 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Robotic Endoscope Control based on Semantically Rich Instructions
Jul 05, 2021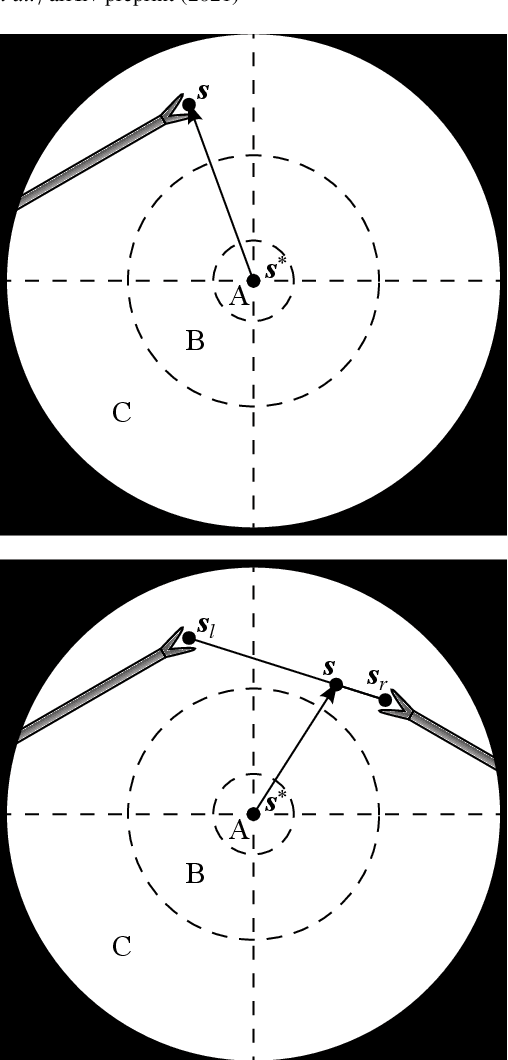
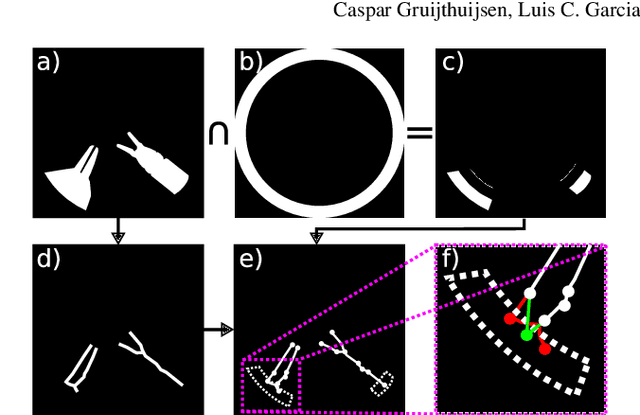
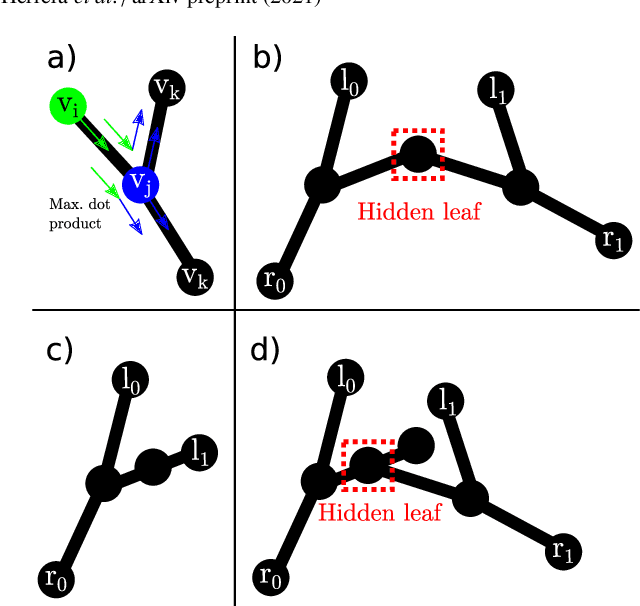
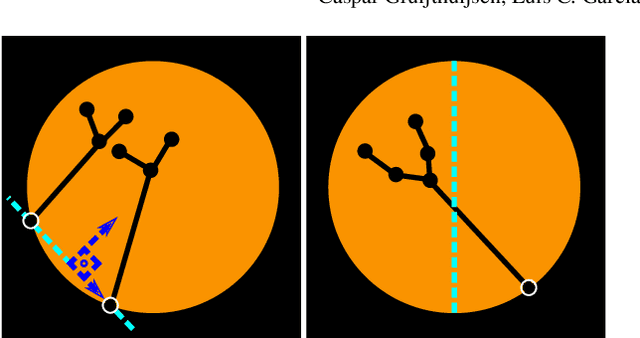
In keyhole interventions, surgeons rely on a colleague to act as a camera assistant when their hands are occupied with surgical instruments. This often leads to reduced image stability, increased task completion times and sometimes errors. Robotic endoscope holders (REHs), controlled by a set of basic instructions, have been proposed as an alternative, but their unnatural handling increases the cognitive load of the surgeon, hindering their widespread clinical acceptance. We propose that REHs collaborate with the operating surgeon via semantically rich instructions that closely resemble those issued to a human camera assistant, such as "focus on my right-hand instrument". As a proof-of-concept, we present a novel system that paves the way towards a synergistic interaction between surgeons and REHs. The proposed platform allows the surgeon to perform a bi-manual coordination and navigation task, while a robotic arm autonomously performs various endoscope positioning tasks. Within our system, we propose a novel tooltip localization method based on surgical tool segmentation, and a novel visual servoing approach that ensures smooth and correct motion of the endoscope camera. We validate our vision pipeline and run a user study of this system. Through successful application in a medically proven bi-manual coordination and navigation task, the framework has shown to be a promising starting point towards broader clinical adoption of REHs.
Inter Extreme Points Geodesics for Weakly Supervised Segmentation
Jul 01, 2021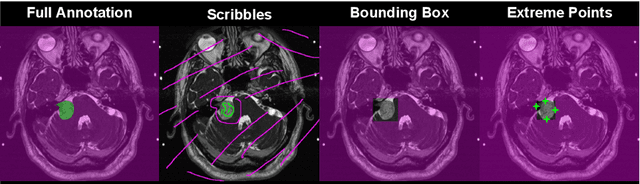
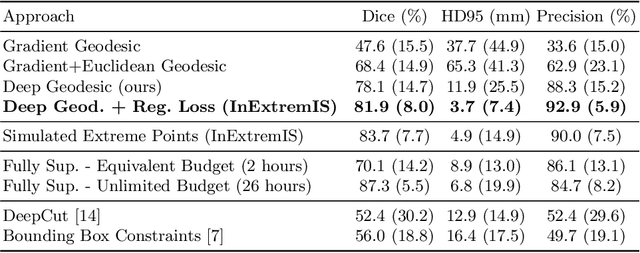
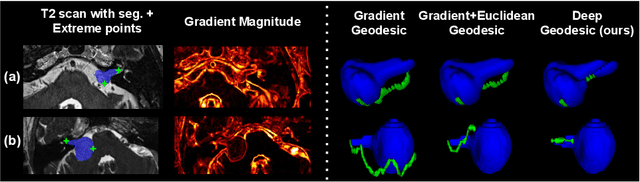
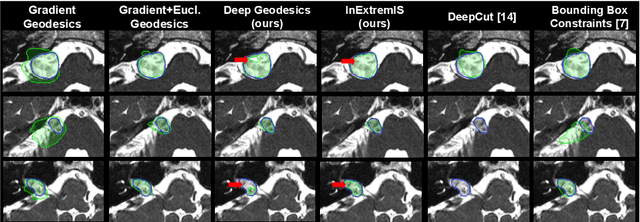
We introduce $\textit{InExtremIS}$, a weakly supervised 3D approach to train a deep image segmentation network using particularly weak train-time annotations: only 6 extreme clicks at the boundary of the objects of interest. Our fully-automatic method is trained end-to-end and does not require any test-time annotations. From the extreme points, 3D bounding boxes are extracted around objects of interest. Then, deep geodesics connecting extreme points are generated to increase the amount of "annotated" voxels within the bounding boxes. Finally, a weakly supervised regularised loss derived from a Conditional Random Field formulation is used to encourage prediction consistency over homogeneous regions. Extensive experiments are performed on a large open dataset for Vestibular Schwannoma segmentation. $\textit{InExtremIS}$ obtained competitive performance, approaching full supervision and outperforming significantly other weakly supervised techniques based on bounding boxes. Moreover, given a fixed annotation time budget, $\textit{InExtremIS}$ outperforms full supervision. Our code and data are available online.
Estimating MRI Image Quality via Image Reconstruction Uncertainty
Jun 21, 2021
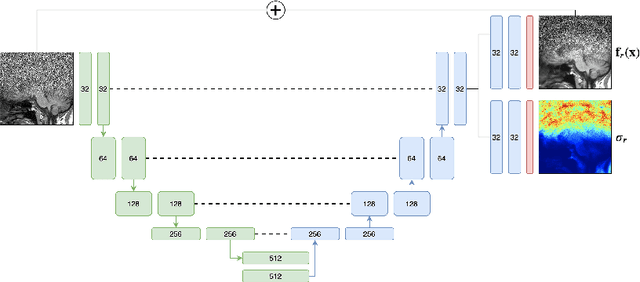
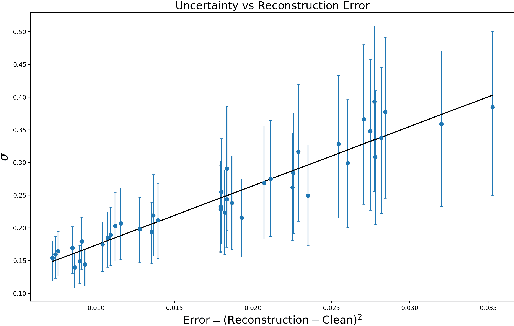
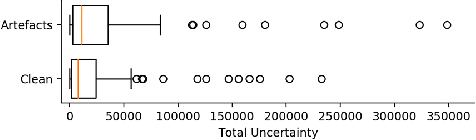
Quality control (QC) in medical image analysis is time-consuming and laborious, leading to increased interest in automated methods. However, what is deemed suitable quality for algorithmic processing may be different from human-perceived measures of visual quality. In this work, we pose MR image quality assessment from an image reconstruction perspective. We train Bayesian CNNs using a heteroscedastic uncertainty model to recover clean images from noisy data, providing measures of uncertainty over the predictions. This framework enables us to divide data corruption into learnable and non-learnable components and leads us to interpret the predictive uncertainty as an estimation of the achievable recovery of an image. Thus, we argue that quality control for visual assessment cannot be equated to quality control for algorithmic processing. We validate this statement in a multi-task experiment combining artefact recovery with uncertainty prediction and grey matter segmentation. Recognising this distinction between visual and algorithmic quality has the impact that, depending on the downstream task, less data can be excluded based on ``visual quality" reasons alone.
Automated triaging of head MRI examinations using convolutional neural networks
Jun 15, 2021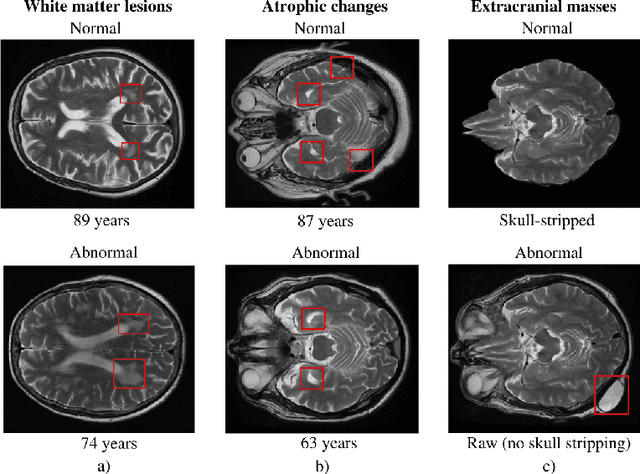
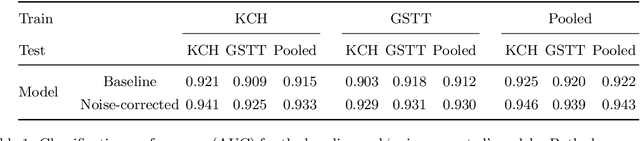
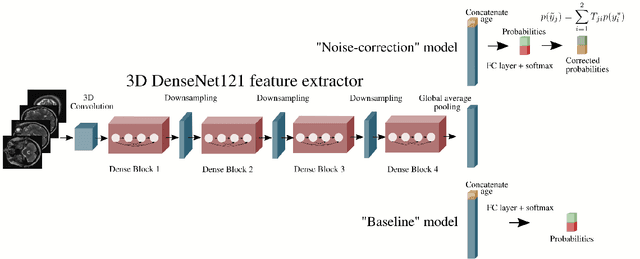
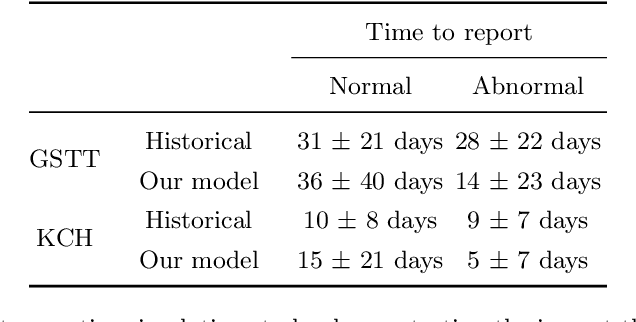
The growing demand for head magnetic resonance imaging (MRI) examinations, along with a global shortage of radiologists, has led to an increase in the time taken to report head MRI scans around the world. For many neurological conditions, this delay can result in increased morbidity and mortality. An automated triaging tool could reduce reporting times for abnormal examinations by identifying abnormalities at the time of imaging and prioritizing the reporting of these scans. In this work, we present a convolutional neural network for detecting clinically-relevant abnormalities in $\text{T}_2$-weighted head MRI scans. Using a validated neuroradiology report classifier, we generated a labelled dataset of 43,754 scans from two large UK hospitals for model training, and demonstrate accurate classification (area under the receiver operating curve (AUC) = 0.943) on a test set of 800 scans labelled by a team of neuroradiologists. Importantly, when trained on scans from only a single hospital the model generalized to scans from the other hospital ($\Delta$AUC $\leq$ 0.02). A simulation study demonstrated that our model would reduce the mean reporting time for abnormal examinations from 28 days to 14 days and from 9 days to 5 days at the two hospitals, demonstrating feasibility for use in a clinical triage environment.
The Medical Segmentation Decathlon
Jun 10, 2021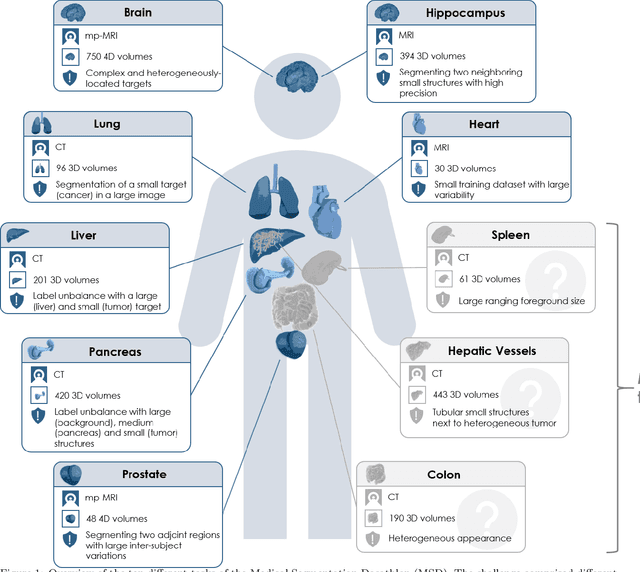
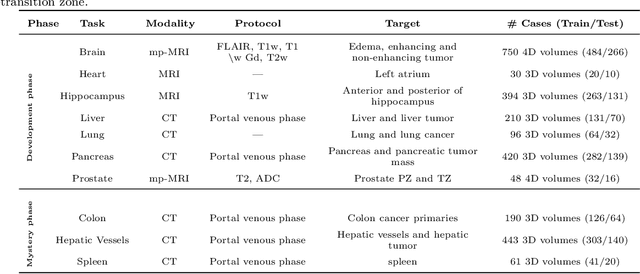
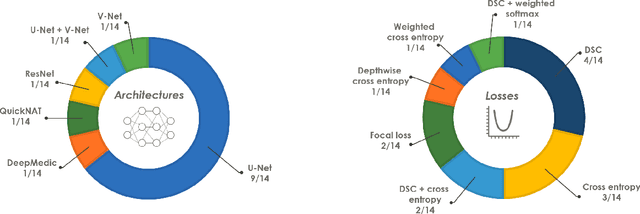
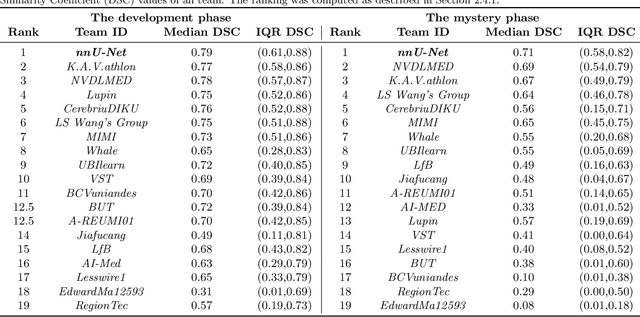
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
MIDeepSeg: Minimally Interactive Segmentation of Unseen Objects from Medical Images Using Deep Learning
Apr 25, 2021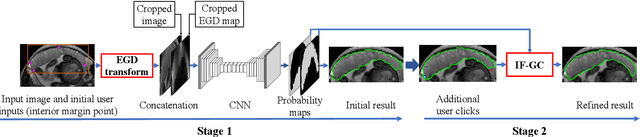
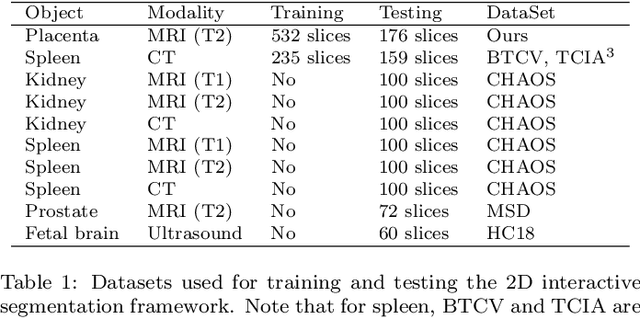
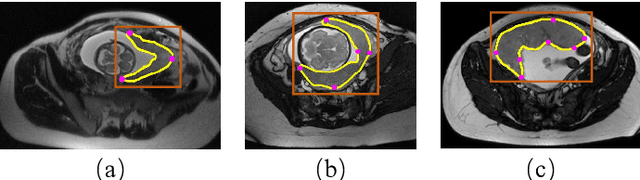
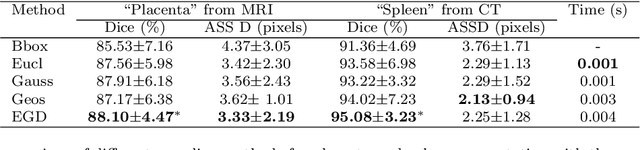
Segmentation of organs or lesions from medical images plays an essential role in many clinical applications such as diagnosis and treatment planning. Though Convolutional Neural Networks (CNN) have achieved the state-of-the-art performance for automatic segmentation, they are often limited by the lack of clinically acceptable accuracy and robustness in complex cases. Therefore, interactive segmentation is a practical alternative to these methods. However, traditional interactive segmentation methods require a large amount of user interactions, and recently proposed CNN-based interactive segmentation methods are limited by poor performance on previously unseen objects. To solve these problems, we propose a novel deep learning-based interactive segmentation method that not only has high efficiency due to only requiring clicks as user inputs but also generalizes well to a range of previously unseen objects. Specifically, we first encode user-provided interior margin points via our proposed exponentialized geodesic distance that enables a CNN to achieve a good initial segmentation result of both previously seen and unseen objects, then we use a novel information fusion method that combines the initial segmentation with only few additional user clicks to efficiently obtain a refined segmentation. We validated our proposed framework through extensive experiments on 2D and 3D medical image segmentation tasks with a wide range of previous unseen objects that were not present in the training set. Experimental results showed that our proposed framework 1) achieves accurate results with fewer user interactions and less time compared with state-of-the-art interactive frameworks and 2) generalizes well to previously unseen objects.
Machine Learning and Glioblastoma: Treatment Response Monitoring Biomarkers in 2021
Apr 15, 2021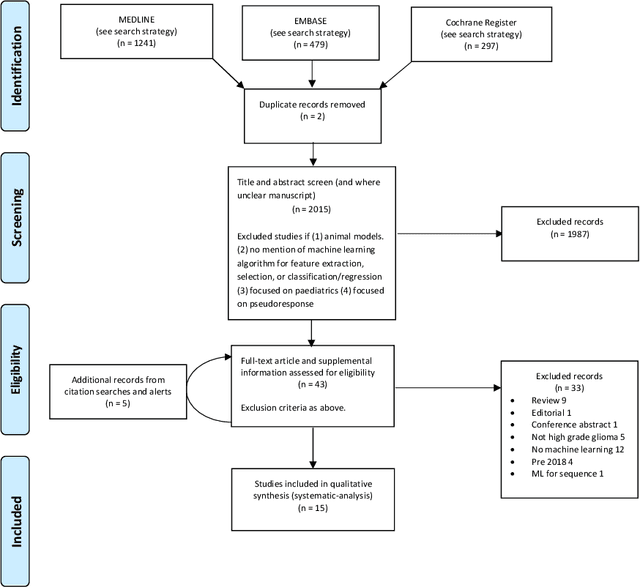
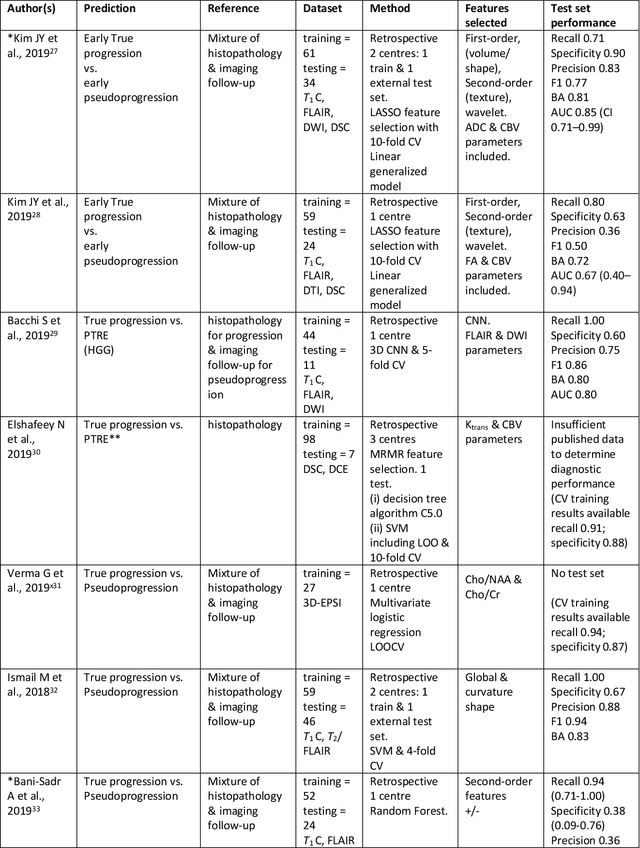
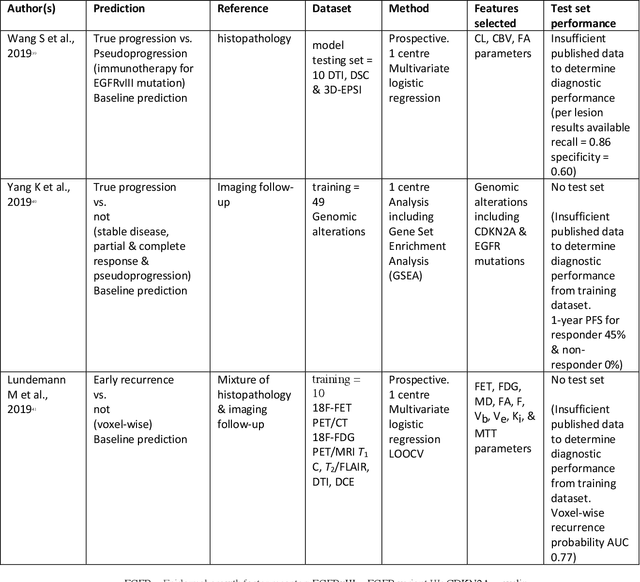
The aim of the systematic review was to assess recently published studies on diagnostic test accuracy of glioblastoma treatment response monitoring biomarkers in adults, developed through machine learning (ML). Articles were searched for using MEDLINE, EMBASE, and the Cochrane Register. Included study participants were adult patients with high grade glioma who had undergone standard treatment (maximal resection, radiotherapy with concomitant and adjuvant temozolomide) and subsequently underwent follow-up imaging to determine treatment response status. Risk of bias and applicability was assessed with QUADAS 2 methodology. Contingency tables were created for hold-out test sets and recall, specificity, precision, F1-score, balanced accuracy calculated. Fifteen studies were included with 1038 patients in training sets and 233 in test sets. To determine whether there was progression or a mimic, the reference standard combination of follow-up imaging and histopathology at re-operation was applied in 67% of studies. The small numbers of patient included in studies, the high risk of bias and concerns of applicability in the study designs (particularly in relation to the reference standard and patient selection due to confounding), and the low level of evidence, suggest that limited conclusions can be drawn from the data. There is likely good diagnostic performance of machine learning models that use MRI features to distinguish between progression and mimics. The diagnostic performance of ML using implicit features did not appear to be superior to ML using explicit features. There are a range of ML-based solutions poised to become treatment response monitoring biomarkers for glioblastoma. To achieve this, the development and validation of ML models require large, well-annotated datasets where the potential for confounding in the study design has been carefully considered.
Unsupervised Brain Anomaly Detection and Segmentation with Transformers
Feb 23, 2021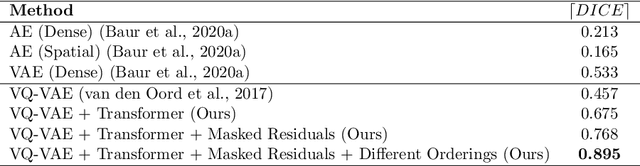
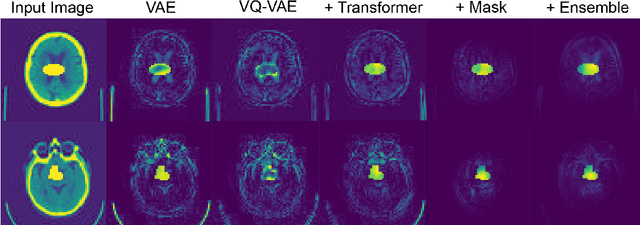
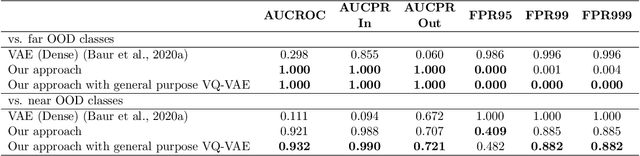
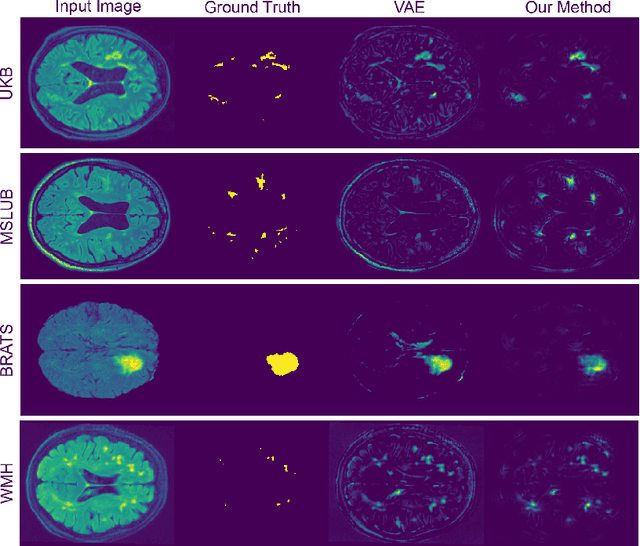
Pathological brain appearances may be so heterogeneous as to be intelligible only as anomalies, defined by their deviation from normality rather than any specific pathological characteristic. Amongst the hardest tasks in medical imaging, detecting such anomalies requires models of the normal brain that combine compactness with the expressivity of the complex, long-range interactions that characterise its structural organisation. These are requirements transformers have arguably greater potential to satisfy than other current candidate architectures, but their application has been inhibited by their demands on data and computational resource. Here we combine the latent representation of vector quantised variational autoencoders with an ensemble of autoregressive transformers to enable unsupervised anomaly detection and segmentation defined by deviation from healthy brain imaging data, achievable at low computational cost, within relative modest data regimes. We compare our method to current state-of-the-art approaches across a series of experiments involving synthetic and real pathological lesions. On real lesions, we train our models on 15,000 radiologically normal participants from UK Biobank, and evaluate performance on four different brain MR datasets with small vessel disease, demyelinating lesions, and tumours. We demonstrate superior anomaly detection performance both image-wise and pixel-wise, achievable without post-processing. These results draw attention to the potential of transformers in this most challenging of imaging tasks.
Intrapapillary Capillary Loop Classification in Magnification Endoscopy: Open Dataset and Baseline Methodology
Feb 19, 2021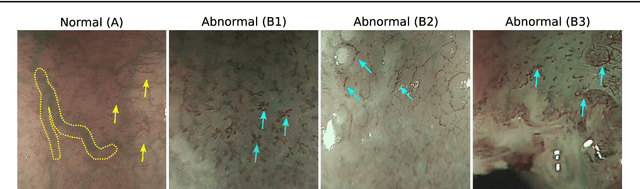
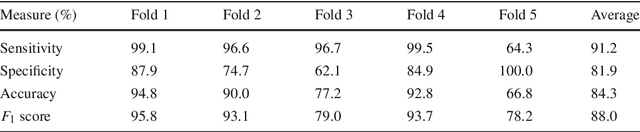
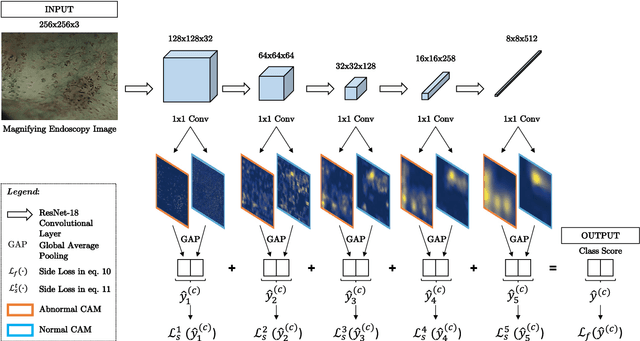
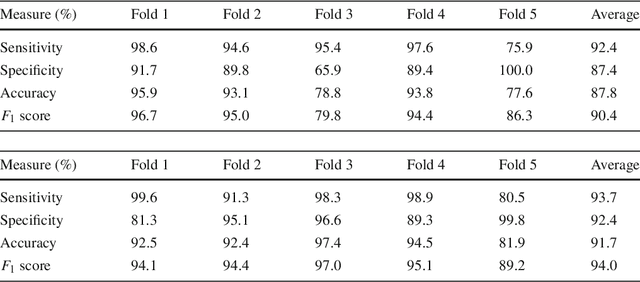
Purpose. Early squamous cell neoplasia (ESCN) in the oesophagus is a highly treatable condition. Lesions confined to the mucosal layer can be curatively treated endoscopically. We build a computer-assisted detection (CADe) system that can classify still images or video frames as normal or abnormal with high diagnostic accuracy. Methods. We present a new benchmark dataset containing 68K binary labeled frames extracted from 114 patient videos whose imaged areas have been resected and correlated to histopathology. Our novel convolutional network (CNN) architecture solves the binary classification task and explains what features of the input domain drive the decision-making process of the network. Results. The proposed method achieved an average accuracy of 91.7 % compared to the 94.7 % achieved by a group of 12 senior clinicians. Our novel network architecture produces deeply supervised activation heatmaps that suggest the network is looking at intrapapillary capillary loop (IPCL) patterns when predicting abnormality. Conclusion. We believe that this dataset and baseline method may serve as a reference for future benchmarks on both video frame classification and explainability in the context of ESCN detection. A future work path of high clinical relevance is the extension of the classification to ESCN types.
Image Compositing for Segmentation of Surgical Tools without Manual Annotations
Feb 18, 2021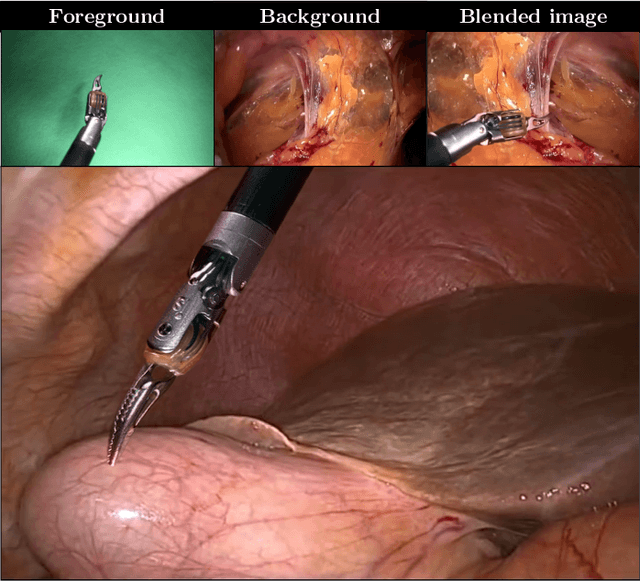
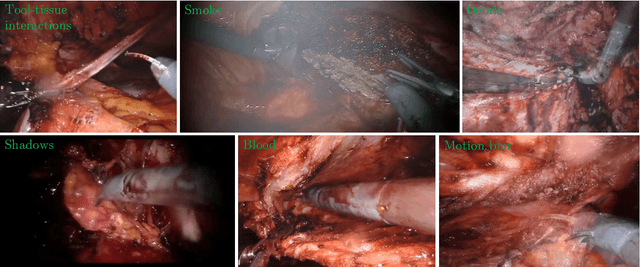
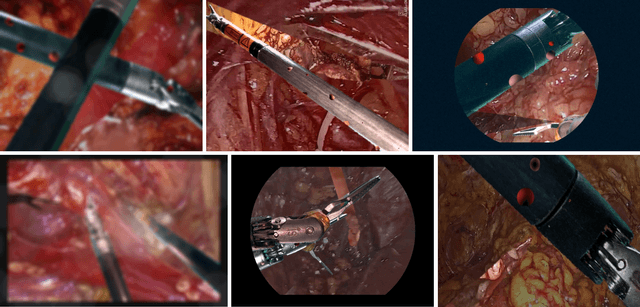
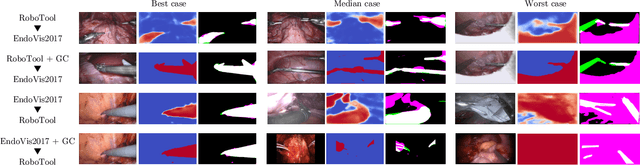
Producing manual, pixel-accurate, image segmentation labels is tedious and time-consuming. This is often a rate-limiting factor when large amounts of labeled images are required, such as for training deep convolutional networks for instrument-background segmentation in surgical scenes. No large datasets comparable to industry standards in the computer vision community are available for this task. To circumvent this problem, we propose to automate the creation of a realistic training dataset by exploiting techniques stemming from special effects and harnessing them to target training performance rather than visual appeal. Foreground data is captured by placing sample surgical instruments over a chroma key (a.k.a. green screen) in a controlled environment, thereby making extraction of the relevant image segment straightforward. Multiple lighting conditions and viewpoints can be captured and introduced in the simulation by moving the instruments and camera and modulating the light source. Background data is captured by collecting videos that do not contain instruments. In the absence of pre-existing instrument-free background videos, minimal labeling effort is required, just to select frames that do not contain surgical instruments from videos of surgical interventions freely available online. We compare different methods to blend instruments over tissue and propose a novel data augmentation approach that takes advantage of the plurality of options. We show that by training a vanilla U-Net on semi-synthetic data only and applying a simple post-processing, we are able to match the results of the same network trained on a publicly available manually labeled real dataset.