 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Noticeable Difference Modeling for Deep Visual Features
Jan 29, 2026Deep visual features are increasingly used as the interface in vision systems, motivating the need to describe feature characteristics and control feature quality for machine perception. Just noticeable difference (JND) characterizes the maximum imperceptible distortion for images under human or machine vision. Extending it to deep visual features naturally meets the above demand by providing a task-aligned tolerance boundary in feature space, offering a practical reference for controlling feature quality under constrained resources. We propose FeatJND, a task-aligned JND formulation that predicts the maximum tolerable per-feature perturbation map while preserving downstream task performance. We propose a FeatJND estimator at standardized split points and validate it across image classification, detection, and instance segmentation. Under matched distortion strength, FeatJND-based distortions consistently preserve higher task performance than unstructured Gaussian perturbations, and attribution visualizations suggest FeatJND can suppress non-critical feature regions. As an application, we further apply FeatJND to token-wise dynamic quantization and show that FeatJND-guided step-size allocation yields clear gains over random step-size permutation and global uniform step size under the same noise budget. Our code will be released after publication.
RoamScene3D: Immersive Text-to-3D Scene Generation via Adaptive Object-aware Roaming
Jan 27, 2026Generating immersive 3D scenes from texts is a core task in computer vision, crucial for applications in virtual reality and game development. Despite the promise of leveraging 2D diffusion priors, existing methods suffer from spatial blindness and rely on predefined trajectories that fail to exploit the inner relationships among salient objects. Consequently, these approaches are unable to comprehend the semantic layout, preventing them from exploring the scene adaptively to infer occluded content. Moreover, current inpainting models operate in 2D image space, struggling to plausibly fill holes caused by camera motion. To address these limitations, we propose RoamScene3D, a novel framework that bridges the gap between semantic guidance and spatial generation. Our method reasons about the semantic relations among objects and produces consistent and photorealistic scenes. Specifically, we employ a vision-language model (VLM) to construct a scene graph that encodes object relations, guiding the camera to perceive salient object boundaries and plan an adaptive roaming trajectory. Furthermore, to mitigate the limitations of static 2D priors, we introduce a Motion-Injected Inpainting model that is fine-tuned on a synthetic panoramic dataset integrating authentic camera trajectories, making it adaptive to camera motion. Extensive experiments demonstrate that with semantic reasoning and geometric constraints, our method significantly outperforms state-of-the-art approaches in producing consistent and photorealistic scenes. Our code is available at https://github.com/JS-CHU/RoamScene3D.
Performance-guided Reinforced Active Learning for Object Detection
Jan 22, 2026Active learning (AL) strategies aim to train high-performance models with minimal labeling efforts, only selecting the most informative instances for annotation. Current approaches to evaluating data informativeness predominantly focus on the data's distribution or intrinsic information content and do not directly correlate with downstream task performance, such as mean average precision (mAP) in object detection. Thus, we propose Performance-guided (i.e. mAP-guided) Reinforced Active Learning for Object Detection (MGRAL), a novel approach that leverages the concept of expected model output changes as informativeness. To address the combinatorial explosion challenge of batch sample selection and the non-differentiable correlation between model performance and selected batches, MGRAL skillfully employs a reinforcement learning-based sampling agent that optimizes selection using policy gradient with mAP improvement as reward. Moreover, to reduce the computational overhead of mAP estimation with unlabeled samples, MGRAL utilizes an unsupervised way with fast look-up tables, ensuring feasible deployment. We evaluate MGRAL's active learning performance on detection tasks over PASCAL VOC and COCO benchmarks. Our approach demonstrates the highest AL curve with convincing visualizations, establishing a new paradigm in reinforcement learning-driven active object detection.
Video Reality Test: Can AI-Generated ASMR Videos fool VLMs and Humans?
Dec 18, 2025Recent advances in video generation have produced vivid content that are often indistinguishable from real videos, making AI-generated video detection an emerging societal challenge. Prior AIGC detection benchmarks mostly evaluate video without audio, target broad narrative domains, and focus on classification solely. Yet it remains unclear whether state-of-the-art video generation models can produce immersive, audio-paired videos that reliably deceive humans and VLMs. To this end, we introduce Video Reality Test, an ASMR-sourced video benchmark suite for testing perceptual realism under tight audio-visual coupling, featuring the following dimensions: (i) Immersive ASMR video-audio sources. Built on carefully curated real ASMR videos, the benchmark targets fine-grained action-object interactions with diversity across objects, actions, and backgrounds. (ii) Peer-Review evaluation. An adversarial creator-reviewer protocol where video generation models act as creators aiming to fool reviewers, while VLMs serve as reviewers seeking to identify fakeness. Our experimental findings show: The best creator Veo3.1-Fast even fools most VLMs: the strongest reviewer (Gemini 2.5-Pro) achieves only 56% accuracy (random 50%), far below that of human experts (81.25%). Adding audio improves real-fake discrimination, yet superficial cues such as watermarks can still significantly mislead models. These findings delineate the current boundary of video generation realism and expose limitations of VLMs in perceptual fidelity and audio-visual consistency. Our code is available at https://github.com/video-reality-test/video-reality-test.
What Happens Next? Next Scene Prediction with a Unified Video Model
Dec 15, 2025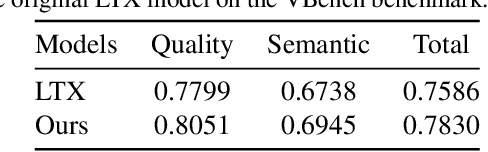
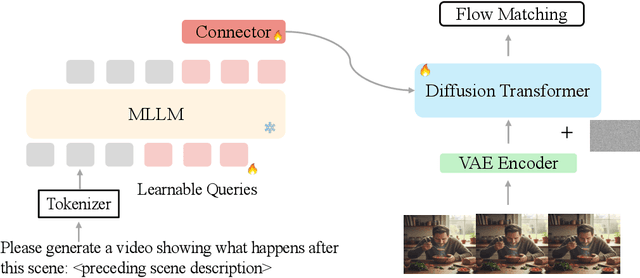
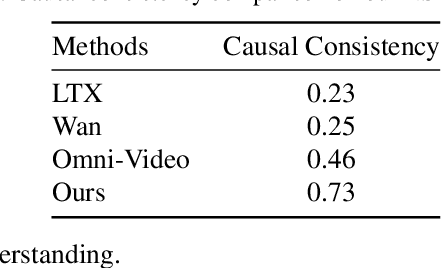
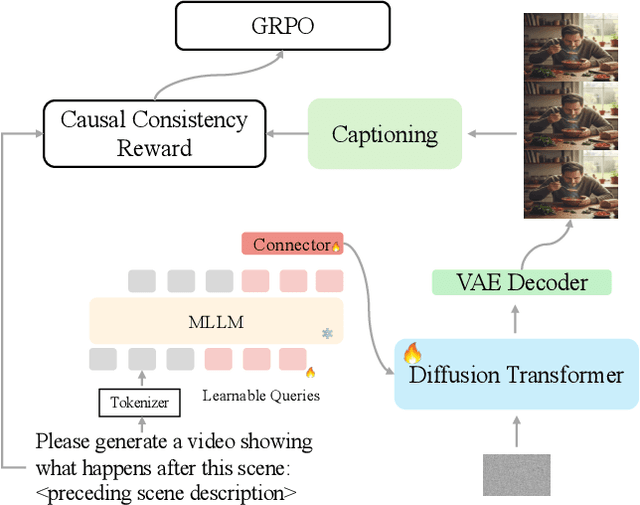
Recent unified models for joint understanding and generation have significantly advanced visual generation capabilities. However, their focus on conventional tasks like text-to-video generation has left the temporal reasoning potential of unified models largely underexplored. To address this gap, we introduce Next Scene Prediction (NSP), a new task that pushes unified video models toward temporal and causal reasoning. Unlike text-to-video generation, NSP requires predicting plausible futures from preceding context, demanding deeper understanding and reasoning. To tackle this task, we propose a unified framework combining Qwen-VL for comprehension and LTX for synthesis, bridged by a latent query embedding and a connector module. This model is trained in three stages on our newly curated, large-scale NSP dataset: text-to-video pre-training, supervised fine-tuning, and reinforcement learning (via GRPO) with our proposed causal consistency reward. Experiments demonstrate our model achieves state-of-the-art performance on our benchmark, advancing the capability of generalist multimodal systems to anticipate what happens next.
VIDEOP2R: Video Understanding from Perception to Reasoning
Nov 14, 2025Reinforcement fine-tuning (RFT), a two-stage framework consisting of supervised fine-tuning (SFT) and reinforcement learning (RL) has shown promising results on improving reasoning ability of large language models (LLMs). Yet extending RFT to large video language models (LVLMs) remains challenging. We propose VideoP2R, a novel process-aware video RFT framework that enhances video reasoning by modeling perception and reasoning as distinct processes. In the SFT stage, we develop a three-step pipeline to generate VideoP2R-CoT-162K, a high-quality, process-aware chain-of-thought (CoT) dataset for perception and reasoning. In the RL stage, we introduce a novel process-aware group relative policy optimization (PA-GRPO) algorithm that supplies separate rewards for perception and reasoning. Extensive experiments show that VideoP2R achieves state-of-the-art (SotA) performance on six out of seven video reasoning and understanding benchmarks. Ablation studies further confirm the effectiveness of our process-aware modeling and PA-GRPO and demonstrate that model's perception output is information-sufficient for downstream reasoning.
Hyperbolic Hierarchical Alignment Reasoning Network for Text-3D Retrieval
Nov 14, 2025With the daily influx of 3D data on the internet, text-3D retrieval has gained increasing attention. However, current methods face two major challenges: Hierarchy Representation Collapse (HRC) and Redundancy-Induced Saliency Dilution (RISD). HRC compresses abstract-to-specific and whole-to-part hierarchies in Euclidean embeddings, while RISD averages noisy fragments, obscuring critical semantic cues and diminishing the model's ability to distinguish hard negatives. To address these challenges, we introduce the Hyperbolic Hierarchical Alignment Reasoning Network (H$^{2}$ARN) for text-3D retrieval. H$^{2}$ARN embeds both text and 3D data in a Lorentz-model hyperbolic space, where exponential volume growth inherently preserves hierarchical distances. A hierarchical ordering loss constructs a shrinking entailment cone around each text vector, ensuring that the matched 3D instance falls within the cone, while an instance-level contrastive loss jointly enforces separation from non-matching samples. To tackle RISD, we propose a contribution-aware hyperbolic aggregation module that leverages Lorentzian distance to assess the relevance of each local feature and applies contribution-weighted aggregation guided by hyperbolic geometry, enhancing discriminative regions while suppressing redundancy without additional supervision. We also release the expanded T3DR-HIT v2 benchmark, which contains 8,935 text-to-3D pairs, 2.6 times the original size, covering both fine-grained cultural artefacts and complex indoor scenes. Our codes are available at https://github.com/liwrui/H2ARN.
Human-in-the-loop Online Rejection Sampling for Robotic Manipulation
Oct 30, 2025Reinforcement learning (RL) is widely used to produce robust robotic manipulation policies, but fine-tuning vision-language-action (VLA) models with RL can be unstable due to inaccurate value estimates and sparse supervision at intermediate steps. In contrast, imitation learning (IL) is easy to train but often underperforms due to its offline nature. In this paper, we propose Hi-ORS, a simple yet effective post-training method that utilizes rejection sampling to achieve both training stability and high robustness. Hi-ORS stabilizes value estimation by filtering out negatively rewarded samples during online fine-tuning, and adopts a reward-weighted supervised training objective to provide dense intermediate-step supervision. For systematic study, we develop an asynchronous inference-training framework that supports flexible online human-in-the-loop corrections, which serve as explicit guidance for learning error-recovery behaviors. Across three real-world tasks and two embodiments, Hi-ORS fine-tunes a pi-base policy to master contact-rich manipulation in just 1.5 hours of real-world training, outperforming RL and IL baselines by a substantial margin in both effectiveness and efficiency. Notably, the fine-tuned policy exhibits strong test-time scalability by reliably executing complex error-recovery behaviors to achieve better performance.
GTR-Bench: Evaluating Geo-Temporal Reasoning in Vision-Language Models
Oct 09, 2025



Recently spatial-temporal intelligence of Visual-Language Models (VLMs) has attracted much attention due to its importance for Autonomous Driving, Embodied AI and General Artificial Intelligence. Existing spatial-temporal benchmarks mainly focus on egocentric perspective reasoning with images/video context, or geographic perspective reasoning with graphics context (eg. a map), thus fail to assess VLMs' geographic spatial-temporal intelligence with both images/video and graphics context, which is important for areas like traffic management and emergency response. To address the gaps, we introduce Geo-Temporal Reasoning benchmark (GTR-Bench), a novel challenge for geographic temporal reasoning of moving targets in a large-scale camera network. GTR-Bench is more challenging as it requires multiple perspective switches between maps and videos, joint reasoning across multiple videos with non-overlapping fields of view, and inference over spatial-temporal regions that are unobserved by any video context. Evaluations of more than 10 popular VLMs on GTR-Bench demonstrate that even the best proprietary model, Gemini-2.5-Pro (34.9%), significantly lags behind human performance (78.61%) on geo-temporal reasoning. Moreover, our comprehensive analysis on GTR-Bench reveals three primary deficiencies of current models for geo-temporal reasoning. (1) VLMs' reasoning is impaired by an imbalanced utilization of spatial-temporal context. (2) VLMs are weak in temporal forecasting, which leads to worse performance on temporal-emphasized tasks than on spatial-emphasized tasks. (3) VLMs lack the proficiency to comprehend or align the map data with multi-view video inputs. We believe GTR-Bench offers valuable insights and opens up new opportunities for research and applications in spatial-temporal intelligence. Benchmark and code will be released at https://github.com/X-Luffy/GTR-Bench.
Language-Instructed Reasoning for Group Activity Detection via Multimodal Large Language Model
Sep 19, 2025Group activity detection (GAD) aims to simultaneously identify group members and categorize their collective activities within video sequences. Existing deep learning-based methods develop specialized architectures (e.g., transformer networks) to model the dynamics of individual roles and semantic dependencies between individuals and groups. However, they rely solely on implicit pattern recognition from visual features and struggle with contextual reasoning and explainability. In this work, we propose LIR-GAD, a novel framework of language-instructed reasoning for GAD via Multimodal Large Language Model (MLLM). Our approach expand the original vocabulary of MLLM by introducing an activity-level <ACT> token and multiple cluster-specific <GROUP> tokens. We process video frames alongside two specially designed tokens and language instructions, which are then integrated into the MLLM. The pretrained commonsense knowledge embedded in the MLLM enables the <ACT> token and <GROUP> tokens to effectively capture the semantic information of collective activities and learn distinct representational features of different groups, respectively. Also, we introduce a multi-label classification loss to further enhance the <ACT> token's ability to learn discriminative semantic representations. Then, we design a Multimodal Dual-Alignment Fusion (MDAF) module that integrates MLLM's hidden embeddings corresponding to the designed tokens with visual features, significantly enhancing the performance of GAD. Both quantitative and qualitative experiments demonstrate the superior performance of our proposed method in GAD taks.