 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyVal 2: Dynamic Evaluation of Large Language Models by Meta Probing Agents
Feb 21, 2024



Evaluation of large language models (LLMs) has raised great concerns in the community due to the issue of data contamination. Existing work designed evaluation protocols using well-defined algorithms for specific tasks, which cannot be easily extended to diverse scenarios. Moreover, current evaluation benchmarks can only provide the overall benchmark results and cannot support a fine-grained and multifaceted analysis of LLMs' abilities. In this paper, we propose meta probing agents (MPA), a general dynamic evaluation protocol inspired by psychometrics to evaluate LLMs. MPA is the key component of DyVal 2, which naturally extends the previous DyVal~\citep{zhu2023dyval}. MPA designs the probing and judging agents to automatically transform an original evaluation problem into a new one following psychometric theory on three basic cognitive abilities: language understanding, problem solving, and domain knowledge. These basic abilities are also dynamically configurable, allowing multifaceted analysis. We conducted extensive evaluations using MPA and found that most LLMs achieve poorer performance, indicating room for improvement. Our multifaceted analysis demonstrated the strong correlation between the basic abilities and an implicit Matthew effect on model size, i.e., larger models possess stronger correlations of the abilities. MPA can also be used as a data augmentation approach to enhance LLMs.
Supervised Knowledge Makes Large Language Models Better In-context Learners
Dec 26, 2023



Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
Language Models can be Logical Solvers
Nov 10, 2023



Logical reasoning is a fundamental aspect of human intelligence and a key component of tasks like problem-solving and decision-making. Recent advancements have enabled Large Language Models (LLMs) to potentially exhibit reasoning capabilities, but complex logical reasoning remains a challenge. The state-of-the-art, solver-augmented language models, use LLMs to parse natural language logical questions into symbolic representations first and then adopt external logical solvers to take in the symbolic representations and output the answers. Despite their impressive performance, any parsing errors will inevitably result in the failure of the execution of the external logical solver and no answer to the logical questions. In this paper, we introduce LoGiPT, a novel language model that directly emulates the reasoning processes of logical solvers and bypasses the parsing errors by learning to strict adherence to solver syntax and grammar. LoGiPT is fine-tuned on a newly constructed instruction-tuning dataset derived from revealing and refining the invisible reasoning process of deductive solvers. Experimental results on two public deductive reasoning datasets demonstrate that LoGiPT outperforms state-of-the-art solver-augmented LMs and few-shot prompting methods on competitive LLMs like ChatGPT or GPT-4.
In-Context Demonstration Selection with Cross Entropy Difference
May 24, 2023Large language models (LLMs) can use in-context demonstrations to improve performance on zero-shot tasks. However, selecting the best in-context examples is challenging because model performance can vary widely depending on the selected examples. We present a cross-entropy difference (CED) method for selecting in-context demonstrations. Our method is based on the observation that the effectiveness of in-context demonstrations negatively correlates with the perplexity of the test example by a language model that was finetuned on that demonstration. We utilize parameter efficient finetuning to train small models on training data that are used for computing the cross-entropy difference between a test example and every candidate in-context demonstration. This metric is used to rank and select in-context demonstrations independently for each test input. We evaluate our method on a mix-domain dataset that combines 8 benchmarks, representing 4 text generation tasks, showing that CED for in-context demonstration selection can improve performance for a variety of LLMs.
InheritSumm: A General, Versatile and Compact Summarizer by Distilling from GPT
May 22, 2023While large models such as GPT-3 demonstrate exceptional performance in zeroshot and fewshot summarization tasks, their extensive serving and fine-tuning costs hinder their utilization in various applications. Conversely, previous studies have found that although automatic metrics tend to favor smaller fine-tuned models, the quality of the summaries they generate is inferior to that of larger models like GPT-3 when assessed by human evaluators. To address this issue, we propose InheritSumm, a versatile and compact summarization model derived from GPT-3.5 through distillation. InheritSumm not only exhibits comparable zeroshot and fewshot summarization capabilities to GPT-3.5 but is also sufficiently compact for fine-tuning purposes. Experimental results demonstrate that InheritSumm achieves similar or superior performance to GPT-3.5 in zeroshot and fewshot settings. Furthermore, it outperforms the previously established best small models in both prefix-tuning and full-data fine-tuning scenarios.
LMGQS: A Large-scale Dataset for Query-focused Summarization
May 22, 2023



Query-focused summarization (QFS) aims to extract or generate a summary of an input document that directly answers or is relevant to a given query. The lack of large-scale datasets in the form of documents, queries, and summaries has hindered model development in this area. In contrast, multiple large-scale high-quality datasets for generic summarization exist. We hypothesize that there is a hidden query for each summary sentence in a generic summarization annotation, and we utilize a large-scale pretrained language model to recover it. In this way, we convert four generic summarization benchmarks into a new QFS benchmark dataset, LMGQS, which consists of over 1 million document-query-summary samples. We thoroughly investigate the properties of our proposed dataset and establish baselines with state-of-the-art summarization models. By fine-tuning a language model on LMGQS, we achieve state-of-the-art zero-shot and supervised performance on multiple existing QFS benchmarks, demonstrating the high quality and diversity of LMGQS.
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Apr 06, 2023The quality of texts generated by natural language generation (NLG) systems is hard to measure automatically. Conventional reference-based metrics, such as BLEU and ROUGE, have been shown to have relatively low correlation with human judgments, especially for tasks that require creativity and diversity. Recent studies suggest using large language models (LLMs) as reference-free metrics for NLG evaluation, which have the benefit of being applicable to new tasks that lack human references. However, these LLM-based evaluators still have lower human correspondence than medium-size neural evaluators. In this work, we present G-Eval, a framework of using large language models with chain-of-thoughts (CoT) and a form-filling paradigm, to assess the quality of NLG outputs. We experiment with two generation tasks, text summarization and dialogue generation. We show that G-Eval with GPT-4 as the backbone model achieves a Spearman correlation of 0.514 with human on summarization task, outperforming all previous methods by a large margin. We also propose preliminary analysis on the behavior of LLM-based evaluators, and highlight the potential issue of LLM-based evaluators having a bias towards the LLM-generated texts.
UniSumm: Unified Few-shot Summarization with Multi-Task Pre-Training and Prefix-Tuning
Dec 06, 2022



The diverse demands of different summarization tasks and their high annotation costs are driving a need for few-shot summarization. However, despite the emergence of many summarization tasks and datasets, the current training paradigm for few-shot summarization systems ignores potentially shareable knowledge in heterogeneous datasets. To this end, we propose \textsc{UniSumm}, a unified few-shot summarization model pre-trained with multiple summarization tasks and can be prefix-tuned to excel at any few-shot summarization datasets. Meanwhile, to better evaluate few-shot summarization systems, under the principles of diversity and robustness, we assemble and publicize a new benchmark \textsc{SummZoo}. It consists of $8$ diverse summarization tasks with multiple sets of few-shot samples for each task, covering both monologue and dialogue domains. Experimental results and ablation studies show that \textsc{UniSumm} outperforms strong baseline systems by a large margin across all tasks in \textsc{SummZoo} under both automatic and human evaluations. We release our code and benchmark at \url{https://github.com/microsoft/UniSumm}.
Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization
Aug 21, 2022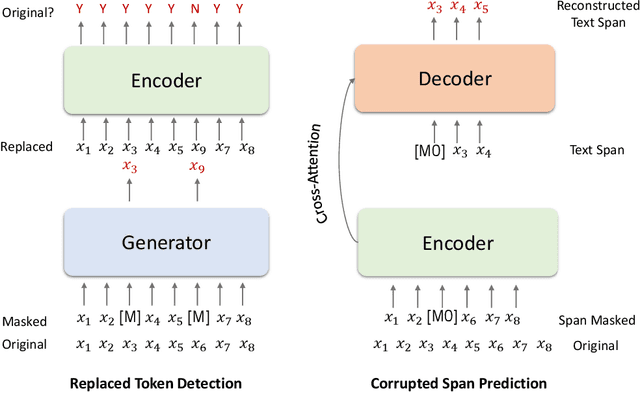

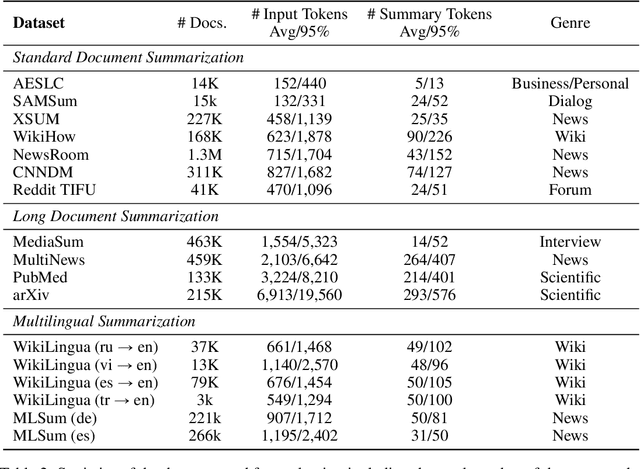
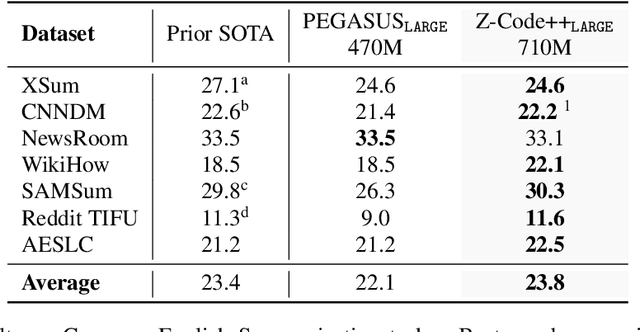
This paper presents Z-Code++, a new pre-trained language model optimized for abstractive text summarization. The model extends the state of the art encoder-decoder model using three techniques. First, we use a two-phase pre-training process to improve model's performance on low-resource summarization tasks. The model is first pre-trained using text corpora for language understanding, and then is continually pre-trained on summarization corpora for grounded text generation. Second, we replace self-attention layers in the encoder with disentangled attention layers, where each word is represented using two vectors that encode its content and position, respectively. Third, we use fusion-in-encoder, a simple yet effective method of encoding long sequences in a hierarchical manner. Z-Code++ creates new state of the art on 9 out of 13 text summarization tasks across 5 languages. Our model is parameter-efficient in that it outperforms the 600x larger PaLM-540B on XSum, and the finetuned 200x larger GPT3-175B on SAMSum. In zero-shot and few-shot settings, our model substantially outperforms the competing models.
Learning Visual Representation from Modality-Shared Contrastive Language-Image Pre-training
Jul 26, 2022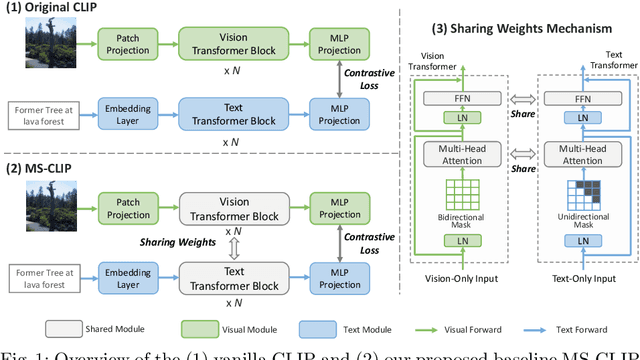
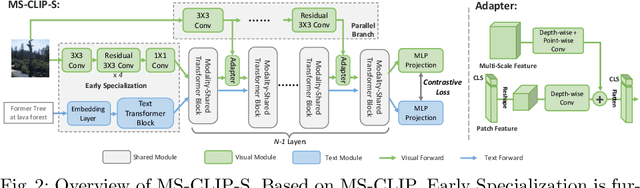
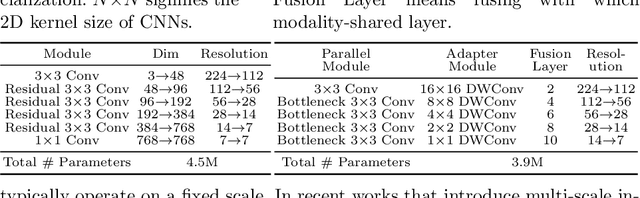
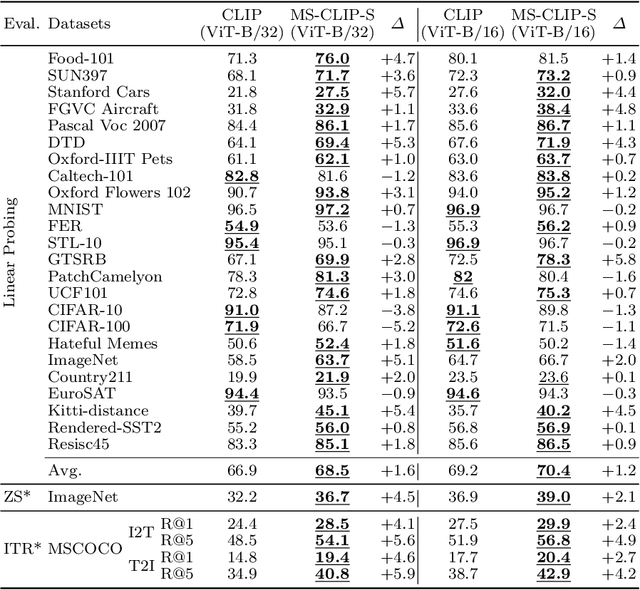
Large-scale multi-modal contrastive pre-training has demonstrated great utility to learn transferable features for a range of downstream tasks by mapping multiple modalities into a shared embedding space. Typically, this has employed separate encoders for each modality. However, recent work suggests that transformers can support learning across multiple modalities and allow knowledge sharing. Inspired by this, we investigate a variety of Modality-Shared Contrastive Language-Image Pre-training (MS-CLIP) frameworks. More specifically, we question how many parameters of a transformer model can be shared across modalities during contrastive pre-training, and rigorously examine architectural design choices that position the proportion of parameters shared along a spectrum. In studied conditions, we observe that a mostly unified encoder for vision and language signals outperforms all other variations that separate more parameters. Additionally, we find that light-weight modality-specific parallel modules further improve performance. Experimental results show that the proposed MS-CLIP approach outperforms vanilla CLIP by up to 13\% relative in zero-shot ImageNet classification (pre-trained on YFCC-100M), while simultaneously supporting a reduction of parameters. In addition, our approach outperforms vanilla CLIP by 1.6 points in linear probing on a collection of 24 downstream vision tasks. Furthermore, we discover that sharing parameters leads to semantic concepts from different modalities being encoded more closely in the embedding space, facilitating the transferring of common semantic structure (e.g., attention patterns) from language to vision. Code is available at \href{https://github.com/Hxyou/MSCLIP}{URL}.