 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Prompt Tuning
Mar 23, 2022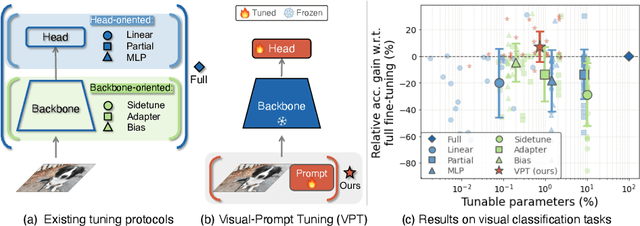

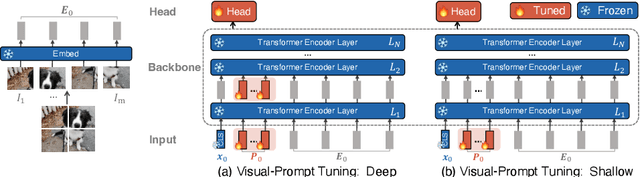
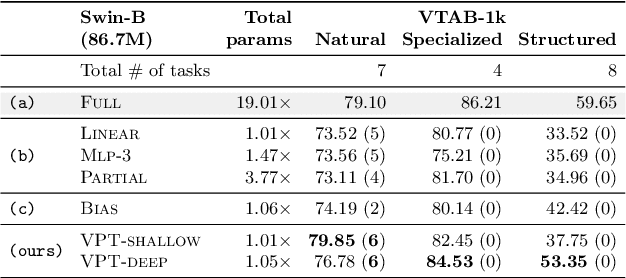
The current modus operandi in adapting pre-trained models involves updating all the backbone parameters, ie, full fine-tuning. This paper introduces Visual Prompt Tuning (VPT) as an efficient and effective alternative to full fine-tuning for large-scale Transformer models in vision. Taking inspiration from recent advances in efficiently tuning large language models, VPT introduces only a small amount (less than 1% of model parameters) of trainable parameters in the input space while keeping the model backbone frozen. Via extensive experiments on a wide variety of downstream recognition tasks, we show that VPT achieves significant performance gains compared to other parameter efficient tuning protocols. Most importantly, VPT even outperforms full fine-tuning in many cases across model capacities and training data scales, while reducing per-task storage cost.
Residual Aligned: Gradient Optimization for Non-Negative Image Synthesis
Feb 08, 2022



In this work, we address an important problem of optical see through (OST) augmented reality: non-negative image synthesis. Most of the image generation methods fail under this condition, since they assume full control over each pixel and cannot create darker pixels by adding light. In order to solve the non-negative image generation problem in AR image synthesis, prior works have attempted to utilize optical illusion to simulate human vision but fail to preserve lightness constancy well under situations such as high dynamic range. In our paper, we instead propose a method that is able to preserve lightness constancy at a local level, thus capturing high frequency details. Compared with existing work, our method shows strong performance in image-to-image translation tasks, particularly in scenarios such as large scale images, high resolution images, and high dynamic range image transfer.
Stay Positive: Non-Negative Image Synthesis for Augmented Reality
Feb 01, 2022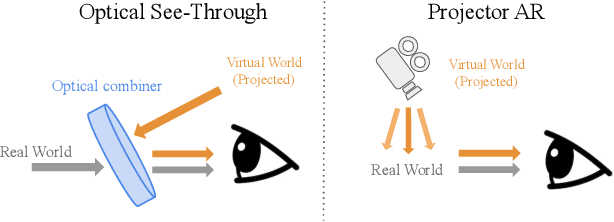
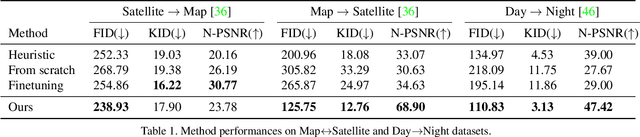
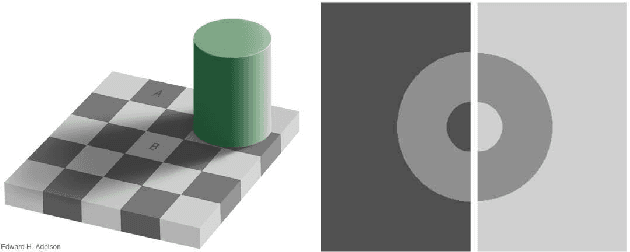
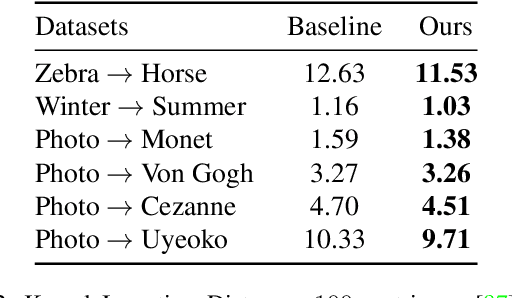
In applications such as optical see-through and projector augmented reality, producing images amounts to solving non-negative image generation, where one can only add light to an existing image. Most image generation methods, however, are ill-suited to this problem setting, as they make the assumption that one can assign arbitrary color to each pixel. In fact, naive application of existing methods fails even in simple domains such as MNIST digits, since one cannot create darker pixels by adding light. We know, however, that the human visual system can be fooled by optical illusions involving certain spatial configurations of brightness and contrast. Our key insight is that one can leverage this behavior to produce high quality images with negligible artifacts. For example, we can create the illusion of darker patches by brightening surrounding pixels. We propose a novel optimization procedure to produce images that satisfy both semantic and non-negativity constraints. Our approach can incorporate existing state-of-the-art methods, and exhibits strong performance in a variety of tasks including image-to-image translation and style transfer.
Language-driven Semantic Segmentation
Jan 10, 2022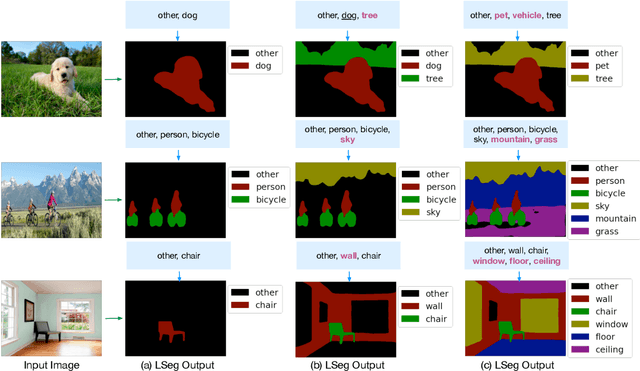
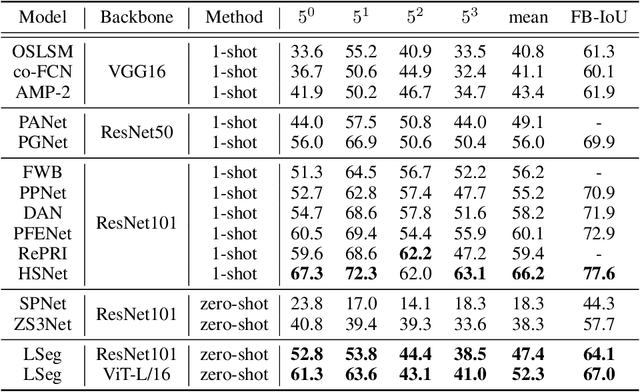
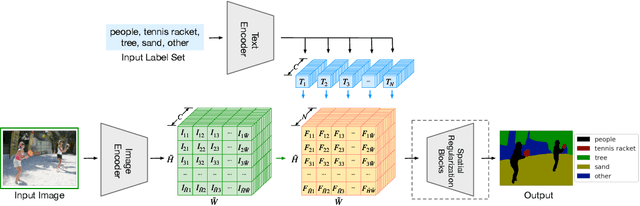
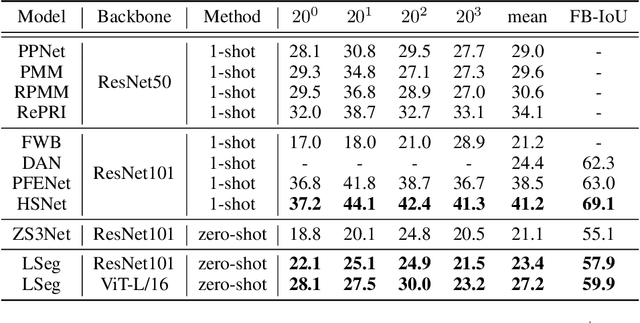
We present LSeg, a novel model for language-driven semantic image segmentation. LSeg uses a text encoder to compute embeddings of descriptive input labels (e.g., "grass" or "building") together with a transformer-based image encoder that computes dense per-pixel embeddings of the input image. The image encoder is trained with a contrastive objective to align pixel embeddings to the text embedding of the corresponding semantic class. The text embeddings provide a flexible label representation in which semantically similar labels map to similar regions in the embedding space (e.g., "cat" and "furry"). This allows LSeg to generalize to previously unseen categories at test time, without retraining or even requiring a single additional training sample. We demonstrate that our approach achieves highly competitive zero-shot performance compared to existing zero- and few-shot semantic segmentation methods, and even matches the accuracy of traditional segmentation algorithms when a fixed label set is provided. Code and demo are available at https://github.com/isl-org/lang-seg.
Rethinking Nearest Neighbors for Visual Classification
Dec 17, 2021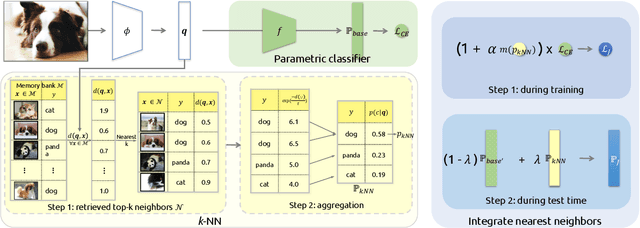
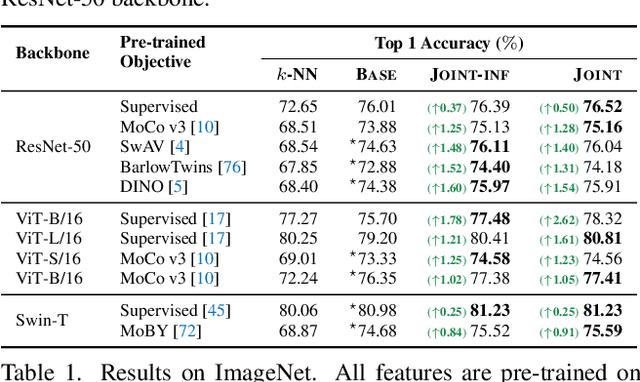
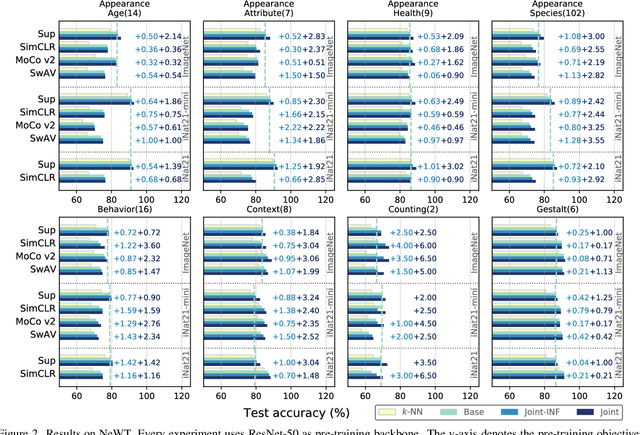
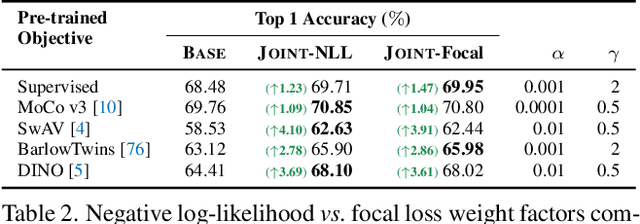
Neural network classifiers have become the de-facto choice for current "pre-train then fine-tune" paradigms of visual classification. In this paper, we investigate k-Nearest-Neighbor (k-NN) classifiers, a classical model-free learning method from the pre-deep learning era, as an augmentation to modern neural network based approaches. As a lazy learning method, k-NN simply aggregates the distance between the test image and top-k neighbors in a training set. We adopt k-NN with pre-trained visual representations produced by either supervised or self-supervised methods in two steps: (1) Leverage k-NN predicted probabilities as indications for easy vs. hard examples during training. (2) Linearly interpolate the k-NN predicted distribution with that of the augmented classifier. Via extensive experiments on a wide range of classification tasks, our study reveals the generality and flexibility of k-NN integration with additional insights: (1) k-NN achieves competitive results, sometimes even outperforming a standard linear classifier. (2) Incorporating k-NN is especially beneficial for tasks where parametric classifiers perform poorly and / or in low-data regimes. We hope these discoveries will encourage people to rethink the role of pre-deep learning, classical methods in computer vision. Our code is available at: https://github.com/KMnP/nn-revisit.
Exploring Temporal Granularity in Self-Supervised Video Representation Learning
Dec 08, 2021



This work presents a self-supervised learning framework named TeG to explore Temporal Granularity in learning video representations. In TeG, we sample a long clip from a video and a short clip that lies inside the long clip. We then extract their dense temporal embeddings. The training objective consists of two parts: a fine-grained temporal learning objective to maximize the similarity between corresponding temporal embeddings in the short clip and the long clip, and a persistent temporal learning objective to pull together global embeddings of the two clips. Our study reveals the impact of temporal granularity with three major findings. 1) Different video tasks may require features of different temporal granularities. 2) Intriguingly, some tasks that are widely considered to require temporal awareness can actually be well addressed by temporally persistent features. 3) The flexibility of TeG gives rise to state-of-the-art results on 8 video benchmarks, outperforming supervised pre-training in most cases.
Unsupervised Domain Adaptation: A Reality Check
Nov 30, 2021
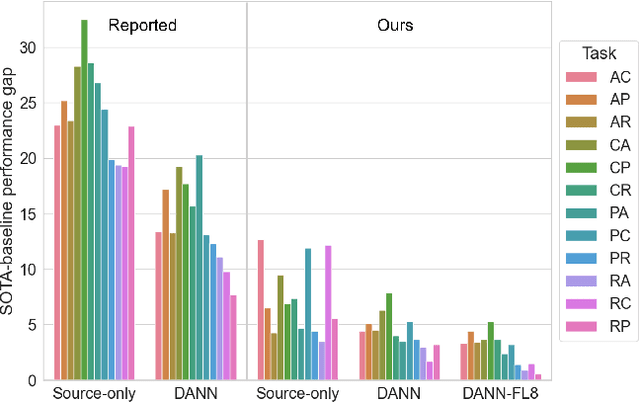
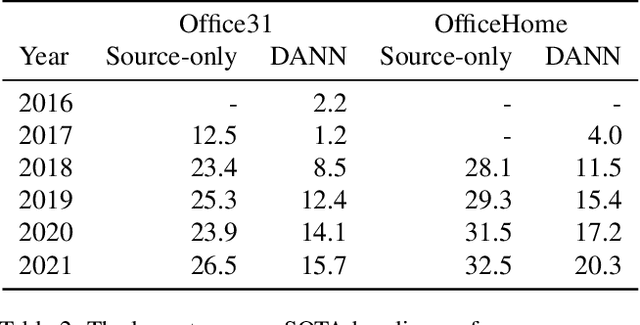
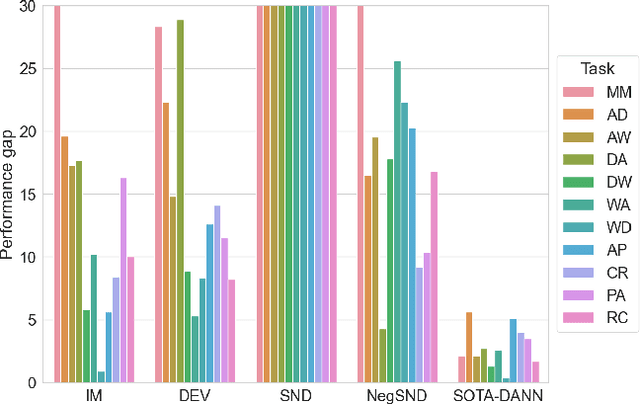
Interest in unsupervised domain adaptation (UDA) has surged in recent years, resulting in a plethora of new algorithms. However, as is often the case in fast-moving fields, baseline algorithms are not tested to the extent that they should be. Furthermore, little attention has been paid to validation methods, i.e. the methods for estimating the accuracy of a model in the absence of target domain labels. This is despite the fact that validation methods are a crucial component of any UDA train/val pipeline. In this paper, we show via large-scale experimentation that 1) in the oracle setting, the difference in accuracy between UDA algorithms is smaller than previously thought, 2) state-of-the-art validation methods are not well-correlated with accuracy, and 3) differences between UDA algorithms are dwarfed by the drop in accuracy caused by validation methods.
Fine-Grained Image Analysis with Deep Learning: A Survey
Nov 19, 2021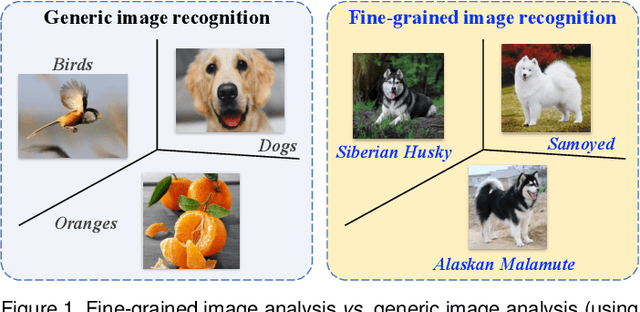
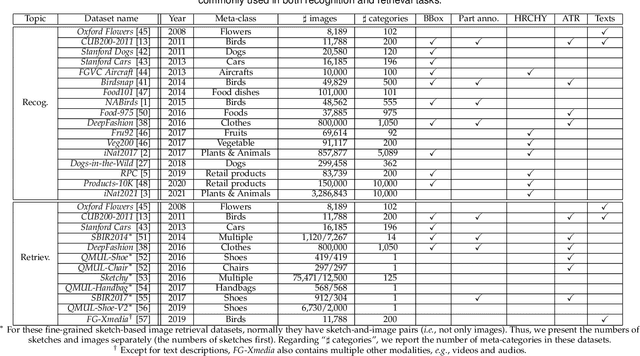
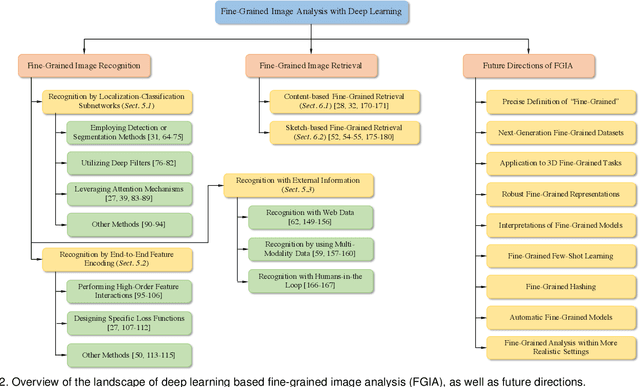
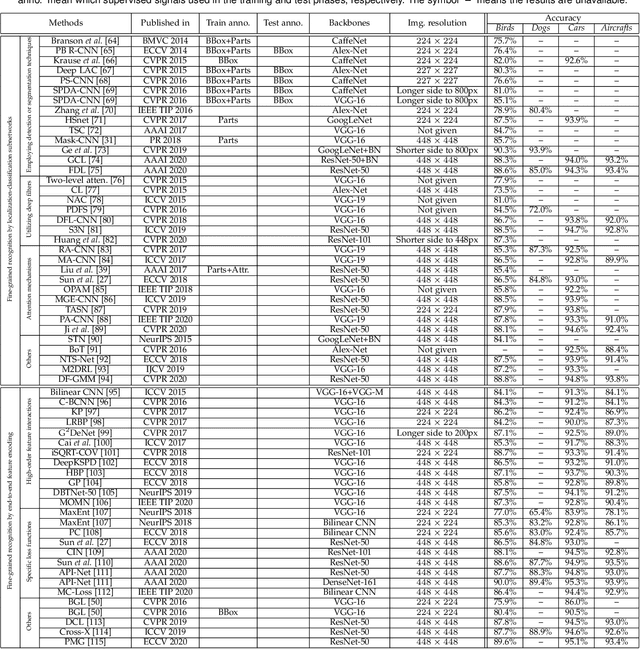
Fine-grained image analysis (FGIA) is a longstanding and fundamental problem in computer vision and pattern recognition, and underpins a diverse set of real-world applications. The task of FGIA targets analyzing visual objects from subordinate categories, e.g., species of birds or models of cars. The small inter-class and large intra-class variation inherent to fine-grained image analysis makes it a challenging problem. Capitalizing on advances in deep learning, in recent years we have witnessed remarkable progress in deep learning powered FGIA. In this paper we present a systematic survey of these advances, where we attempt to re-define and broaden the field of FGIA by consolidating two fundamental fine-grained research areas -- fine-grained image recognition and fine-grained image retrieval. In addition, we also review other key issues of FGIA, such as publicly available benchmark datasets and related domain-specific applications. We conclude by highlighting several research directions and open problems which need further exploration from the community.
Occluded Video Instance Segmentation: Dataset and ICCV 2021 Challenge
Nov 15, 2021


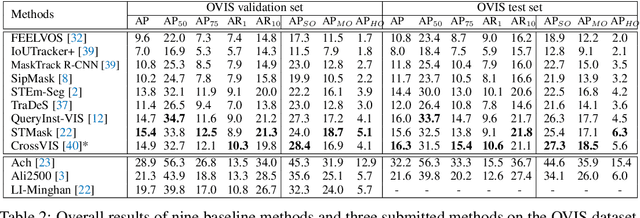
Although deep learning methods have achieved advanced video object recognition performance in recent years, perceiving heavily occluded objects in a video is still a very challenging task. To promote the development of occlusion understanding, we collect a large-scale dataset called OVIS for video instance segmentation in the occluded scenario. OVIS consists of 296k high-quality instance masks and 901 occluded scenes. While our human vision systems can perceive those occluded objects by contextual reasoning and association, our experiments suggest that current video understanding systems cannot. On the OVIS dataset, all baseline methods encounter a significant performance degradation of about 80% in the heavily occluded object group, which demonstrates that there is still a long way to go in understanding obscured objects and videos in a complex real-world scenario. To facilitate the research on new paradigms for video understanding systems, we launched a challenge based on the OVIS dataset. The submitted top-performing algorithms have achieved much higher performance than our baselines. In this paper, we will introduce the OVIS dataset and further dissect it by analyzing the results of baselines and submitted methods. The OVIS dataset and challenge information can be found at http://songbai.site/ovis .
Robustness and Generalization via Generative Adversarial Training
Sep 06, 2021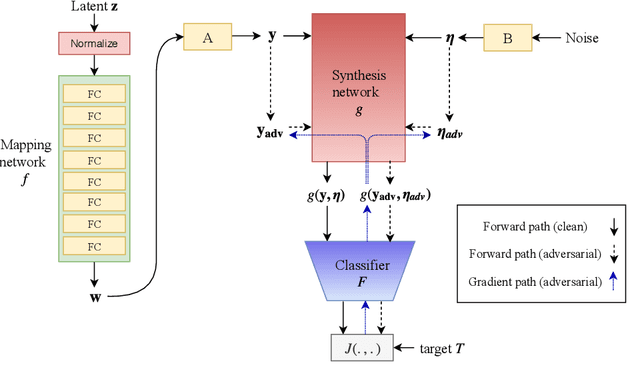

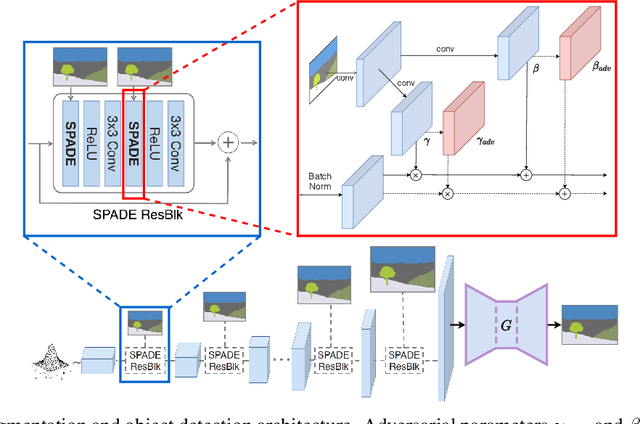
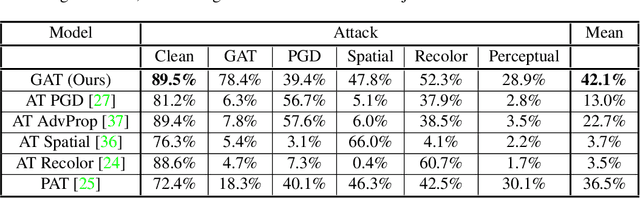
While deep neural networks have achieved remarkable success in various computer vision tasks, they often fail to generalize to new domains and subtle variations of input images. Several defenses have been proposed to improve the robustness against these variations. However, current defenses can only withstand the specific attack used in training, and the models often remain vulnerable to other input variations. Moreover, these methods often degrade performance of the model on clean images and do not generalize to out-of-domain samples. In this paper we present Generative Adversarial Training, an approach to simultaneously improve the model's generalization to the test set and out-of-domain samples as well as its robustness to unseen adversarial attacks. Instead of altering a low-level pre-defined aspect of images, we generate a spectrum of low-level, mid-level and high-level changes using generative models with a disentangled latent space. Adversarial training with these examples enable the model to withstand a wide range of attacks by observing a variety of input alterations during training. We show that our approach not only improves performance of the model on clean images and out-of-domain samples but also makes it robust against unforeseen attacks and outperforms prior work. We validate effectiveness of our method by demonstrating results on various tasks such as classification, segmentation and object detection.