 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMammo-Mamba: A Hybrid State-Space and Transformer Architecture with Sequential Mixture of Experts for Multi-View Mammography
Jul 23, 2025Breast cancer (BC) remains one of the leading causes of cancer-related mortality among women, despite recent advances in Computer-Aided Diagnosis (CAD) systems. Accurate and efficient interpretation of multi-view mammograms is essential for early detection, driving a surge of interest in Artificial Intelligence (AI)-powered CAD models. While state-of-the-art multi-view mammogram classification models are largely based on Transformer architectures, their computational complexity scales quadratically with the number of image patches, highlighting the need for more efficient alternatives. To address this challenge, we propose Mammo-Mamba, a novel framework that integrates Selective State-Space Models (SSMs), transformer-based attention, and expert-driven feature refinement into a unified architecture. Mammo-Mamba extends the MambaVision backbone by introducing the Sequential Mixture of Experts (SeqMoE) mechanism through its customized SecMamba block. The SecMamba is a modified MambaVision block that enhances representation learning in high-resolution mammographic images by enabling content-adaptive feature refinement. These blocks are integrated into the deeper stages of MambaVision, allowing the model to progressively adjust feature emphasis through dynamic expert gating, effectively mitigating the limitations of traditional Transformer models. Evaluated on the CBIS-DDSM benchmark dataset, Mammo-Mamba achieves superior classification performance across all key metrics while maintaining computational efficiency.
The Missing Point in Vision Transformers for Universal Image Segmentation
May 26, 2025Image segmentation remains a challenging task in computer vision, demanding robust mask generation and precise classification. Recent mask-based approaches yield high-quality masks by capturing global context. However, accurately classifying these masks, especially in the presence of ambiguous boundaries and imbalanced class distributions, remains an open challenge. In this work, we introduce ViT-P, a novel two-stage segmentation framework that decouples mask generation from classification. The first stage employs a proposal generator to produce class-agnostic mask proposals, while the second stage utilizes a point-based classification model built on the Vision Transformer (ViT) to refine predictions by focusing on mask central points. ViT-P serves as a pre-training-free adapter, allowing the integration of various pre-trained vision transformers without modifying their architecture, ensuring adaptability to dense prediction tasks. Furthermore, we demonstrate that coarse and bounding box annotations can effectively enhance classification without requiring additional training on fine annotation datasets, reducing annotation costs while maintaining strong performance. Extensive experiments across COCO, ADE20K, and Cityscapes datasets validate the effectiveness of ViT-P, achieving state-of-the-art results with 54.0 PQ on ADE20K panoptic segmentation, 87.4 mIoU on Cityscapes semantic segmentation, and 63.6 mIoU on ADE20K semantic segmentation. The code and pretrained models are available at: https://github.com/sajjad-sh33/ViT-P}{https://github.com/sajjad-sh33/ViT-P.
Advancements in Medical Image Classification through Fine-Tuning Natural Domain Foundation Models
May 26, 2025



Using massive datasets, foundation models are large-scale, pre-trained models that perform a wide range of tasks. These models have shown consistently improved results with the introduction of new methods. It is crucial to analyze how these trends impact the medical field and determine whether these advancements can drive meaningful change. This study investigates the application of recent state-of-the-art foundation models, DINOv2, MAE, VMamba, CoCa, SAM2, and AIMv2, for medical image classification. We explore their effectiveness on datasets including CBIS-DDSM for mammography, ISIC2019 for skin lesions, APTOS2019 for diabetic retinopathy, and CHEXPERT for chest radiographs. By fine-tuning these models and evaluating their configurations, we aim to understand the potential of these advancements in medical image classification. The results indicate that these advanced models significantly enhance classification outcomes, demonstrating robust performance despite limited labeled data. Based on our results, AIMv2, DINOv2, and SAM2 models outperformed others, demonstrating that progress in natural domain training has positively impacted the medical domain and improved classification outcomes. Our code is publicly available at: https://github.com/sajjad-sh33/Medical-Transfer-Learning.
Enhancing Monte Carlo Dropout Performance for Uncertainty Quantification
May 21, 2025Knowing the uncertainty associated with the output of a deep neural network is of paramount importance in making trustworthy decisions, particularly in high-stakes fields like medical diagnosis and autonomous systems. Monte Carlo Dropout (MCD) is a widely used method for uncertainty quantification, as it can be easily integrated into various deep architectures. However, conventional MCD often struggles with providing well-calibrated uncertainty estimates. To address this, we introduce innovative frameworks that enhances MCD by integrating different search solutions namely Grey Wolf Optimizer (GWO), Bayesian Optimization (BO), and Particle Swarm Optimization (PSO) as well as an uncertainty-aware loss function, thereby improving the reliability of uncertainty quantification. We conduct comprehensive experiments using different backbones, namely DenseNet121, ResNet50, and VGG16, on various datasets, including Cats vs. Dogs, Myocarditis, Wisconsin, and a synthetic dataset (Circles). Our proposed algorithm outperforms the MCD baseline by 2-3% on average in terms of both conventional accuracy and uncertainty accuracy while achieving significantly better calibration. These results highlight the potential of our approach to enhance the trustworthiness of deep learning models in safety-critical applications.
AutoRad-Lung: A Radiomic-Guided Prompting Autoregressive Vision-Language Model for Lung Nodule Malignancy Prediction
Mar 26, 2025



Lung cancer remains one of the leading causes of cancer-related mortality worldwide. A crucial challenge for early diagnosis is differentiating uncertain cases with similar visual characteristics and closely annotation scores. In clinical practice, radiologists rely on quantitative, hand-crafted Radiomic features extracted from Computed Tomography (CT) images, while recent research has primarily focused on deep learning solutions. More recently, Vision-Language Models (VLMs), particularly Contrastive Language-Image Pre-Training (CLIP)-based models, have gained attention for their ability to integrate textual knowledge into lung cancer diagnosis. While CLIP-Lung models have shown promising results, we identified the following potential limitations: (a) dependence on radiologists' annotated attributes, which are inherently subjective and error-prone, (b) use of textual information only during training, limiting direct applicability at inference, and (c) Convolutional-based vision encoder with randomly initialized weights, which disregards prior knowledge. To address these limitations, we introduce AutoRad-Lung, which couples an autoregressively pre-trained VLM, with prompts generated from hand-crafted Radiomics. AutoRad-Lung uses the vision encoder of the Large-Scale Autoregressive Image Model (AIMv2), pre-trained using a multi-modal autoregressive objective. Given that lung tumors are typically small, irregularly shaped, and visually similar to healthy tissue, AutoRad-Lung offers significant advantages over its CLIP-based counterparts by capturing pixel-level differences. Additionally, we introduce conditional context optimization, which dynamically generates context-specific prompts based on input Radiomics, improving cross-modal alignment.
Integrating AI for Human-Centric Breast Cancer Diagnostics: A Multi-Scale and Multi-View Swin Transformer Framework
Mar 17, 2025



Despite advancements in Computer-Aided Diagnosis (CAD) systems, breast cancer remains one of the leading causes of cancer-related deaths among women worldwide. Recent breakthroughs in Artificial Intelligence (AI) have shown significant promise in development of advanced Deep Learning (DL) architectures for breast cancer diagnosis through mammography. In this context, the paper focuses on the integration of AI within a Human-Centric workflow to enhance breast cancer diagnostics. Key challenges are, however, largely overlooked such as reliance on detailed tumor annotations and susceptibility to missing views, particularly during test time. To address these issues, we propose a hybrid, multi-scale and multi-view Swin Transformer-based framework (MSMV-Swin) that enhances diagnostic robustness and accuracy. The proposed MSMV-Swin framework is designed to work as a decision-support tool, helping radiologists analyze multi-view mammograms more effectively. More specifically, the MSMV-Swin framework leverages the Segment Anything Model (SAM) to isolate the breast lobe, reducing background noise and enabling comprehensive feature extraction. The multi-scale nature of the proposed MSMV-Swin framework accounts for tumor-specific regions as well as the spatial characteristics of tissues surrounding the tumor, capturing both localized and contextual information. The integration of contextual and localized data ensures that MSMV-Swin's outputs align with the way radiologists interpret mammograms, fostering better human-AI interaction and trust. A hybrid fusion structure is then designed to ensure robustness against missing views, a common occurrence in clinical practice when only a single mammogram view is available.
ECG-EmotionNet: Nested Mixture of Expert (NMoE) Adaptation of ECG-Foundation Model for Driver Emotion Recognition
Mar 03, 2025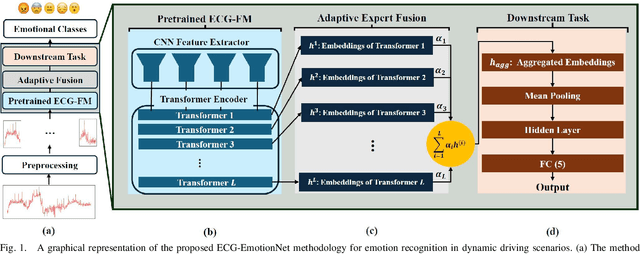
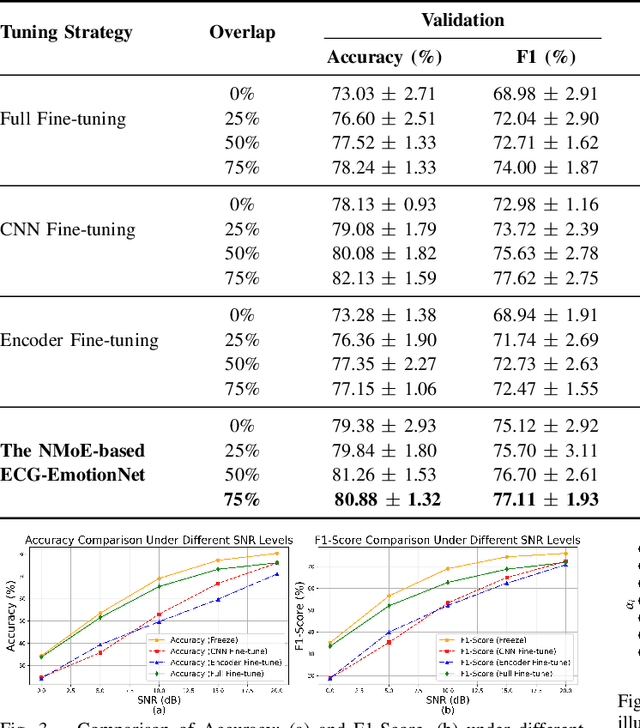
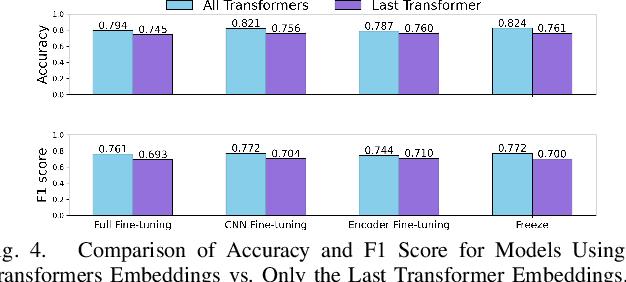
Driver emotion recognition plays a crucial role in driver monitoring systems, enhancing human-autonomy interactions and the trustworthiness of Autonomous Driving (AD). Various physiological and behavioural modalities have been explored for this purpose, with Electrocardiogram (ECG) emerging as a standout choice for real-time emotion monitoring, particularly in dynamic and unpredictable driving conditions. Existing methods, however, often rely on multi-channel ECG signals recorded under static conditions, limiting their applicability in real-world dynamic driving scenarios. To address this limitation, the paper introduces ECG-EmotionNet, a novel architecture designed specifically for emotion recognition in dynamic driving environments. ECG-EmotionNet is constructed by adapting a recently introduced ECG Foundation Model (FM) and uniquely employs single-channel ECG signals, ensuring both robust generalizability and computational efficiency. Unlike conventional adaptation methods such as full fine-tuning, linear probing, or low-rank adaptation, we propose an intuitively pleasing alternative, referred to as the nested Mixture of Experts (MoE) adaptation. More precisely, each transformer layer of the underlying FM is treated as a separate expert, with embeddings extracted from these experts fused using trainable weights within a gating mechanism. This approach enhances the representation of both global and local ECG features, leading to a 6% improvement in accuracy and a 7% increase in the F1 score, all while maintaining computational efficiency. The effectiveness of the proposed ECG-EmotionNet architecture is evaluated using a recently introduced and challenging driver emotion monitoring dataset.
BAD: Bidirectional Auto-regressive Diffusion for Text-to-Motion Generation
Sep 17, 2024



Autoregressive models excel in modeling sequential dependencies by enforcing causal constraints, yet they struggle to capture complex bidirectional patterns due to their unidirectional nature. In contrast, mask-based models leverage bidirectional context, enabling richer dependency modeling. However, they often assume token independence during prediction, which undermines the modeling of sequential dependencies. Additionally, the corruption of sequences through masking or absorption can introduce unnatural distortions, complicating the learning process. To address these issues, we propose Bidirectional Autoregressive Diffusion (BAD), a novel approach that unifies the strengths of autoregressive and mask-based generative models. BAD utilizes a permutation-based corruption technique that preserves the natural sequence structure while enforcing causal dependencies through randomized ordering, enabling the effective capture of both sequential and bidirectional relationships. Comprehensive experiments show that BAD outperforms autoregressive and mask-based models in text-to-motion generation, suggesting a novel pre-training strategy for sequence modeling. The codebase for BAD is available on https://github.com/RohollahHS/BAD.
Leveraging Foundation Models for Efficient Federated Learning in Resource-restricted Edge Networks
Sep 14, 2024


Recently pre-trained Foundation Models (FMs) have been combined with Federated Learning (FL) to improve training of downstream tasks while preserving privacy. However, deploying FMs over edge networks with resource-constrained Internet of Things (IoT) devices is under-explored. This paper proposes a novel framework, namely, Federated Distilling knowledge to Prompt (FedD2P), for leveraging the robust representation abilities of a vision-language FM without deploying it locally on edge devices. This framework distills the aggregated knowledge of IoT devices to a prompt generator to efficiently adapt the frozen FM for downstream tasks. To eliminate the dependency on a public dataset, our framework leverages perclass local knowledge from IoT devices and linguistic descriptions of classes to train the prompt generator. Our experiments on diverse image classification datasets CIFAR, OxfordPets, SVHN, EuroSAT, and DTD show that FedD2P outperforms the baselines in terms of model performance.
Self-Prompting Polyp Segmentation in Colonoscopy using Hybrid Yolo-SAM 2 Model
Sep 14, 2024



Early diagnosis and treatment of polyps during colonoscopy are essential for reducing the incidence and mortality of Colorectal Cancer (CRC). However, the variability in polyp characteristics and the presence of artifacts in colonoscopy images and videos pose significant challenges for accurate and efficient polyp detection and segmentation. This paper presents a novel approach to polyp segmentation by integrating the Segment Anything Model (SAM 2) with the YOLOv8 model. Our method leverages YOLOv8's bounding box predictions to autonomously generate input prompts for SAM 2, thereby reducing the need for manual annotations. We conducted exhaustive tests on five benchmark colonoscopy image datasets and two colonoscopy video datasets, demonstrating that our method exceeds state-of-the-art models in both image and video segmentation tasks. Notably, our approach achieves high segmentation accuracy using only bounding box annotations, significantly reducing annotation time and effort. This advancement holds promise for enhancing the efficiency and scalability of polyp detection in clinical settings https://github.com/sajjad-sh33/YOLO_SAM2.