarks on four different metrics.
Which Mutual-Information Representation Learning Objectives are Sufficient for Control?
Jun 14, 2021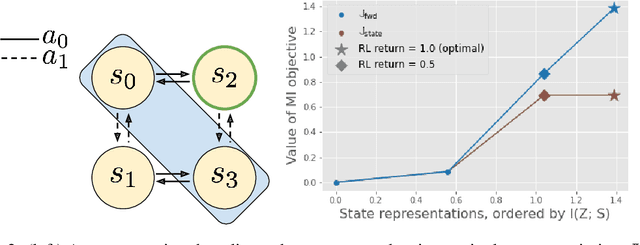
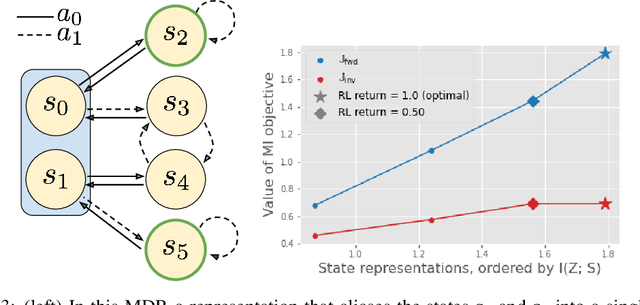
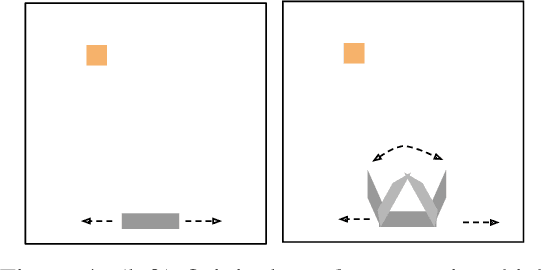
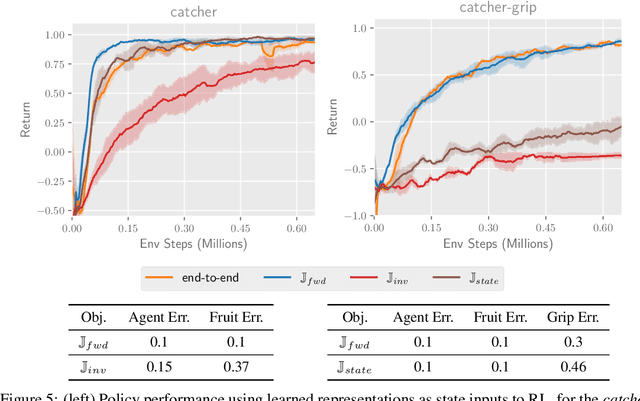
Mutual information maximization provides an appealing formalism for learning representations of data. In the context of reinforcement learning (RL), such representations can accelerate learning by discarding irrelevant and redundant information, while retaining the information necessary for control. Much of the prior work on these methods has addressed the practical difficulties of estimating mutual information from samples of high-dimensional observations, while comparatively less is understood about which mutual information objectives yield representations that are sufficient for RL from a theoretical perspective. In this paper, we formalize the sufficiency of a state representation for learning and representing the optimal policy, and study several popular mutual-information based objectives through this lens. Surprisingly, we find that two of these objectives can yield insufficient representations given mild and common assumptions on the structure of the MDP. We corroborate our theoretical results with empirical experiments on a simulated game environment with visual observations.
What Can I Do Here? Learning New Skills by Imagining Visual Affordances
Jun 13, 2021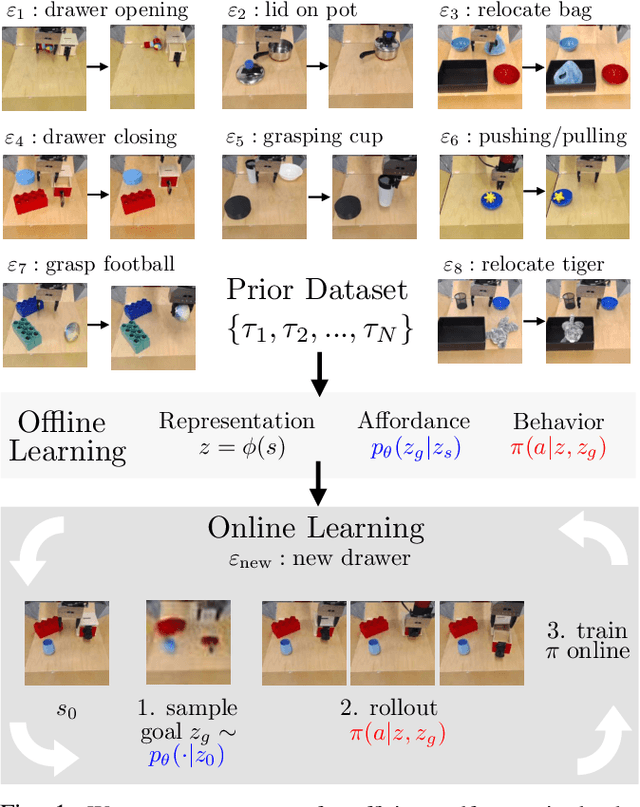


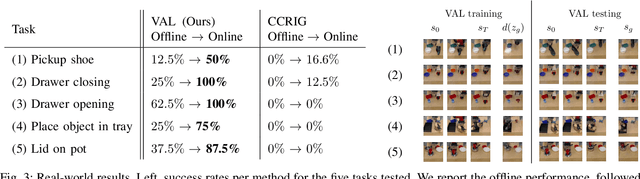
A generalist robot equipped with learned skills must be able to perform many tasks in many different environments. However, zero-shot generalization to new settings is not always possible. When the robot encounters a new environment or object, it may need to finetune some of its previously learned skills to accommodate this change. But crucially, previously learned behaviors and models should still be suitable to accelerate this relearning. In this paper, we aim to study how generative models of possible outcomes can allow a robot to learn visual representations of affordances, so that the robot can sample potentially possible outcomes in new situations, and then further train its policy to achieve those outcomes. In effect, prior data is used to learn what kinds of outcomes may be possible, such that when the robot encounters an unfamiliar setting, it can sample potential outcomes from its model, attempt to reach them, and thereby update both its skills and its outcome model. This approach, visuomotor affordance learning (VAL), can be used to train goal-conditioned policies that operate on raw image inputs, and can rapidly learn to manipulate new objects via our proposed affordance-directed exploration scheme. We show that VAL can utilize prior data to solve real-world tasks such drawer opening, grasping, and placing objects in new scenes with only five minutes of online experience in the new scene.
Reinforcement Learning as One Big Sequence Modeling Problem
Jun 03, 2021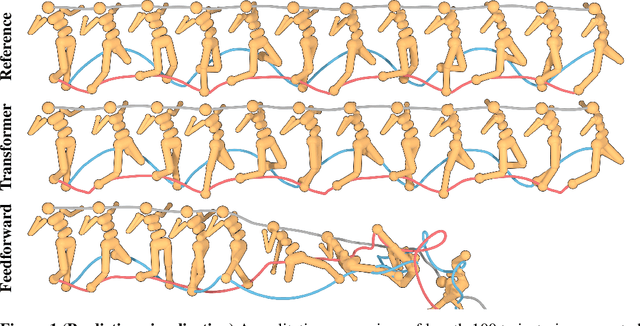
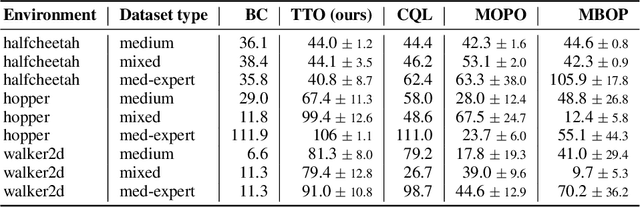
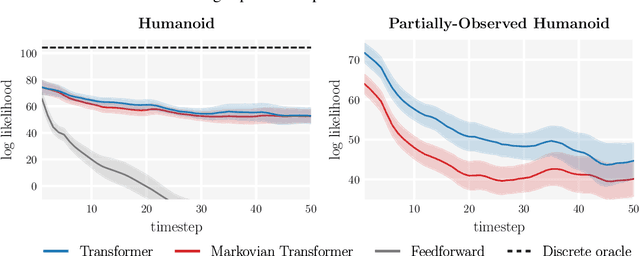
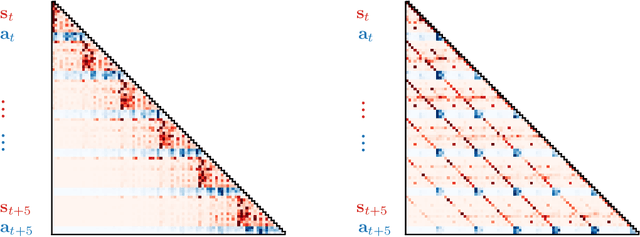
Reinforcement learning (RL) is typically concerned with estimating single-step policies or single-step models, leveraging the Markov property to factorize the problem in time. However, we can also view RL as a sequence modeling problem, with the goal being to predict a sequence of actions that leads to a sequence of high rewards. Viewed in this way, it is tempting to consider whether powerful, high-capacity sequence prediction models that work well in other domains, such as natural-language processing, can also provide simple and effective solutions to the RL problem. To this end, we explore how RL can be reframed as "one big sequence modeling" problem, using state-of-the-art Transformer architectures to model distributions over sequences of states, actions, and rewards. Addressing RL as a sequence modeling problem significantly simplifies a range of design decisions: we no longer require separate behavior policy constraints, as is common in prior work on offline model-free RL, and we no longer require ensembles or other epistemic uncertainty estimators, as is common in prior work on model-based RL. All of these roles are filled by the same Transformer sequence model. In our experiments, we demonstrate the flexibility of this approach across long-horizon dynamics prediction, imitation learning, goal-conditioned RL, and offline RL.
Variational Empowerment as Representation Learning for Goal-Based Reinforcement Learning
Jun 02, 2021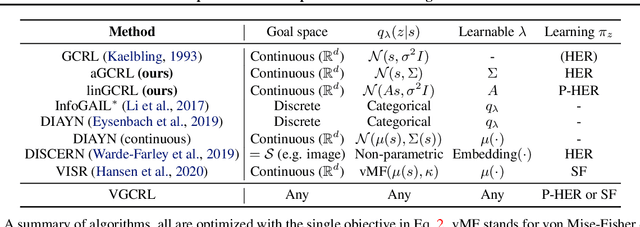
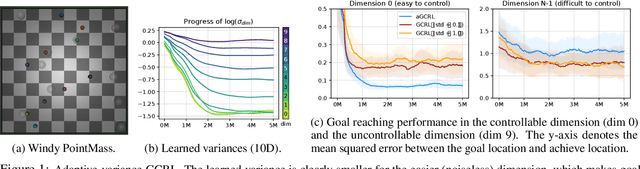
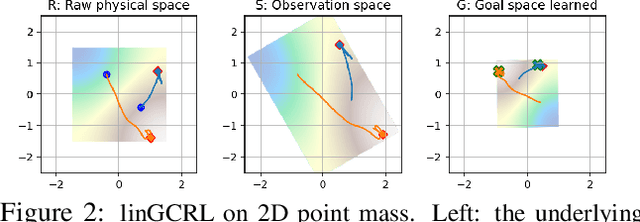

Learning to reach goal states and learning diverse skills through mutual information (MI) maximization have been proposed as principled frameworks for self-supervised reinforcement learning, allowing agents to acquire broadly applicable multitask policies with minimal reward engineering. Starting from a simple observation that the standard goal-conditioned RL (GCRL) is encapsulated by the optimization objective of variational empowerment, we discuss how GCRL and MI-based RL can be generalized into a single family of methods, which we name variational GCRL (VGCRL), interpreting variational MI maximization, or variational empowerment, as representation learning methods that acquire functionally-aware state representations for goal reaching. This novel perspective allows us to: (1) derive simple but unexplored variants of GCRL to study how adding small representation capacity can already expand its capabilities; (2) investigate how discriminator function capacity and smoothness determine the quality of discovered skills, or latent goals, through modifying latent dimensionality and applying spectral normalization; (3) adapt techniques such as hindsight experience replay (HER) from GCRL to MI-based RL; and lastly, (4) propose a novel evaluation metric, named latent goal reaching (LGR), for comparing empowerment algorithms with different choices of latent dimensionality and discriminator parameterization. Through principled mathematical derivations and careful experimental studies, our work lays a novel foundation from which to evaluate, analyze, and develop representation learning techniques in goal-based RL.