 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond one-hot encoding? Journey into compact encoding for large multi-class segmentation
Oct 01, 2025This work presents novel methods to reduce computational and memory requirements for medical image segmentation with a large number of classes. We curiously observe challenges in maintaining state-of-the-art segmentation performance with all of the explored options. Standard learning-based methods typically employ one-hot encoding of class labels. The computational complexity and memory requirements thus increase linearly with the number of classes. We propose a family of binary encoding approaches instead of one-hot encoding to reduce the computational complexity and memory requirements to logarithmic in the number of classes. In addition to vanilla binary encoding, we investigate the effects of error-correcting output codes (ECOCs), class weighting, hard/soft decoding, class-to-codeword assignment, and label embedding trees. We apply the methods to the use case of whole brain parcellation with 108 classes based on 3D MRI images. While binary encodings have proven efficient in so-called extreme classification problems in computer vision, we faced challenges in reaching state-of-the-art segmentation quality with binary encodings. Compared to one-hot encoding (Dice Similarity Coefficient (DSC) = 82.4 (2.8)), we report reduced segmentation performance with the binary segmentation approaches, achieving DSCs in the range from 39.3 to 73.8. Informative negative results all too often go unpublished. We hope that this work inspires future research of compact encoding strategies for large multi-class segmentation tasks.
crossMoDA Challenge: Evolution of Cross-Modality Domain Adaptation Techniques for Vestibular Schwannoma and Cochlea Segmentation from 2021 to 2023
Jun 13, 2025The cross-Modality Domain Adaptation (crossMoDA) challenge series, initiated in 2021 in conjunction with the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), focuses on unsupervised cross-modality segmentation, learning from contrast-enhanced T1 (ceT1) and transferring to T2 MRI. The task is an extreme example of domain shift chosen to serve as a meaningful and illustrative benchmark. From a clinical application perspective, it aims to automate Vestibular Schwannoma (VS) and cochlea segmentation on T2 scans for more cost-effective VS management. Over time, the challenge objectives have evolved to enhance its clinical relevance. The challenge evolved from using single-institutional data and basic segmentation in 2021 to incorporating multi-institutional data and Koos grading in 2022, and by 2023, it included heterogeneous routine data and sub-segmentation of intra- and extra-meatal tumour components. In this work, we report the findings of the 2022 and 2023 editions and perform a retrospective analysis of the challenge progression over the years. The observations from the successive challenge contributions indicate that the number of outliers decreases with an expanding dataset. This is notable since the diversity of scanning protocols of the datasets concurrently increased. The winning approach of the 2023 edition reduced the number of outliers on the 2021 and 2022 testing data, demonstrating how increased data heterogeneity can enhance segmentation performance even on homogeneous data. However, the cochlea Dice score declined in 2023, likely due to the added complexity from tumour sub-annotations affecting overall segmentation performance. While progress is still needed for clinically acceptable VS segmentation, the plateauing performance suggests that a more challenging cross-modal task may better serve future benchmarking.
A generalisable head MRI defacing pipeline: Evaluation on 2,566 meningioma scans
May 19, 2025Reliable MRI defacing techniques to safeguard patient privacy while preserving brain anatomy are critical for research collaboration. Existing methods often struggle with incomplete defacing or degradation of brain tissue regions. We present a robust, generalisable defacing pipeline for high-resolution MRI that integrates atlas-based registration with brain masking. Our method was evaluated on 2,566 heterogeneous clinical scans for meningioma and achieved a 99.92 per cent success rate (2,564/2,566) upon visual inspection. Excellent anatomical preservation is demonstrated with a Dice similarity coefficient of 0.9975 plus or minus 0.0023 between brain masks automatically extracted from the original and defaced volumes. Source code is available at https://github.com/cai4cai/defacing_pipeline.
Label merge-and-split: A graph-colouring approach for memory-efficient brain parcellation
Apr 16, 2024Whole brain parcellation requires inferring hundreds of segmentation labels in large image volumes and thus presents significant practical challenges for deep learning approaches. We introduce label merge-and-split, a method that first greatly reduces the effective number of labels required for learning-based whole brain parcellation and then recovers original labels. Using a greedy graph colouring algorithm, our method automatically groups and merges multiple spatially separate labels prior to model training and inference. The merged labels may be semantically unrelated. A deep learning model is trained to predict merged labels. At inference time, original labels are restored using atlas-based influence regions. In our experiments, the proposed approach reduces the number of labels by up to 68% while achieving segmentation accuracy comparable to the baseline method without label merging and splitting. Moreover, model training and inference times as well as GPU memory requirements were reduced significantly. The proposed method can be applied to all semantic segmentation tasks with a large number of spatially separate classes within an atlas-based prior.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
Boundary Distance Loss for Intra-/Extra-meatal Segmentation of Vestibular Schwannoma
Aug 09, 2022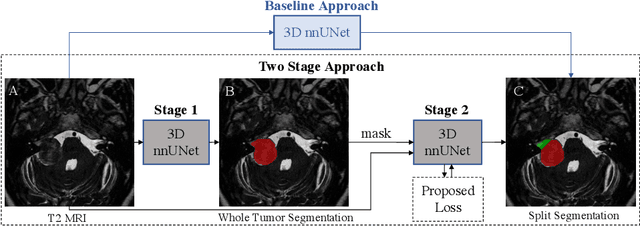
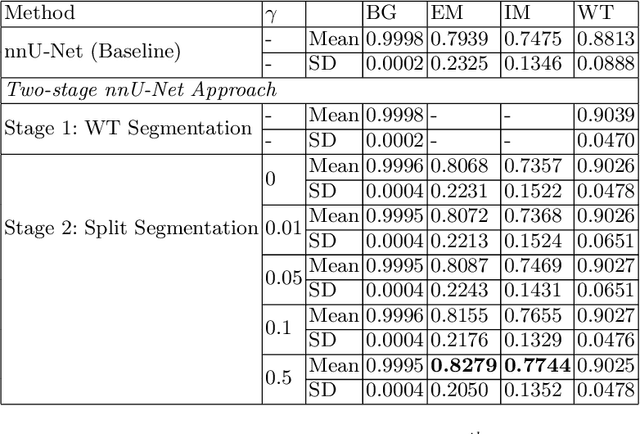
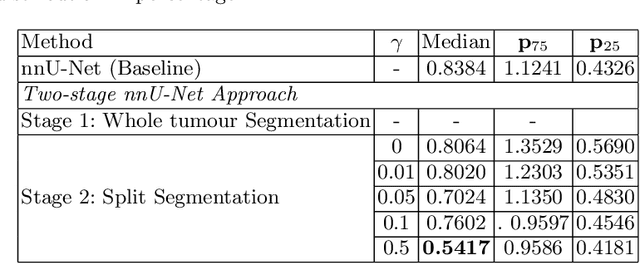
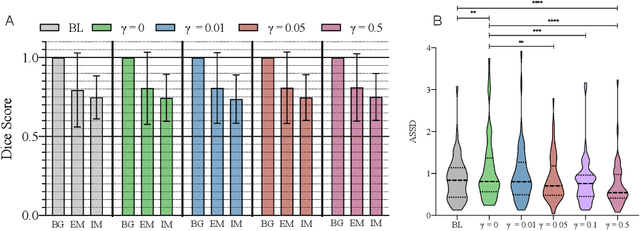
Vestibular Schwannoma (VS) typically grows from the inner ear to the brain. It can be separated into two regions, intrameatal and extrameatal respectively corresponding to being inside or outside the inner ear canal. The growth of the extrameatal regions is a key factor that determines the disease management followed by the clinicians. In this work, a VS segmentation approach with subdivision into intra-/extra-meatal parts is presented. We annotated a dataset consisting of 227 T2 MRI instances, acquired longitudinally on 137 patients, excluding post-operative instances. We propose a staged approach, with the first stage performing the whole tumour segmentation and the second stage performing the intra-/extra-meatal segmentation using the T2 MRI along with the mask obtained from the first stage. To improve on the accuracy of the predicted meatal boundary, we introduce a task-specific loss which we call Boundary Distance Loss. The performance is evaluated in contrast to the direct intrameatal extrameatal segmentation task performance, i.e. the Baseline. Our proposed method, with the two-stage approach and the Boundary Distance Loss, achieved a Dice score of 0.8279+-0.2050 and 0.7744+-0.1352 for extrameatal and intrameatal regions respectively, significantly improving over the Baseline, which gave Dice score of 0.7939+-0.2325 and 0.7475+-0.1346 for the extrameatal and intrameatal regions respectively.
CrossMoDA 2021 challenge: Benchmark of Cross-Modality Domain Adaptation techniques for Vestibular Schwnannoma and Cochlea Segmentation
Jan 08, 2022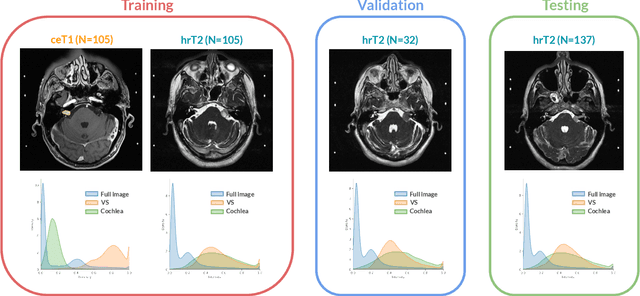
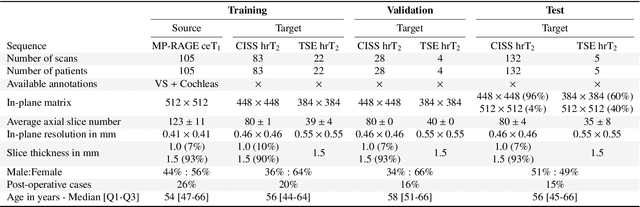
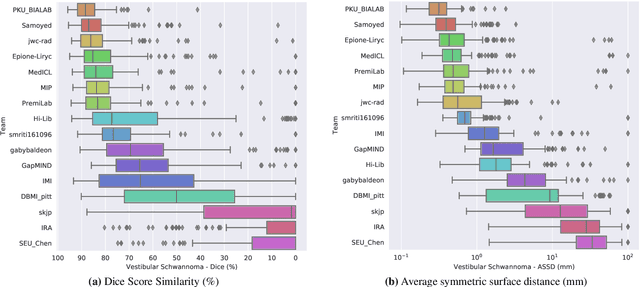
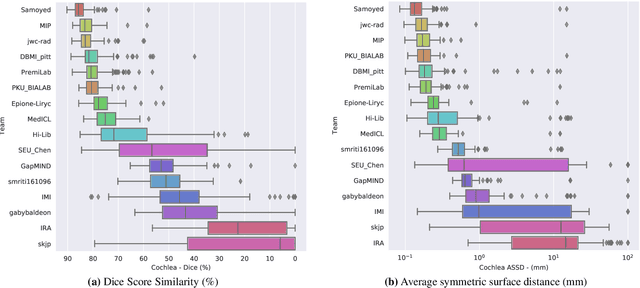
Domain Adaptation (DA) has recently raised strong interests in the medical imaging community. While a large variety of DA techniques has been proposed for image segmentation, most of these techniques have been validated either on private datasets or on small publicly available datasets. Moreover, these datasets mostly addressed single-class problems. To tackle these limitations, the Cross-Modality Domain Adaptation (crossMoDA) challenge was organised in conjunction with the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2021). CrossMoDA is the first large and multi-class benchmark for unsupervised cross-modality DA. The challenge's goal is to segment two key brain structures involved in the follow-up and treatment planning of vestibular schwannoma (VS): the VS and the cochleas. Currently, the diagnosis and surveillance in patients with VS are performed using contrast-enhanced T1 (ceT1) MRI. However, there is growing interest in using non-contrast sequences such as high-resolution T2 (hrT2) MRI. Therefore, we created an unsupervised cross-modality segmentation benchmark. The training set provides annotated ceT1 (N=105) and unpaired non-annotated hrT2 (N=105). The aim was to automatically perform unilateral VS and bilateral cochlea segmentation on hrT2 as provided in the testing set (N=137). A total of 16 teams submitted their algorithm for the evaluation phase. The level of performance reached by the top-performing teams is strikingly high (best median Dice - VS:88.4%; Cochleas:85.7%) and close to full supervision (median Dice - VS:92.5%; Cochleas:87.7%). All top-performing methods made use of an image-to-image translation approach to transform the source-domain images into pseudo-target-domain images. A segmentation network was then trained using these generated images and the manual annotations provided for the source image.
Inter Extreme Points Geodesics for Weakly Supervised Segmentation
Jul 01, 2021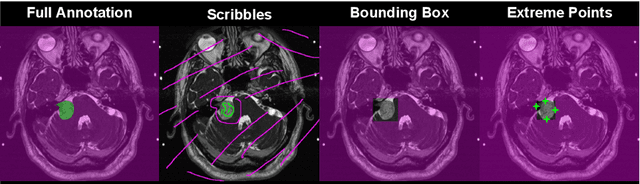
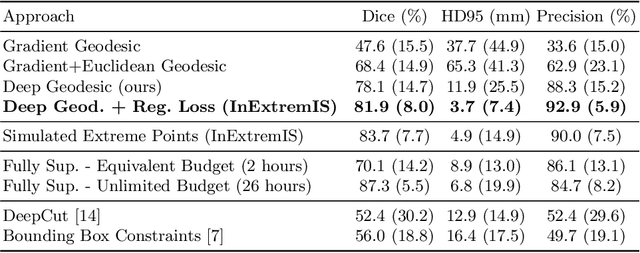
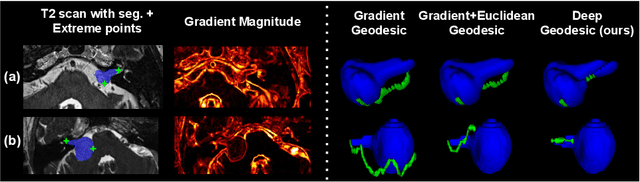
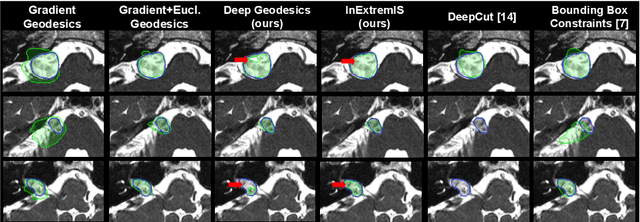
We introduce $\textit{InExtremIS}$, a weakly supervised 3D approach to train a deep image segmentation network using particularly weak train-time annotations: only 6 extreme clicks at the boundary of the objects of interest. Our fully-automatic method is trained end-to-end and does not require any test-time annotations. From the extreme points, 3D bounding boxes are extracted around objects of interest. Then, deep geodesics connecting extreme points are generated to increase the amount of "annotated" voxels within the bounding boxes. Finally, a weakly supervised regularised loss derived from a Conditional Random Field formulation is used to encourage prediction consistency over homogeneous regions. Extensive experiments are performed on a large open dataset for Vestibular Schwannoma segmentation. $\textit{InExtremIS}$ obtained competitive performance, approaching full supervision and outperforming significantly other weakly supervised techniques based on bounding boxes. Moreover, given a fixed annotation time budget, $\textit{InExtremIS}$ outperforms full supervision. Our code and data are available online.