 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJaxRobotarium: Training and Deploying Multi-Robot Policies in 10 Minutes
May 10, 2025



Multi-agent reinforcement learning (MARL) has emerged as a promising solution for learning complex and scalable coordination behaviors in multi-robot systems. However, established MARL platforms (e.g., SMAC and MPE) lack robotics relevance and hardware deployment, leaving multi-robot learning researchers to develop bespoke environments and hardware testbeds dedicated to the development and evaluation of their individual contributions. The Multi-Agent RL Benchmark and Learning Environment for the Robotarium (MARBLER) is an exciting recent step in providing a standardized robotics-relevant platform for MARL, by bridging the Robotarium testbed with existing MARL software infrastructure. However, MARBLER lacks support for parallelization and GPU/TPU execution, making the platform prohibitively slow compared to modern MARL environments and hindering adoption. We contribute JaxRobotarium, a Jax-powered end-to-end simulation, learning, deployment, and benchmarking platform for the Robotarium. JaxRobotarium enables rapid training and deployment of multi-robot reinforcement learning (MRRL) policies with realistic robot dynamics and safety constraints, supporting both parallelization and hardware acceleration. Our generalizable learning interface provides an easy-to-use integration with SOTA MARL libraries (e.g., JaxMARL). In addition, JaxRobotarium includes eight standardized coordination scenarios, including four novel scenarios that bring established MARL benchmark tasks (e.g., RWARE and Level-Based Foraging) to a realistic robotics setting. We demonstrate that JaxRobotarium retains high simulation fidelity while achieving dramatic speedups over baseline (20x in training and 150x in simulation), and provides an open-access sim-to-real evaluation pipeline through the Robotarium testbed, accelerating and democratizing access to multi-robot learning research and evaluation.
Distributed Multi-robot Source Seeking in Unknown Environments with Unknown Number of Sources
Mar 14, 2025We introduce a novel distributed source seeking framework, DIAS, designed for multi-robot systems in scenarios where the number of sources is unknown and potentially exceeds the number of robots. Traditional robotic source seeking methods typically focused on directing each robot to a specific strong source and may fall short in comprehensively identifying all potential sources. DIAS addresses this gap by introducing a hybrid controller that identifies the presence of sources and then alternates between exploration for data gathering and exploitation for guiding robots to identified sources. It further enhances search efficiency by dividing the environment into Voronoi cells and approximating source density functions based on Gaussian process regression. Additionally, DIAS can be integrated with existing source seeking algorithms. We compare DIAS with existing algorithms, including DoSS and GMES in simulated gas leakage scenarios where the number of sources outnumbers or is equal to the number of robots. The numerical results show that DIAS outperforms the baseline methods in both the efficiency of source identification by the robots and the accuracy of the estimated environmental density function.
DyPNIPP: Predicting Environment Dynamics for RL-based Robust Informative Path Planning
Oct 22, 2024



Informative path planning (IPP) is an important planning paradigm for various real-world robotic applications such as environment monitoring. IPP involves planning a path that can learn an accurate belief of the quantity of interest, while adhering to planning constraints. Traditional IPP methods typically require high computation time during execution, giving rise to reinforcement learning (RL) based IPP methods. However, the existing RL-based methods do not consider spatio-temporal environments which involve their own challenges due to variations in environment characteristics. In this paper, we propose DyPNIPP, a robust RL-based IPP framework, designed to operate effectively across spatio-temporal environments with varying dynamics. To achieve this, DyPNIPP incorporates domain randomization to train the agent across diverse environments and introduces a dynamics prediction model to capture and adapt the agent actions to specific environment dynamics. Our extensive experiments in a wildfire environment demonstrate that DyPNIPP outperforms existing RL-based IPP algorithms by significantly improving robustness and performing across diverse environment conditions.
OffRIPP: Offline RL-based Informative Path Planning
Sep 25, 2024



Informative path planning (IPP) is a crucial task in robotics, where agents must design paths to gather valuable information about a target environment while adhering to resource constraints. Reinforcement learning (RL) has been shown to be effective for IPP, however, it requires environment interactions, which are risky and expensive in practice. To address this problem, we propose an offline RL-based IPP framework that optimizes information gain without requiring real-time interaction during training, offering safety and cost-efficiency by avoiding interaction, as well as superior performance and fast computation during execution -- key advantages of RL. Our framework leverages batch-constrained reinforcement learning to mitigate extrapolation errors, enabling the agent to learn from pre-collected datasets generated by arbitrary algorithms. We validate the framework through extensive simulations and real-world experiments. The numerical results show that our framework outperforms the baselines, demonstrating the effectiveness of the proposed approach.
A Comparison of Imitation Learning Algorithms for Bimanual Manipulation
Aug 13, 2024



Amidst the wide popularity of imitation learning algorithms in robotics, their properties regarding hyperparameter sensitivity, ease of training, data efficiency, and performance have not been well-studied in high-precision industry-inspired environments. In this work, we demonstrate the limitations and benefits of prominent imitation learning approaches and analyze their capabilities regarding these properties. We evaluate each algorithm on a complex bimanual manipulation task involving an over-constrained dynamics system in a setting involving multiple contacts between the manipulated object and the environment. While we find that imitation learning is well suited to solve such complex tasks, not all algorithms are equal in terms of handling environmental and hyperparameter perturbations, training requirements, performance, and ease of use. We investigate the empirical influence of these key characteristics by employing a carefully designed experimental procedure and learning environment. Paper website: https://bimanual-imitation.github.io/
WIT-UAS: A Wildland-fire Infrared Thermal Dataset to Detect Crew Assets From Aerial Views
Dec 14, 2023



We present the Wildland-fire Infrared Thermal (WIT-UAS) dataset for long-wave infrared sensing of crew and vehicle assets amidst prescribed wildland fire environments. While such a dataset is crucial for safety monitoring in wildland fire applications, to the authors' awareness, no such dataset focusing on assets near fire is publicly available. Presumably, this is due to the barrier to entry of collaborating with fire management personnel. We present two related data subsets: WIT-UAS-ROS consists of full ROS bag files containing sensor and robot data of UAS flight over the fire, and WIT-UAS-Image contains hand-labeled long-wave infrared (LWIR) images extracted from WIT-UAS-ROS. Our dataset is the first to focus on asset detection in a wildland fire environment. We show that thermal detection models trained without fire data frequently detect false positives by classifying fire as people. By adding our dataset to training, we show that the false positive rate is reduced significantly. Yet asset detection in wildland fire environments is still significantly more challenging than detection in urban environments, due to dense obscuring trees, greater heat variation, and overbearing thermal signal of the fire. We publicize this dataset to encourage the community to study more advanced models to tackle this challenging environment. The dataset, code and pretrained models are available at \url{https://github.com/castacks/WIT-UAS-Dataset}.
On the Role of Emergent Communication for Social Learning in Multi-Agent Reinforcement Learning
Feb 28, 2023Explicit communication among humans is key to coordinating and learning. Social learning, which uses cues from experts, can greatly benefit from the usage of explicit communication to align heterogeneous policies, reduce sample complexity, and solve partially observable tasks. Emergent communication, a type of explicit communication, studies the creation of an artificial language to encode a high task-utility message directly from data. However, in most cases, emergent communication sends insufficiently compressed messages with little or null information, which also may not be understandable to a third-party listener. This paper proposes an unsupervised method based on the information bottleneck to capture both referential complexity and task-specific utility to adequately explore sparse social communication scenarios in multi-agent reinforcement learning (MARL). We show that our model is able to i) develop a natural-language-inspired lexicon of messages that is independently composed of a set of emergent concepts, which span the observations and intents with minimal bits, ii) develop communication to align the action policies of heterogeneous agents with dissimilar feature models, and iii) learn a communication policy from watching an expert's action policy, which we term `social shadowing'.
Towards True Lossless Sparse Communication in Multi-Agent Systems
Nov 30, 2022



Communication enables agents to cooperate to achieve their goals. Learning when to communicate, i.e., sparse (in time) communication, and whom to message is particularly important when bandwidth is limited. Recent work in learning sparse individualized communication, however, suffers from high variance during training, where decreasing communication comes at the cost of decreased reward, particularly in cooperative tasks. We use the information bottleneck to reframe sparsity as a representation learning problem, which we show naturally enables lossless sparse communication at lower budgets than prior art. In this paper, we propose a method for true lossless sparsity in communication via Information Maximizing Gated Sparse Multi-Agent Communication (IMGS-MAC). Our model uses two individualized regularization objectives, an information maximization autoencoder and sparse communication loss, to create informative and sparse communication. We evaluate the learned communication `language' through direct causal analysis of messages in non-sparse runs to determine the range of lossless sparse budgets, which allow zero-shot sparsity, and the range of sparse budgets that will inquire a reward loss, which is minimized by our learned gating function with few-shot sparsity. To demonstrate the efficacy of our results, we experiment in cooperative multi-agent tasks where communication is essential for success. We evaluate our model with both continuous and discrete messages. We focus our analysis on a variety of ablations to show the effect of message representations, including their properties, and lossless performance of our model.
Multiagent Rollout and Policy Iteration for POMDP with Application to Multi-Robot Repair Problems
Nov 09, 2020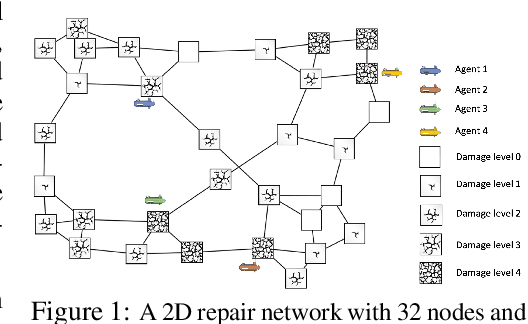
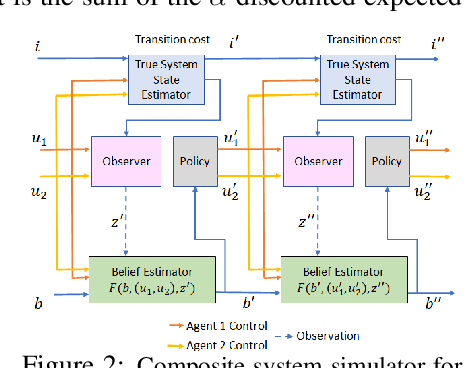

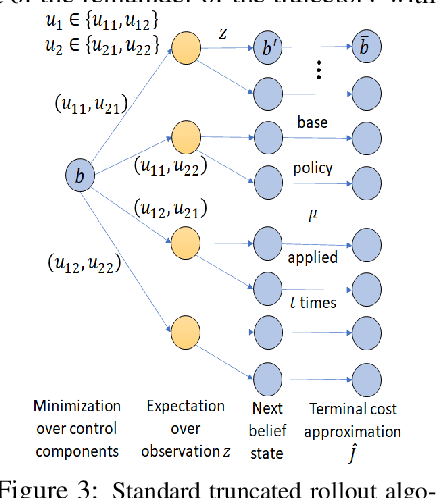
In this paper we consider infinite horizon discounted dynamic programming problems with finite state and control spaces, partial state observations, and a multiagent structure. We discuss and compare algorithms that simultaneously or sequentially optimize the agents' controls by using multistep lookahead, truncated rollout with a known base policy, and a terminal cost function approximation. Our methods specifically address the computational challenges of partially observable multiagent problems. In particular: 1) We consider rollout algorithms that dramatically reduce required computation while preserving the key cost improvement property of the standard rollout method. The per-step computational requirements for our methods are on the order of $O(Cm)$ as compared with $O(C^m)$ for standard rollout, where $C$ is the maximum cardinality of the constraint set for the control component of each agent, and $m$ is the number of agents. 2) We show that our methods can be applied to challenging problems with a graph structure, including a class of robot repair problems whereby multiple robots collaboratively inspect and repair a system under partial information. 3) We provide a simulation study that compares our methods with existing methods, and demonstrate that our methods can handle larger and more complex partially observable multiagent problems (state space size $10^{37}$ and control space size $10^{7}$, respectively). Finally, we incorporate our multiagent rollout algorithms as building blocks in an approximate policy iteration scheme, where successive rollout policies are approximated by using neural network classifiers. While this scheme requires a strictly off-line implementation, it works well in our computational experiments and produces additional significant performance improvement over the single online rollout iteration method.