 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNebulaFL: Effective Asynchronous Federated Learning for JointCloud Computing
Dec 06, 2024With advancements in AI infrastructure and Trusted Execution Environment (TEE) technology, Federated Learning as a Service (FLaaS) through JointCloud Computing (JCC) is promising to break through the resource constraints caused by heterogeneous edge devices in the traditional Federated Learning (FL) paradigm. Specifically, with the protection from TEE, data owners can achieve efficient model training with high-performance AI services in the cloud. By providing additional FL services, cloud service providers can achieve collaborative learning among data owners. However, FLaaS still faces three challenges, i.e., i) low training performance caused by heterogeneous data among data owners, ii) high communication overhead among different clouds (i.e., data centers), and iii) lack of efficient resource scheduling strategies to balance training time and cost. To address these challenges, this paper presents a novel asynchronous FL approach named NebulaFL for collaborative model training among multiple clouds. To address data heterogeneity issues, NebulaFL adopts a version control-based asynchronous FL training scheme in each data center to balance training time among data owners. To reduce communication overhead, NebulaFL adopts a decentralized model rotation mechanism to achieve effective knowledge sharing among data centers. To balance training time and cost, NebulaFL integrates a reward-guided strategy for data owners selection and resource scheduling. The experimental results demonstrate that, compared to the state-of-the-art FL methods, NebulaFL can achieve up to 5.71\% accuracy improvement. In addition, NebulaFL can reduce up to 50% communication overhead and 61.94% costs under a target accuracy.
StyleTex: Style Image-Guided Texture Generation for 3D Models
Nov 01, 2024



Style-guided texture generation aims to generate a texture that is harmonious with both the style of the reference image and the geometry of the input mesh, given a reference style image and a 3D mesh with its text description. Although diffusion-based 3D texture generation methods, such as distillation sampling, have numerous promising applications in stylized games and films, it requires addressing two challenges: 1) decouple style and content completely from the reference image for 3D models, and 2) align the generated texture with the color tone, style of the reference image, and the given text prompt. To this end, we introduce StyleTex, an innovative diffusion-model-based framework for creating stylized textures for 3D models. Our key insight is to decouple style information from the reference image while disregarding content in diffusion-based distillation sampling. Specifically, given a reference image, we first decompose its style feature from the image CLIP embedding by subtracting the embedding's orthogonal projection in the direction of the content feature, which is represented by a text CLIP embedding. Our novel approach to disentangling the reference image's style and content information allows us to generate distinct style and content features. We then inject the style feature into the cross-attention mechanism to incorporate it into the generation process, while utilizing the content feature as a negative prompt to further dissociate content information. Finally, we incorporate these strategies into StyleTex to obtain stylized textures. The resulting textures generated by StyleTex retain the style of the reference image, while also aligning with the text prompts and intrinsic details of the given 3D mesh. Quantitative and qualitative experiments show that our method outperforms existing baseline methods by a significant margin.
DreamMat: High-quality PBR Material Generation with Geometry- and Light-aware Diffusion Models
May 27, 20242D diffusion model, which often contains unwanted baked-in shading effects and results in unrealistic rendering effects in the downstream applications. Generating Physically Based Rendering (PBR) materials instead of just RGB textures would be a promising solution. However, directly distilling the PBR material parameters from 2D diffusion models still suffers from incorrect material decomposition, such as baked-in shading effects in albedo. We introduce DreamMat, an innovative approach to resolve the aforementioned problem, to generate high-quality PBR materials from text descriptions. We find out that the main reason for the incorrect material distillation is that large-scale 2D diffusion models are only trained to generate final shading colors, resulting in insufficient constraints on material decomposition during distillation. To tackle this problem, we first finetune a new light-aware 2D diffusion model to condition on a given lighting environment and generate the shading results on this specific lighting condition. Then, by applying the same environment lights in the material distillation, DreamMat can generate high-quality PBR materials that are not only consistent with the given geometry but also free from any baked-in shading effects in albedo. Extensive experiments demonstrate that the materials produced through our methods exhibit greater visual appeal to users and achieve significantly superior rendering quality compared to baseline methods, which are preferable for downstream tasks such as game and film production.
A Reevaluation of Event Extraction: Past, Present, and Future Challenges
Nov 16, 2023



Event extraction has attracted much attention in recent years due to its potential for many applications. However, recent studies observe some evaluation challenges, suggesting that reported scores might not reflect the true performance. In this work, we first identify and discuss these evaluation challenges, including the unfair comparisons resulting from different assumptions about data or different data preprocessing steps, the incompleteness of the current evaluation framework leading to potential dataset bias or data split bias, and low reproducibility of prior studies. To address these challenges, we propose TextEE, a standardized, fair, and reproducible benchmark for event extraction. TextEE contains standardized data preprocessing scripts and splits for more than ten datasets across different domains. In addition, we aggregate and re-implement over ten event extraction approaches published in recent years and conduct a comprehensive reevaluation. Finally, we explore the capability of large language models in event extraction and discuss some future challenges. We expect TextEE will serve as a reliable benchmark for event extraction, facilitating future research in the field.
AMPERE: AMR-Aware Prefix for Generation-Based Event Argument Extraction Model
May 26, 2023



Event argument extraction (EAE) identifies event arguments and their specific roles for a given event. Recent advancement in generation-based EAE models has shown great performance and generalizability over classification-based models. However, existing generation-based EAE models mostly focus on problem re-formulation and prompt design, without incorporating additional information that has been shown to be effective for classification-based models, such as the abstract meaning representation (AMR) of the input passages. Incorporating such information into generation-based models is challenging due to the heterogeneous nature of the natural language form prevalently used in generation-based models and the structured form of AMRs. In this work, we study strategies to incorporate AMR into generation-based EAE models. We propose AMPERE, which generates AMR-aware prefixes for every layer of the generation model. Thus, the prefix introduces AMR information to the generation-based EAE model and then improves the generation. We also introduce an adjusted copy mechanism to AMPERE to help overcome potential noises brought by the AMR graph. Comprehensive experiments and analyses on ACE2005 and ERE datasets show that AMPERE can get 4% - 10% absolute F1 score improvements with reduced training data and it is in general powerful across different training sizes.
Manual Evaluation Matters: Reviewing Test Protocols of Distantly Supervised Relation Extraction
May 20, 2021
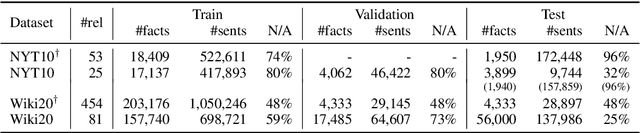

Distantly supervised (DS) relation extraction (RE) has attracted much attention in the past few years as it can utilize large-scale auto-labeled data. However, its evaluation has long been a problem: previous works either took costly and inconsistent methods to manually examine a small sample of model predictions, or directly test models on auto-labeled data -- which, by our check, produce as much as 53% wrong labels at the entity pair level in the popular NYT10 dataset. This problem has not only led to inaccurate evaluation, but also made it hard to understand where we are and what's left to improve in the research of DS-RE. To evaluate DS-RE models in a more credible way, we build manually-annotated test sets for two DS-RE datasets, NYT10 and Wiki20, and thoroughly evaluate several competitive models, especially the latest pre-trained ones. The experimental results show that the manual evaluation can indicate very different conclusions from automatic ones, especially some unexpected observations, e.g., pre-trained models can achieve dominating performance while being more susceptible to false-positives compared to previous methods. We hope that both our manual test sets and novel observations can help advance future DS-RE research.