 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBANG: Bridging Autoregressive and Non-autoregressive Generation with Large Scale Pretraining
Dec 31, 2020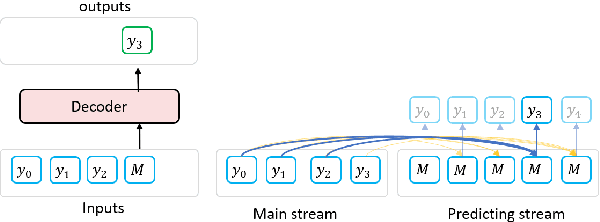
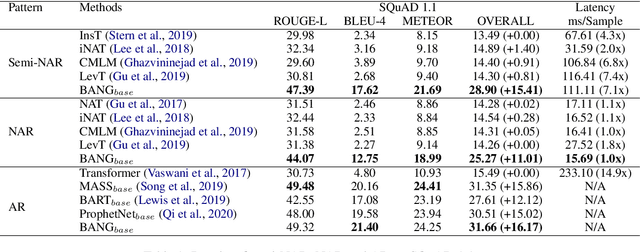
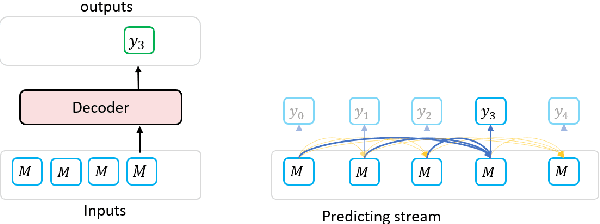
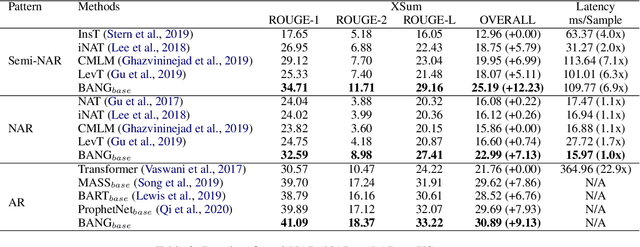
In this paper, we propose BANG, a new pretraining model to Bridge the gap between Autoregressive (AR) and Non-autoregressive (NAR) Generation. AR and NAR generation can be uniformly regarded as what extend of previous tokens can be attended to, and BANG bridges AR and NAR generation through designing a novel model structure for large-scale pre-training. A pretrained BANG model can simultaneously support AR, NAR, and semi-NAR generation to meet different requirements. Experiments on question generation (SQuAD 1.1), summarization (XSum), and dialogue (PersonaChat) show that BANG improves NAR and semi-NAR performance significantly as well as attaining comparable performance with strong AR pretrained models. Compared with the semi-NAR strong baselines, BANG achieves absolute improvements of 14.01 and 5.24 in overall scores of SQuAD and XSum, respectively. In addition, BANG achieves absolute improvements of 10.73, 6.39, and 5.90 in overall scores of SQuAD, XSUM, and PersonaChat compared with the NAR strong baselines, respectively. Our code will be made publicly available in the near future\footnote{https://github.com/microsoft/BANG}.
An Enhanced Knowledge Injection Model for Commonsense Generation
Dec 01, 2020
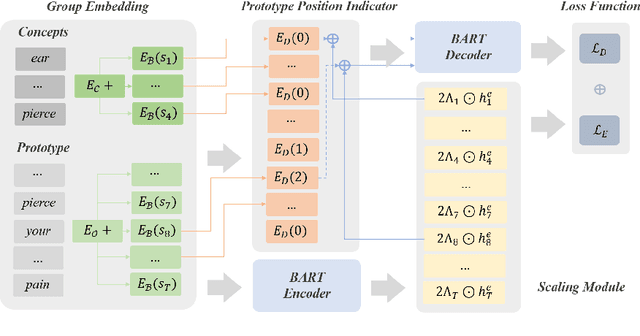
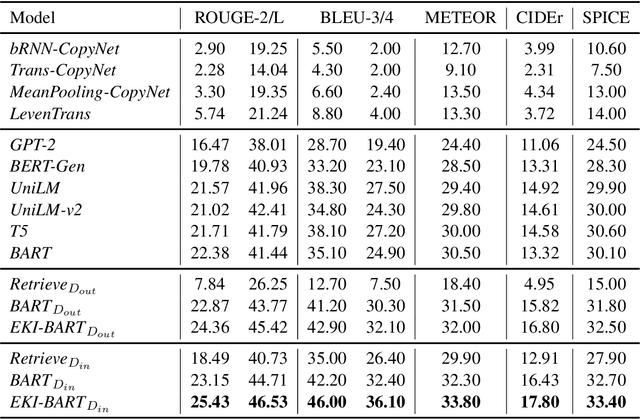
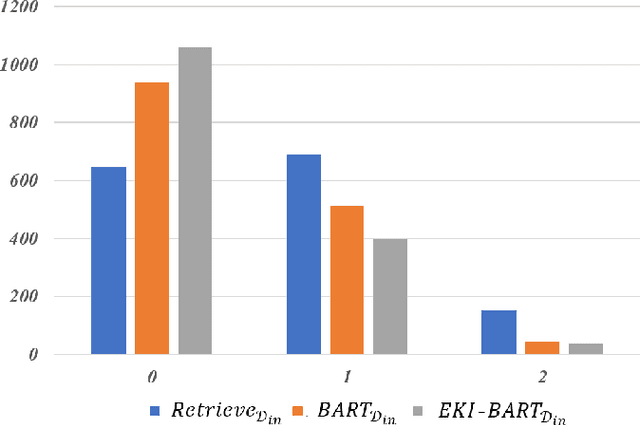
Commonsense generation aims at generating plausible everyday scenario description based on a set of provided concepts. Digging the relationship of concepts from scratch is non-trivial, therefore, we retrieve prototypes from external knowledge to assist the understanding of the scenario for better description generation. We integrate two additional modules, namely position indicator and scaling module, into the pretrained encoder-decoder model for prototype modeling to enhance the knowledge injection procedure. We conduct experiment on CommonGen benchmark, and experimental results show that our method significantly improves the performance on all the metrics.
GLGE: A New General Language Generation Evaluation Benchmark
Nov 24, 2020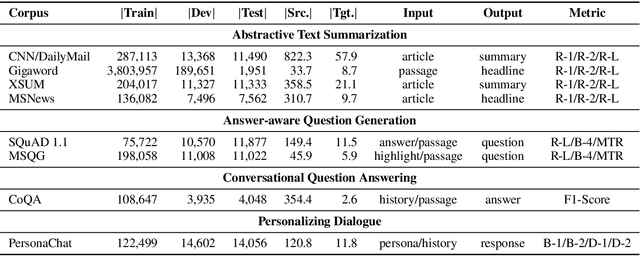
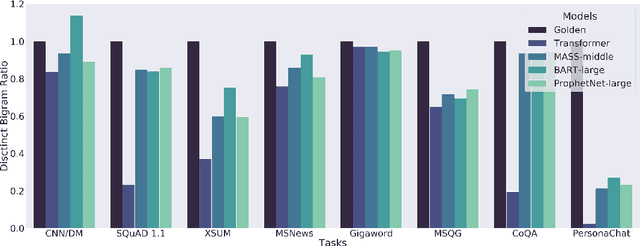

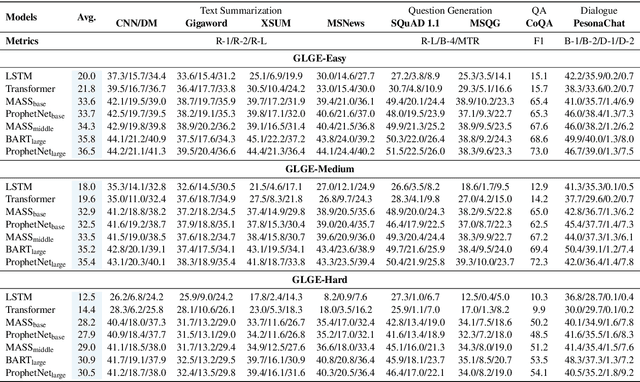
Multi-task benchmarks such as GLUE and SuperGLUE have driven great progress of pretraining and transfer learning in Natural Language Processing (NLP). These benchmarks mostly focus on a range of Natural Language Understanding (NLU) tasks, without considering the Natural Language Generation (NLG) models. In this paper, we present the General Language Generation Evaluation (GLGE), a new multi-task benchmark for evaluating the generalization capabilities of NLG models across eight language generation tasks. For each task, we continue to design three subtasks in terms of task difficulty (GLGE-Easy, GLGE-Medium, and GLGE-Hard). This introduces 24 subtasks to comprehensively compare model performance. To encourage research on pretraining and transfer learning on NLG models, we make GLGE publicly available and build a leaderboard with strong baselines including MASS, BART, and ProphetNet\footnote{The source code and dataset will be publicly available at https://github.com/microsoft/glge.
ProphetNet-Ads: A Looking Ahead Strategy for Generative Retrieval Models in Sponsored Search Engine
Oct 21, 2020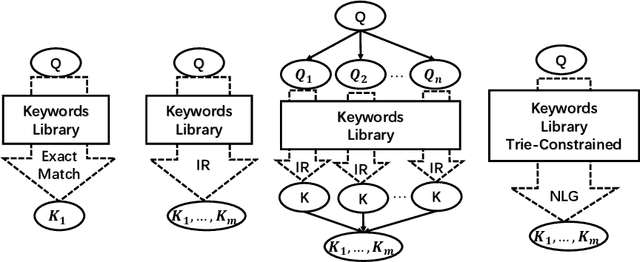
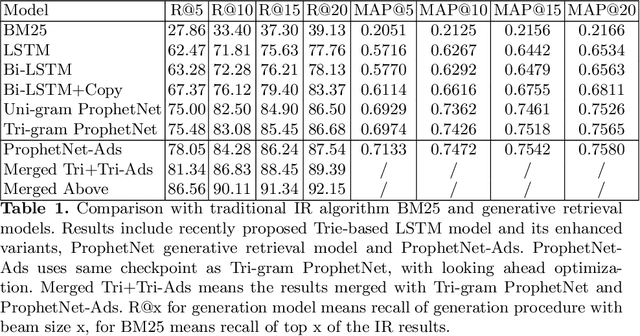
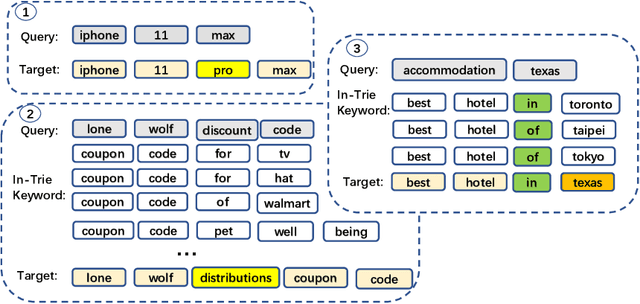
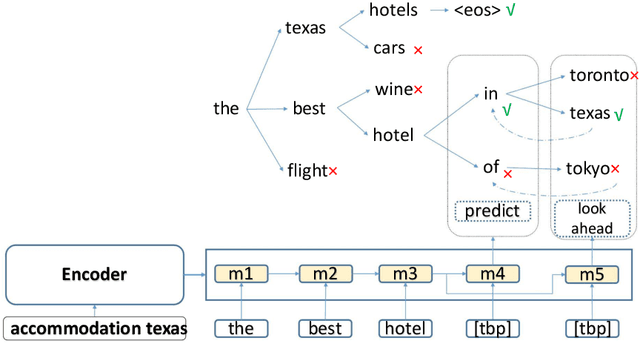
In a sponsored search engine, generative retrieval models are recently proposed to mine relevant advertisement keywords for users' input queries. Generative retrieval models generate outputs token by token on a path of the target library prefix tree (Trie), which guarantees all of the generated outputs are legal and covered by the target library. In actual use, we found several typical problems caused by Trie-constrained searching length. In this paper, we analyze these problems and propose a looking ahead strategy for generative retrieval models named ProphetNet-Ads. ProphetNet-Ads improves the retrieval ability by directly optimizing the Trie-constrained searching space. We build a dataset from a real-word sponsored search engine and carry out experiments to analyze different generative retrieval models. Compared with Trie-based LSTM generative retrieval model proposed recently, our single model result and integrated result improve the recall by 15.58\% and 18.8\% respectively with beam size 5. Case studies further demonstrate how these problems are alleviated by ProphetNet-Ads clearly.
AutoADR: Automatic Model Design for Ad Relevance
Oct 14, 2020

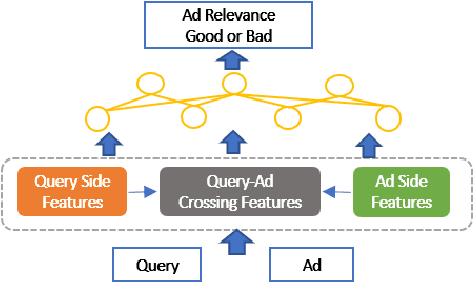
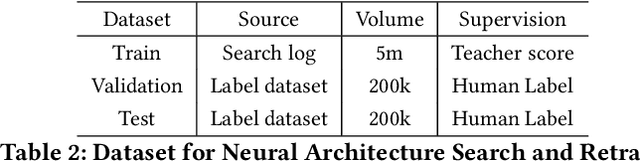
Large-scale pre-trained models have attracted extensive attention in the research community and shown promising results on various tasks of natural language processing. However, these pre-trained models are memory and computation intensive, hindering their deployment into industrial online systems like Ad Relevance. Meanwhile, how to design an effective yet efficient model architecture is another challenging problem in online Ad Relevance. Recently, AutoML shed new lights on architecture design, but how to integrate it with pre-trained language models remains unsettled. In this paper, we propose AutoADR (Automatic model design for AD Relevance) -- a novel end-to-end framework to address this challenge, and share our experience to ship these cutting-edge techniques into online Ad Relevance system at Microsoft Bing. Specifically, AutoADR leverages a one-shot neural architecture search algorithm to find a tailored network architecture for Ad Relevance. The search process is simultaneously guided by knowledge distillation from a large pre-trained teacher model (e.g. BERT), while taking the online serving constraints (e.g. memory and latency) into consideration. We add the model designed by AutoADR as a sub-model into the production Ad Relevance model. This additional sub-model improves the Precision-Recall AUC (PR AUC) on top of the original Ad Relevance model by 2.65X of the normalized shipping bar. More importantly, adding this automatically designed sub-model leads to a statistically significant 4.6% Bad-Ad ratio reduction in online A/B testing. This model has been shipped into Microsoft Bing Ad Relevance Production model.
HittER: Hierarchical Transformers for Knowledge Graph Embeddings
Aug 28, 2020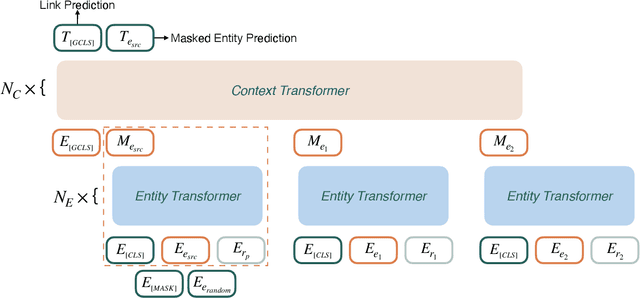
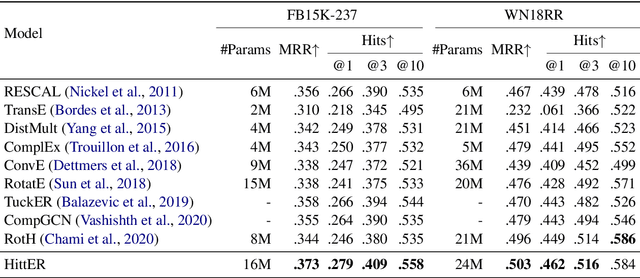

This paper examines the challenging problem of learning representations of entities and relations in a complex multi-relational knowledge graph. We propose HittER, a Hierarchical Transformer model to jointly learn Entity-relation composition and Relational contextualization based on a source entity's neighborhood. Our proposed model consists of two different Transformer blocks: the bottom block extracts features of each entity-relation pair in the local neighborhood of the source entity and the top block aggregates the relational information from the outputs of the bottom block. We further design a masked entity prediction task to balance information from the relational context and the source entity itself. Evaluated on the task of link prediction, our approach achieves new state-of-the-art results on two standard benchmark datasets FB15K-237 and WN18RR.
ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training
Feb 22, 2020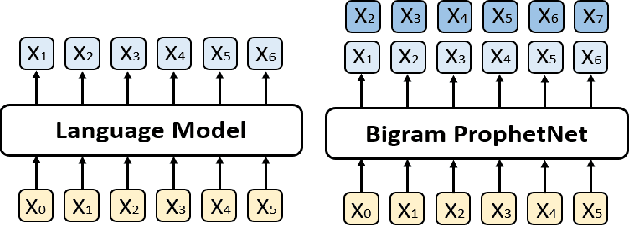
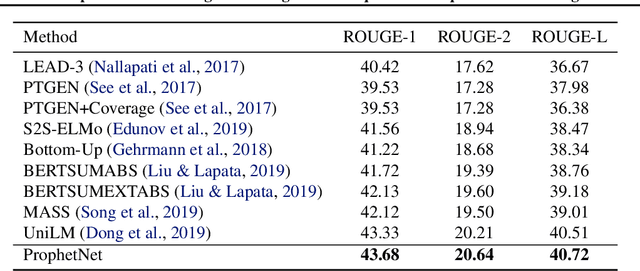
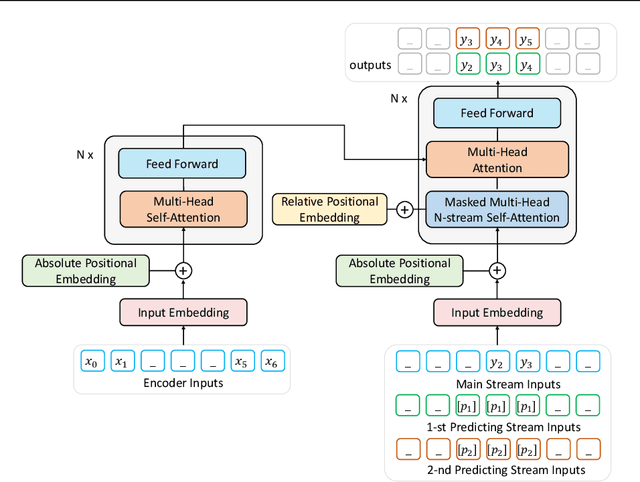
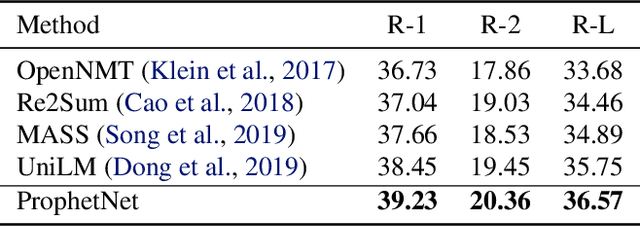
In this paper, we present a new sequence-to-sequence pre-training model called ProphetNet, which introduces a novel self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new state-of-the-art results on all these datasets compared to the models using the same scale pre-training corpus.
TwinBERT: Distilling Knowledge to Twin-Structured BERT Models for Efficient Retrieval
Feb 14, 2020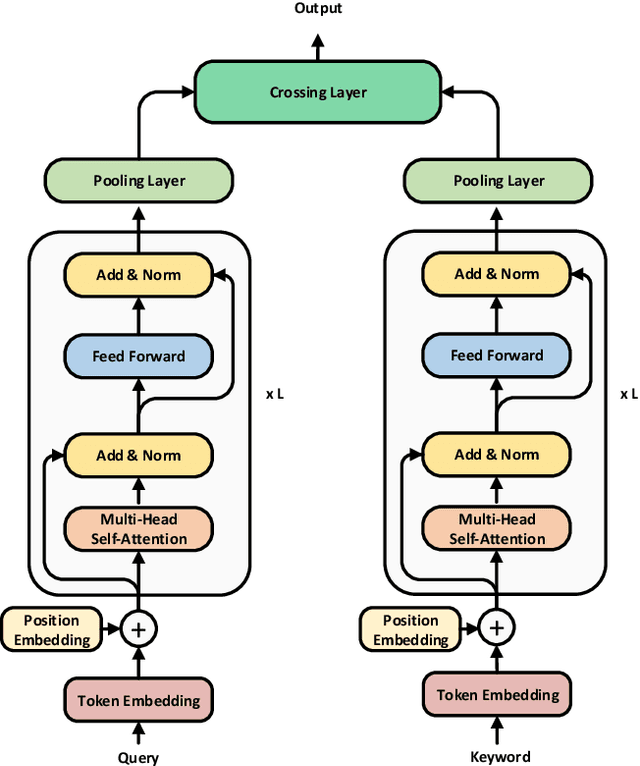
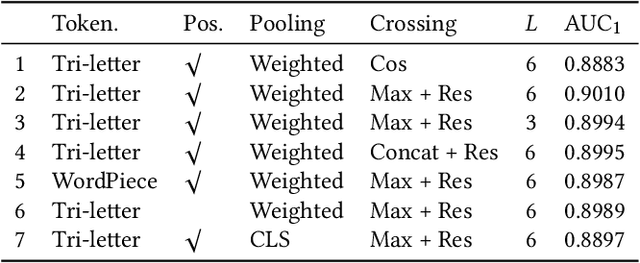
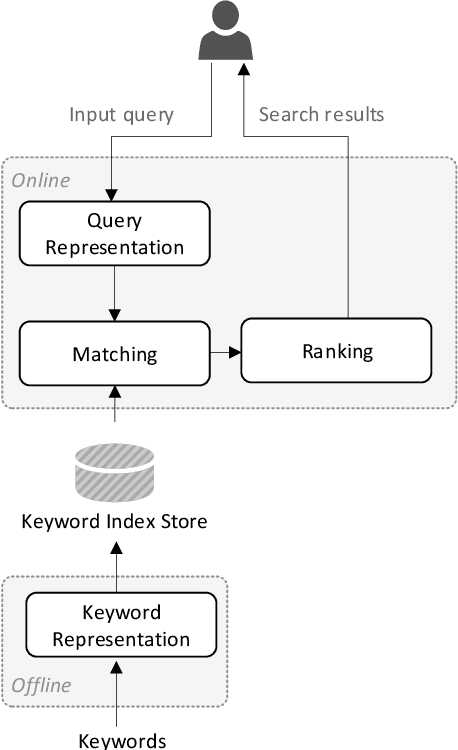
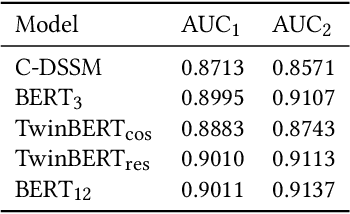
Pre-trained language models like BERT have achieved great success in a wide variety of NLP tasks, while the superior performance comes with high demand in computational resources, which hinders the application in low-latency IR systems. We present TwinBERT model for effective and efficient retrieval, which has twin-structured BERT-like encoders to represent query and document respectively and a crossing layer to combine the embeddings and produce a similarity score. Different from BERT, where the two input sentences are concatenated and encoded together, TwinBERT decouples them during encoding and produces the embeddings for query and document independently, which allows document embeddings to be pre-computed offline and cached in memory. Thereupon, the computation left for run-time is from the query encoding and query-document crossing only. This single change can save large amount of computation time and resources, and therefore significantly improve serving efficiency. Moreover, a few well-designed network layers and training strategies are proposed to further reduce computational cost while at the same time keep the performance as remarkable as BERT model. Lastly, we develop two versions of TwinBERT for retrieval and relevance tasks correspondingly, and both of them achieve close or on-par performance to BERT-Base model. The model was trained following the teacher-student framework and evaluated with data from one of the major search engines. Experimental results showed that the inference time was significantly reduced and was firstly controlled around 20ms on CPUs while at the same time the performance gain from fine-tuned BERT-Base model was mostly retained. Integration of the models into production systems also demonstrated remarkable improvements on relevance metrics with negligible influence on latency.
DeepProbe: Information Directed Sequence Understanding and Chatbot Design via Recurrent Neural Networks
Mar 01, 2018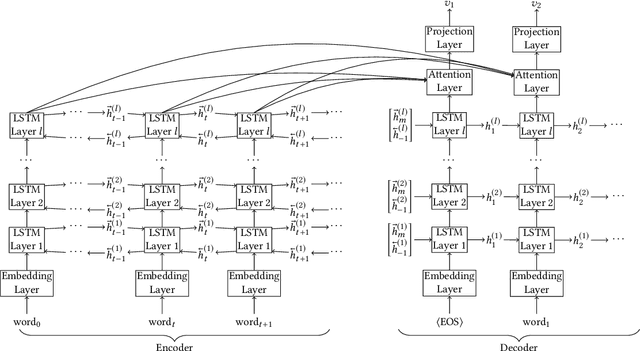

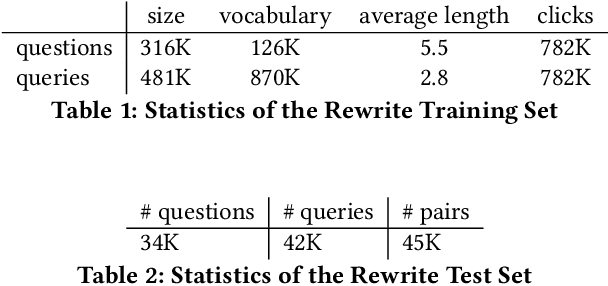
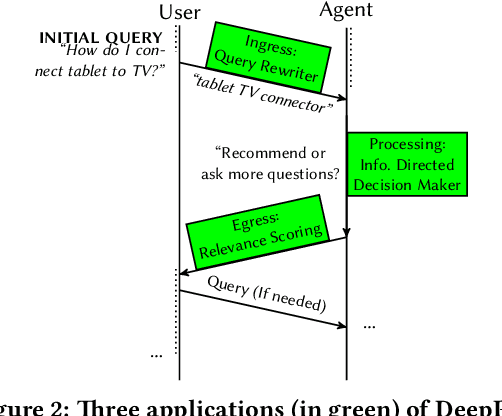
Information extraction and user intention identification are central topics in modern query understanding and recommendation systems. In this paper, we propose DeepProbe, a generic information-directed interaction framework which is built around an attention-based sequence to sequence (seq2seq) recurrent neural network. DeepProbe can rephrase, evaluate, and even actively ask questions, leveraging the generative ability and likelihood estimation made possible by seq2seq models. DeepProbe makes decisions based on a derived uncertainty (entropy) measure conditioned on user inputs, possibly with multiple rounds of interactions. Three applications, namely a rewritter, a relevance scorer and a chatbot for ad recommendation, were built around DeepProbe, with the first two serving as precursory building blocks for the third. We first use the seq2seq model in DeepProbe to rewrite a user query into one of standard query form, which is submitted to an ordinary recommendation system. Secondly, we evaluate DeepProbe's seq2seq model-based relevance scoring. Finally, we build a chatbot prototype capable of making active user interactions, which can ask questions that maximize information gain, allowing for a more efficient user intention idenfication process. We evaluate first two applications by 1) comparing with baselines by BLEU and AUC, and 2) human judge evaluation. Both demonstrate significant improvements compared with current state-of-the-art systems, proving their values as useful tools on their own, and at the same time laying a good foundation for the ongoing chatbot application.
Large-Scale Multi-Label Learning with Incomplete Label Assignments
Jul 06, 2014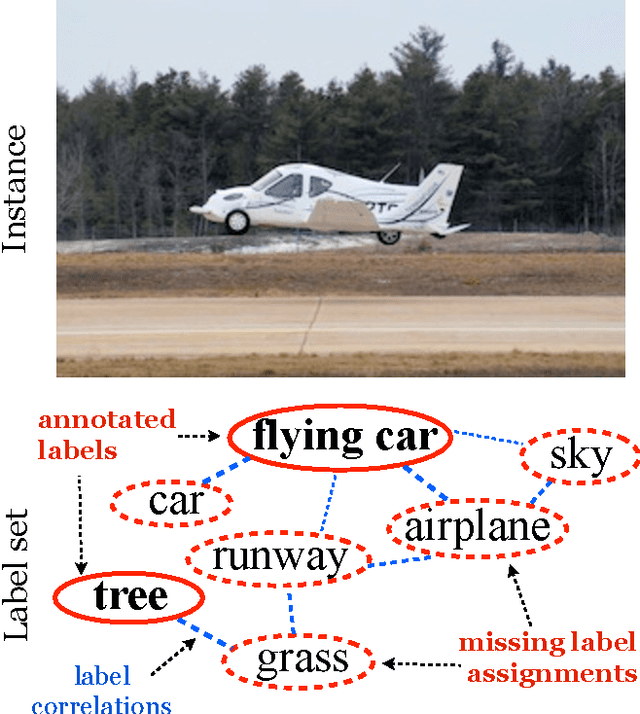

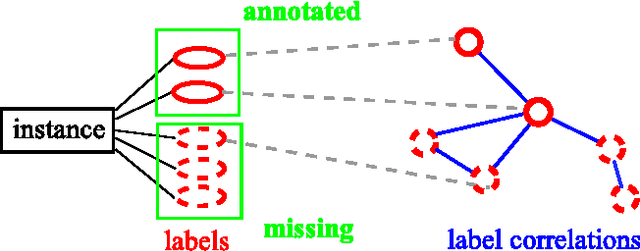

Multi-label learning deals with the classification problems where each instance can be assigned with multiple labels simultaneously. Conventional multi-label learning approaches mainly focus on exploiting label correlations. It is usually assumed, explicitly or implicitly, that the label sets for training instances are fully labeled without any missing labels. However, in many real-world multi-label datasets, the label assignments for training instances can be incomplete. Some ground-truth labels can be missed by the labeler from the label set. This problem is especially typical when the number instances is very large, and the labeling cost is very high, which makes it almost impossible to get a fully labeled training set. In this paper, we study the problem of large-scale multi-label learning with incomplete label assignments. We propose an approach, called MPU, based upon positive and unlabeled stochastic gradient descent and stacked models. Unlike prior works, our method can effectively and efficiently consider missing labels and label correlations simultaneously, and is very scalable, that has linear time complexities over the size of the data. Extensive experiments on two real-world multi-label datasets show that our MPU model consistently outperform other commonly-used baselines.