 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlying Calligrapher: Contact-Aware Motion and Force Planning and Control for Aerial Manipulation
Jul 08, 2024



Aerial manipulation has gained interest in completing high-altitude tasks that are challenging for human workers, such as contact inspection and defect detection, etc. Previous research has focused on maintaining static contact points or forces. This letter addresses a more general and dynamic task: simultaneously tracking time-varying contact force in the surface normal direction and motion trajectories on tangential surfaces. We propose a pipeline that includes a contact-aware trajectory planner to generate dynamically feasible trajectories, and a hybrid motion-force controller to track such trajectories. We demonstrate the approach in an aerial calligraphy task using a novel sponge pen design as the end-effector, whose stroke width is proportional to the contact force. Additionally, we develop a touchscreen interface for flexible user input. Experiments show our method can effectively draw diverse letters, achieving an IoU of 0.59 and an end-effector position (force) tracking RMSE of 2.9 cm (0.7 N). Website: https://xiaofeng-guo.github.io/flying-calligrapher/
Informative Sensor Planning for a Single-Axis Gimbaled Camera on a Fixed-Wing UAV
Jul 06, 2024Uncrewed Aerial Vehicles (UAVs) are a leading choice of platforms for a variety of information-gathering applications. Sensor planning can enhance the efficiency and success of these types of missions when coupled with a higher-level informative path-planning algorithm. This paper aims to address these data acquisition challenges by developing an informative non-myopic sensor planning framework for a single-axis gimbal coupled with an informative path planner to maximize information gain over a prior information map. This is done by finding reduced sensor sweep bounds over a planning horizon such that regions of higher confidence are prioritized. This novel sensor planning framework is evaluated against a predefined sensor sweep and no sensor planning baselines as well as validated in two simulation environments. In our results, we observe an improvement in the performance by 21.88% and 13.34% for the no sensor planning and predefined sensor sweep baselines respectively.
$\textit{UniSaT}$: Unified-Objective Belief Model and Planner to Search for and Track Multiple Objects
May 25, 2024



The problem of path planning for autonomously searching and tracking multiple objects is important to reconnaissance, surveillance, and many other data-gathering applications. Due to the inherent competing objectives of searching for new objects while maintaining tracks for found objects, most current approaches rely on multi-objective planning methods, leaving it up to the user to tune parameters to balance between the two objectives, usually based on heuristics or trial and error. In this paper, we introduce $\textit{UniSaT}$ ($\textit{Unified Search and Track}$), a unified-objective formulation for the search and track problem based on Random Finite Sets (RFS). This is done by modeling both the unknown and known objects through a combined generalized labeled multi-Bernoulli (GLMB) filter. For the unseen objects, we can leverage both cardinality and spatial prior distributions, which means $\textit{UniSaT}$ does not rely on knowing the exact count of the expected number of objects in the space. The planner maximizes the mutual information of this unified belief model, creating balanced search and tracking behaviors. We demonstrate our work in a simulated environment and show both qualitative results as well as quantitative improvements over a multi-objective method.
RuleFuser: Injecting Rules in Evidential Networks for Robust Out-of-Distribution Trajectory Prediction
May 18, 2024



Modern neural trajectory predictors in autonomous driving are developed using imitation learning (IL) from driving logs. Although IL benefits from its ability to glean nuanced and multi-modal human driving behaviors from large datasets, the resulting predictors often struggle with out-of-distribution (OOD) scenarios and with traffic rule compliance. On the other hand, classical rule-based predictors, by design, can predict traffic rule satisfying behaviors while being robust to OOD scenarios, but these predictors fail to capture nuances in agent-to-agent interactions and human driver's intent. In this paper, we present RuleFuser, a posterior-net inspired evidential framework that combines neural predictors with classical rule-based predictors to draw on the complementary benefits of both, thereby striking a balance between performance and traffic rule compliance. The efficacy of our approach is demonstrated on the real-world nuPlan dataset where RuleFuser leverages the higher performance of the neural predictor in in-distribution (ID) scenarios and the higher safety offered by the rule-based predictor in OOD scenarios.
Geometry-Informed Distance Candidate Selection for Adaptive Lightweight Omnidirectional Stereo Vision with Fisheye Images
May 08, 2024Multi-view stereo omnidirectional distance estimation usually needs to build a cost volume with many hypothetical distance candidates. The cost volume building process is often computationally heavy considering the limited resources a mobile robot has. We propose a new geometry-informed way of distance candidates selection method which enables the use of a very small number of candidates and reduces the computational cost. We demonstrate the use of the geometry-informed candidates in a set of model variants. We find that by adjusting the candidates during robot deployment, our geometry-informed distance candidates also improve a pre-trained model's accuracy if the extrinsics or the number of cameras changes. Without any re-training or fine-tuning, our models outperform models trained with evenly distributed distance candidates. Models are also released as hardware-accelerated versions with a new dedicated large-scale dataset. The project page, code, and dataset can be found at https://theairlab.org/gicandidates/ .
General Place Recognition Survey: Towards Real-World Autonomy
May 08, 2024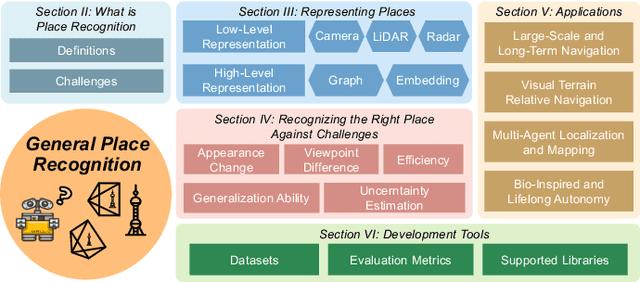
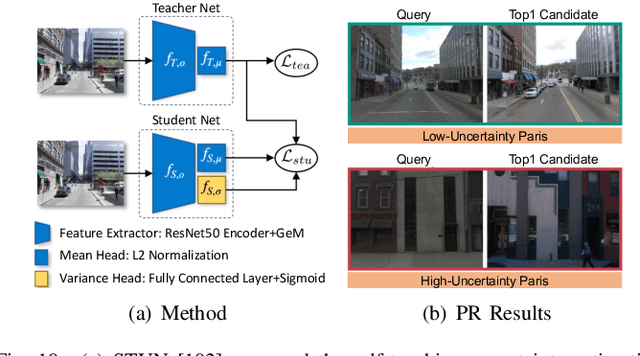
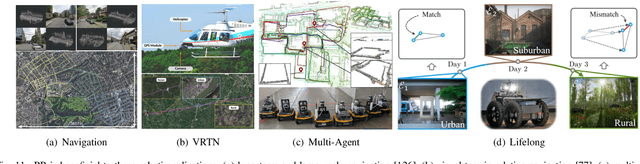
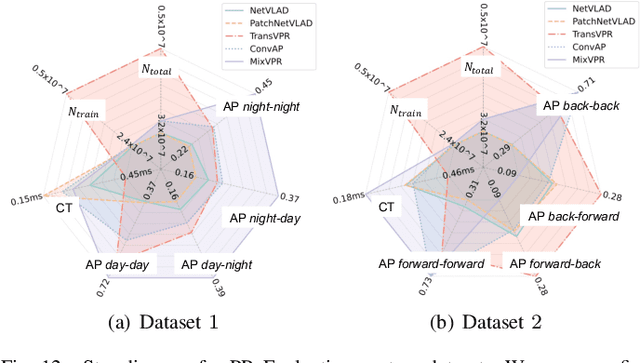
In the realm of robotics, the quest for achieving real-world autonomy, capable of executing large-scale and long-term operations, has positioned place recognition (PR) as a cornerstone technology. Despite the PR community's remarkable strides over the past two decades, garnering attention from fields like computer vision and robotics, the development of PR methods that sufficiently support real-world robotic systems remains a challenge. This paper aims to bridge this gap by highlighting the crucial role of PR within the framework of Simultaneous Localization and Mapping (SLAM) 2.0. This new phase in robotic navigation calls for scalable, adaptable, and efficient PR solutions by integrating advanced artificial intelligence (AI) technologies. For this goal, we provide a comprehensive review of the current state-of-the-art (SOTA) advancements in PR, alongside the remaining challenges, and underscore its broad applications in robotics. This paper begins with an exploration of PR's formulation and key research challenges. We extensively review literature, focusing on related methods on place representation and solutions to various PR challenges. Applications showcasing PR's potential in robotics, key PR datasets, and open-source libraries are discussed. We also emphasizes our open-source package, aimed at new development and benchmark for general PR. We conclude with a discussion on PR's future directions, accompanied by a summary of the literature covered and access to our open-source library, available to the robotics community at: https://github.com/MetaSLAM/GPRS.
AirShot: Efficient Few-Shot Detection for Autonomous Exploration
Apr 07, 2024



Few-shot object detection has drawn increasing attention in the field of robotic exploration, where robots are required to find unseen objects with a few online provided examples. Despite recent efforts have been made to yield online processing capabilities, slow inference speeds of low-powered robots fail to meet the demands of real-time detection-making them impractical for autonomous exploration. Existing methods still face performance and efficiency challenges, mainly due to unreliable features and exhaustive class loops. In this work, we propose a new paradigm AirShot, and discover that, by fully exploiting the valuable correlation map, AirShot can result in a more robust and faster few-shot object detection system, which is more applicable to robotics community. The core module Top Prediction Filter (TPF) can operate on multi-scale correlation maps in both the training and inference stages. During training, TPF supervises the generation of a more representative correlation map, while during inference, it reduces looping iterations by selecting top-ranked classes, thus cutting down on computational costs with better performance. Surprisingly, this dual functionality exhibits general effectiveness and efficiency on various off-the-shelf models. Exhaustive experiments on COCO2017, VOC2014, and SubT datasets demonstrate that TPF can significantly boost the efficacy and efficiency of most off-the-shelf models, achieving up to 36.4% precision improvements along with 56.3% faster inference speed. Code and Data are at: https://github.com/ImNotPrepared/AirShot.
Multi-Robot Planning for Filming Groups of Moving Actors Leveraging Submodularity and Pixel Density
Apr 03, 2024Observing and filming a group of moving actors with a team of aerial robots is a challenging problem that combines elements of multi-robot coordination, coverage, and view planning. A single camera may observe multiple actors at once, and the robot team may observe individual actors from multiple views. As actors move about, groups may split, merge, and reform, and robots filming these actors should be able to adapt smoothly to such changes in actor formations. Rather than adopt an approach based on explicit formations or assignments, we propose an approach based on optimizing views directly. We model actors as moving polyhedra and compute approximate pixel densities for each face and camera view. Then, we propose an objective that exhibits diminishing returns as pixel densities increase from repeated observation. This gives rise to a multi-robot perception planning problem which we solve via a combination of value iteration and greedy submodular maximization. %using a combination of value iteration to optimize views for individual robots and sequential submodular maximization methods to coordinate the team. We evaluate our approach on challenging scenarios modeled after various kinds of social behaviors and featuring different numbers of robots and actors and observe that robot assignments and formations arise implicitly based on the movements of groups of actors. Simulation results demonstrate that our approach consistently outperforms baselines, and in addition to performing well with the planner's approximation of pixel densities our approach also performs comparably for evaluation based on rendered views. Overall, the multi-round variant of the sequential planner we propose meets (within 1%) or exceeds the formation and assignment baselines in all scenarios we consider.
Deep Bayesian Future Fusion for Self-Supervised, High-Resolution, Off-Road Mapping
Mar 18, 2024



The limited sensing resolution of resource-constrained off-road vehicles poses significant challenges towards reliable off-road autonomy. To overcome this limitation, we propose a general framework based on fusing the future information (i.e. future fusion) for self-supervision. Recent approaches exploit this future information alongside the hand-crafted heuristics to directly supervise the targeted downstream tasks (e.g. traversability estimation). However, in this paper, we opt for a more general line of development - time-efficient completion of the highest resolution (i.e. 2cm per pixel) BEV map in a self-supervised manner via future fusion, which can be used for any downstream tasks for better longer range prediction. To this end, first, we create a high-resolution future-fusion dataset containing pairs of (RGB / height) raw sparse and noisy inputs and map-based dense labels. Next, to accommodate the noise and sparsity of the sensory information, especially in the distal regions, we design an efficient realization of the Bayes filter onto the vanilla convolutional network via the recurrent mechanism. Equipped with the ideas from SOTA generative models, our Bayesian structure effectively predicts high-quality BEV maps in the distal regions. Extensive evaluation on both the quality of completion and downstream task on our future-fusion dataset demonstrates the potential of our approach.
Learning Generalizable Feature Fields for Mobile Manipulation
Mar 12, 2024



An open problem in mobile manipulation is how to represent objects and scenes in a unified manner, so that robots can use it both for navigating in the environment and manipulating objects. The latter requires capturing intricate geometry while understanding fine-grained semantics, whereas the former involves capturing the complexity inherit to an expansive physical scale. In this work, we present GeFF (Generalizable Feature Fields), a scene-level generalizable neural feature field that acts as a unified representation for both navigation and manipulation that performs in real-time. To do so, we treat generative novel view synthesis as a pre-training task, and then align the resulting rich scene priors with natural language via CLIP feature distillation. We demonstrate the effectiveness of this approach by deploying GeFF on a quadrupedal robot equipped with a manipulator. We evaluate GeFF's ability to generalize to open-set objects as well as running time, when performing open-vocabulary mobile manipulation in dynamic scenes.