 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLL-E: Video LLM Embeddings for Retrieval
Apr 13, 2026Video Large Language Models (VideoLLMs) excel at video understanding tasks where outputs are textual, such as Video Question Answering and Video Captioning. However, they underperform specialized embedding-based models in Retrieval tasks, such as Text-toVideo Retrieval and Moment Retrieval. We introduce ViLL-E (Video-LLM-Embed), a unified VideoLLM architecture endowed with a novel embedding generation mechanism that allows the model to "think longer" for complex videos and stop early for easy ones. We train this model with a three-stage training methodology combining generative and contrastive learning: initial large-scale pre-training with video-caption pairs; followed by continual training on a smaller, detailed-caption dataset; and concluding with task-specific fine-tuning on a novel multi-task dataset covering Video QA, Temporal Localization, Video Retrieval, and Video-Text Matching. Our model significantly improves temporal localization (on avg. 7% over other VideoLLMs) and video retrieval (up to 4% over dual encoder models), achieving performance comparable to state-of-the-art specialized embedding models while remaining competitive on VideoQA tasks. Furthermore, our joint contrastive-generative training unlocks new zero-shot capabilities, significantly outperforming state-of-the-art methods in composed video retrieval (+5% over SotA) and retrieval from long text (+2% over SotA).
VIRTUE: Versatile Video Retrieval Through Unified Embeddings
Jan 17, 2026Modern video retrieval systems are expected to handle diverse tasks ranging from corpus-level retrieval and fine-grained moment localization to flexible multimodal querying. Specialized architectures achieve strong retrieval performance by training modality-specific encoders on massive datasets, but they lack the ability to process composed multimodal queries. In contrast, multimodal LLM (MLLM)-based methods support rich multimodal search but their retrieval performance remains well below that of specialized systems. We present VIRTUE, an MLLM-based versatile video retrieval framework that integrates corpus and moment-level retrieval capabilities while accommodating composed multimodal queries within a single architecture. We use contrastive alignment of visual and textual embeddings generated using a shared MLLM backbone to facilitate efficient embedding-based candidate search. Our embedding model, trained efficiently using low-rank adaptation (LoRA) on 700K paired visual-text data samples, surpasses other MLLM-based methods on zero-shot video retrieval tasks. Additionally, we demonstrate that the same model can be adapted without further training to achieve competitive results on zero-shot moment retrieval, and state of the art results for zero-shot composed video retrieval. With additional training for reranking candidates identified in the embedding-based search, our model substantially outperforms existing MLLM-based retrieval systems and achieves retrieval performance comparable to state of the art specialized models which are trained on orders of magnitude larger data.
VIDEOP2R: Video Understanding from Perception to Reasoning
Nov 14, 2025Reinforcement fine-tuning (RFT), a two-stage framework consisting of supervised fine-tuning (SFT) and reinforcement learning (RL) has shown promising results on improving reasoning ability of large language models (LLMs). Yet extending RFT to large video language models (LVLMs) remains challenging. We propose VideoP2R, a novel process-aware video RFT framework that enhances video reasoning by modeling perception and reasoning as distinct processes. In the SFT stage, we develop a three-step pipeline to generate VideoP2R-CoT-162K, a high-quality, process-aware chain-of-thought (CoT) dataset for perception and reasoning. In the RL stage, we introduce a novel process-aware group relative policy optimization (PA-GRPO) algorithm that supplies separate rewards for perception and reasoning. Extensive experiments show that VideoP2R achieves state-of-the-art (SotA) performance on six out of seven video reasoning and understanding benchmarks. Ablation studies further confirm the effectiveness of our process-aware modeling and PA-GRPO and demonstrate that model's perception output is information-sufficient for downstream reasoning.
Open Vocabulary Multi-Label Video Classification
Jul 12, 2024



Pre-trained vision-language models (VLMs) have enabled significant progress in open vocabulary computer vision tasks such as image classification, object detection and image segmentation. Some recent works have focused on extending VLMs to open vocabulary single label action classification in videos. However, previous methods fall short in holistic video understanding which requires the ability to simultaneously recognize multiple actions and entities e.g., objects in the video in an open vocabulary setting. We formulate this problem as open vocabulary multilabel video classification and propose a method to adapt a pre-trained VLM such as CLIP to solve this task. We leverage large language models (LLMs) to provide semantic guidance to the VLM about class labels to improve its open vocabulary performance with two key contributions. First, we propose an end-to-end trainable architecture that learns to prompt an LLM to generate soft attributes for the CLIP text-encoder to enable it to recognize novel classes. Second, we integrate a temporal modeling module into CLIP's vision encoder to effectively model the spatio-temporal dynamics of video concepts as well as propose a novel regularized finetuning technique to ensure strong open vocabulary classification performance in the video domain. Our extensive experimentation showcases the efficacy of our approach on multiple benchmark datasets.
VidLA: Video-Language Alignment at Scale
Mar 21, 2024In this paper, we propose VidLA, an approach for video-language alignment at scale. There are two major limitations of previous video-language alignment approaches. First, they do not capture both short-range and long-range temporal dependencies and typically employ complex hierarchical deep network architectures that are hard to integrate with existing pretrained image-text foundation models. To effectively address this limitation, we instead keep the network architecture simple and use a set of data tokens that operate at different temporal resolutions in a hierarchical manner, accounting for the temporally hierarchical nature of videos. By employing a simple two-tower architecture, we are able to initialize our video-language model with pretrained image-text foundation models, thereby boosting the final performance. Second, existing video-language alignment works struggle due to the lack of semantically aligned large-scale training data. To overcome it, we leverage recent LLMs to curate the largest video-language dataset to date with better visual grounding. Furthermore, unlike existing video-text datasets which only contain short clips, our dataset is enriched with video clips of varying durations to aid our temporally hierarchical data tokens in extracting better representations at varying temporal scales. Overall, empirical results show that our proposed approach surpasses state-of-the-art methods on multiple retrieval benchmarks, especially on longer videos, and performs competitively on classification benchmarks.
Where You Are Is Who You Are: User Identification by Matching Statistics
Dec 09, 2015
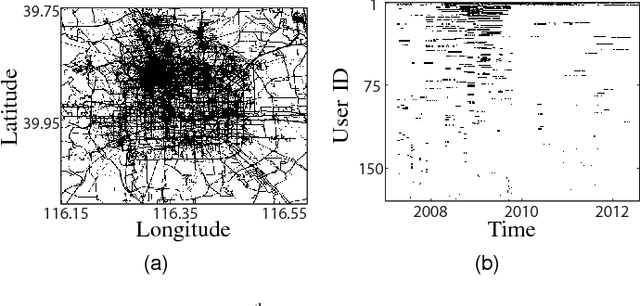
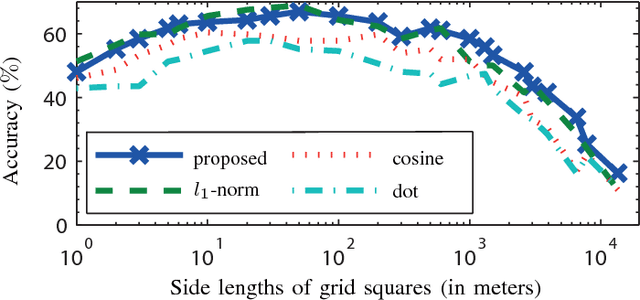
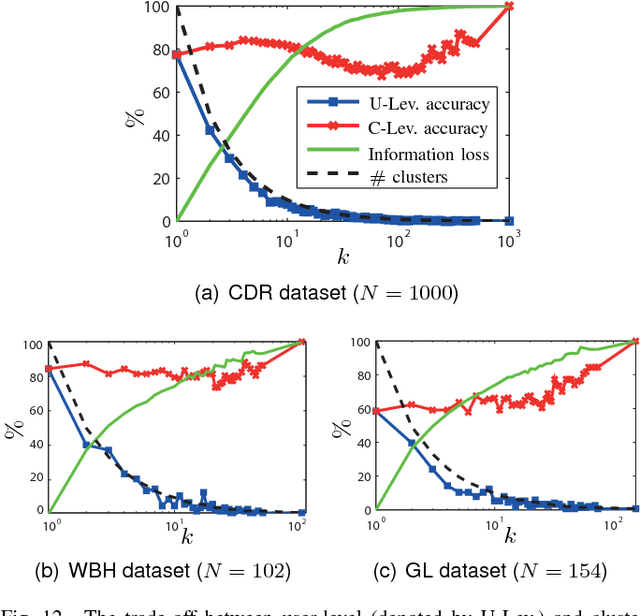
Most users of online services have unique behavioral or usage patterns. These behavioral patterns can be exploited to identify and track users by using only the observed patterns in the behavior. We study the task of identifying users from statistics of their behavioral patterns. Specifically, we focus on the setting in which we are given histograms of users' data collected during two different experiments. We assume that, in the first dataset, the users' identities are anonymized or hidden and that, in the second dataset, their identities are known. We study the task of identifying the users by matching the histograms of their data in the first dataset with the histograms from the second dataset. In recent works, the optimal algorithm for this user identification task is introduced. In this paper, we evaluate the effectiveness of this method on three different types of datasets and in multiple scenarios. Using datasets such as call data records, web browsing histories, and GPS trajectories, we show that a large fraction of users can be easily identified given only histograms of their data; hence these histograms can act as users' fingerprints. We also verify that simultaneous identification of users achieves better performance compared to one-by-one user identification. We show that using the optimal method for identification gives higher identification accuracy than heuristics-based approaches in practical scenarios. The accuracy obtained under this optimal method can thus be used to quantify the maximum level of user identification that is possible in such settings. We show that the key factors affecting the accuracy of the optimal identification algorithm are the duration of the data collection, the number of users in the anonymized dataset, and the resolution of the dataset. We analyze the effectiveness of k-anonymization in resisting user identification attacks on these datasets.
Approximate dynamic programming using fluid and diffusion approximations with applications to power management
Jul 09, 2013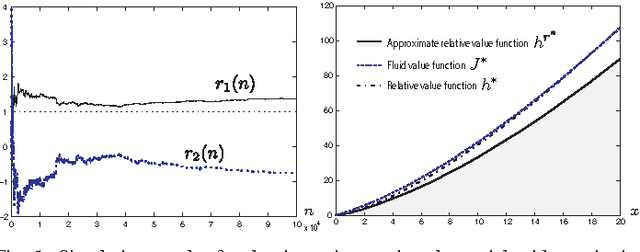
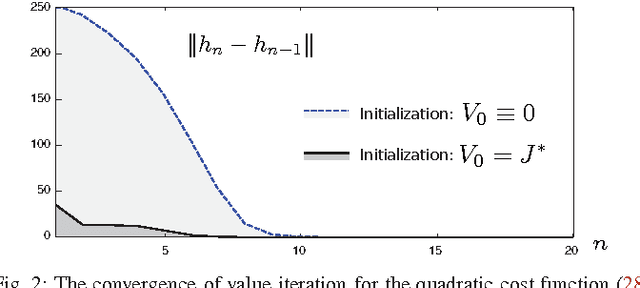
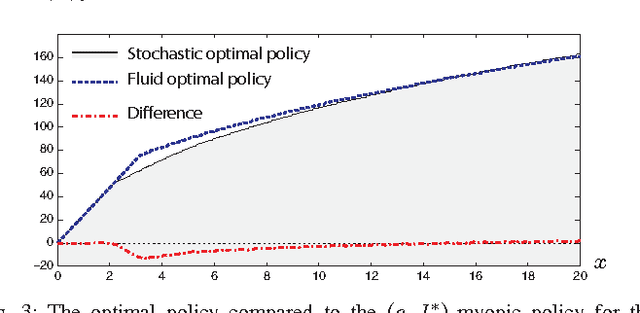
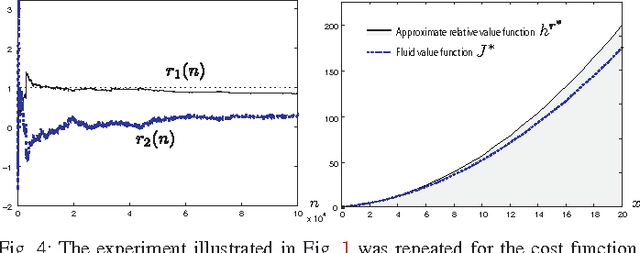
Neuro-dynamic programming is a class of powerful techniques for approximating the solution to dynamic programming equations. In their most computationally attractive formulations, these techniques provide the approximate solution only within a prescribed finite-dimensional function class. Thus, the question that always arises is how should the function class be chosen? The goal of this paper is to propose an approach using the solutions to associated fluid and diffusion approximations. In order to illustrate this approach, the paper focuses on an application to dynamic speed scaling for power management in computer processors.
Sampling and Reconstruction of Spatial Fields using Mobile Sensors
Nov 01, 2012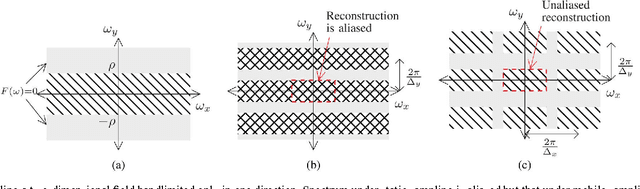
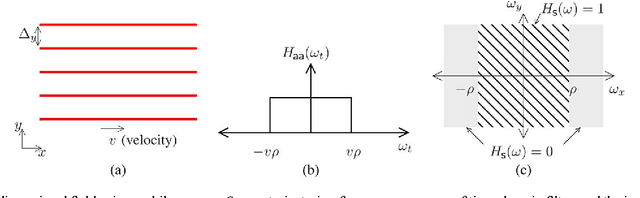
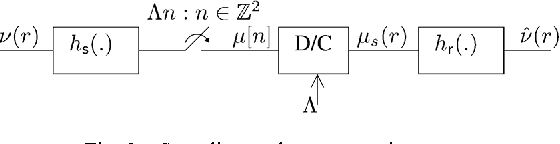
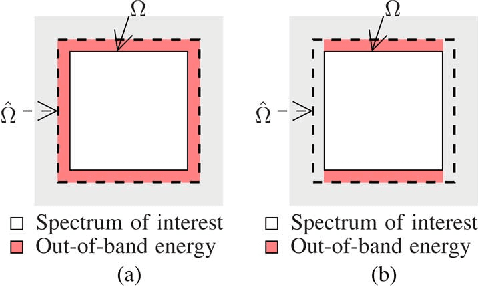
Spatial sampling is traditionally studied in a static setting where static sensors scattered around space take measurements of the spatial field at their locations. In this paper we study the emerging paradigm of sampling and reconstructing spatial fields using sensors that move through space. We show that mobile sensing offers some unique advantages over static sensing in sensing time-invariant bandlimited spatial fields. Since a moving sensor encounters such a spatial field along its path as a time-domain signal, a time-domain anti-aliasing filter can be employed prior to sampling the signal received at the sensor. Such a filtering procedure, when used by a configuration of sensors moving at constant speeds along equispaced parallel lines, leads to a complete suppression of spatial aliasing in the direction of motion of the sensors. We analytically quantify the advantage of using such a sampling scheme over a static sampling scheme by computing the reduction in sampling noise due to the filter. We also analyze the effects of non-uniform sensor speeds on the reconstruction accuracy. Using simulation examples we demonstrate the advantages of mobile sampling over static sampling in practical problems. We extend our analysis to sampling and reconstruction schemes for monitoring time-varying bandlimited fields using mobile sensors. We demonstrate that in some situations we require a lower density of sensors when using a mobile sensing scheme instead of the conventional static sensing scheme. The exact advantage is quantified for a problem of sampling and reconstructing an audio field.
Universal and Composite Hypothesis Testing via Mismatched Divergence
Sep 09, 2010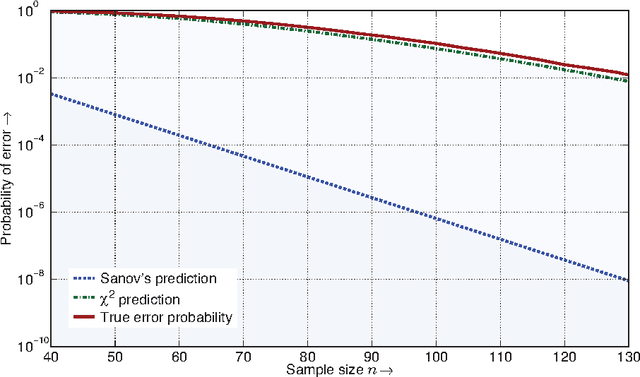
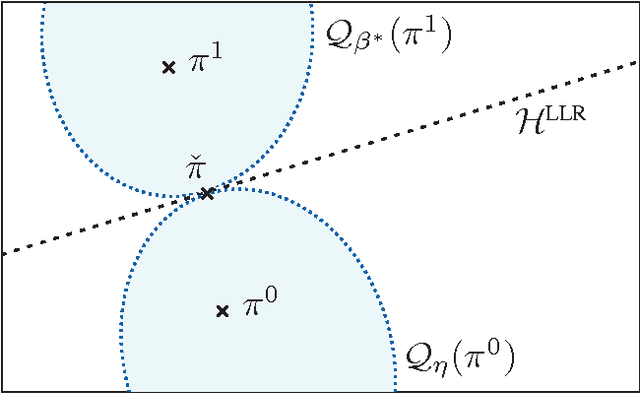
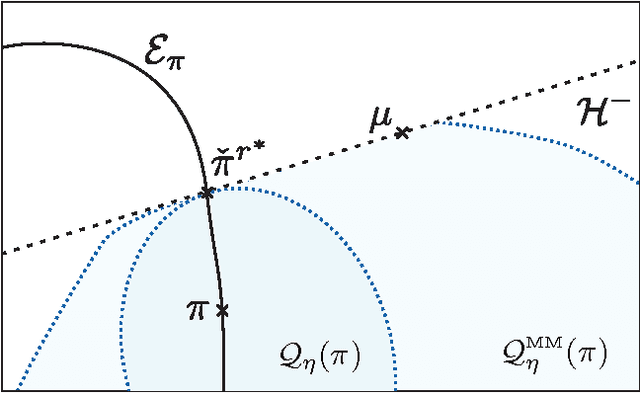
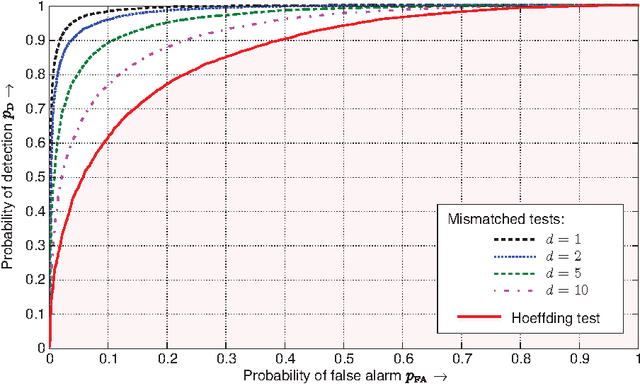
For the universal hypothesis testing problem, where the goal is to decide between the known null hypothesis distribution and some other unknown distribution, Hoeffding proposed a universal test in the nineteen sixties. Hoeffding's universal test statistic can be written in terms of Kullback-Leibler (K-L) divergence between the empirical distribution of the observations and the null hypothesis distribution. In this paper a modification of Hoeffding's test is considered based on a relaxation of the K-L divergence test statistic, referred to as the mismatched divergence. The resulting mismatched test is shown to be a generalized likelihood-ratio test (GLRT) for the case where the alternate distribution lies in a parametric family of the distributions characterized by a finite dimensional parameter, i.e., it is a solution to the corresponding composite hypothesis testing problem. For certain choices of the alternate distribution, it is shown that both the Hoeffding test and the mismatched test have the same asymptotic performance in terms of error exponents. A consequence of this result is that the GLRT is optimal in differentiating a particular distribution from others in an exponential family. It is also shown that the mismatched test has a significant advantage over the Hoeffding test in terms of finite sample size performance. This advantage is due to the difference in the asymptotic variances of the two test statistics under the null hypothesis. In particular, the variance of the K-L divergence grows linearly with the alphabet size, making the test impractical for applications involving large alphabet distributions. The variance of the mismatched divergence on the other hand grows linearly with the dimension of the parameter space, and can hence be controlled through a prudent choice of the function class defining the mismatched divergence.
Algorithms for Dynamic Spectrum Access with Learning for Cognitive Radio
Feb 06, 2010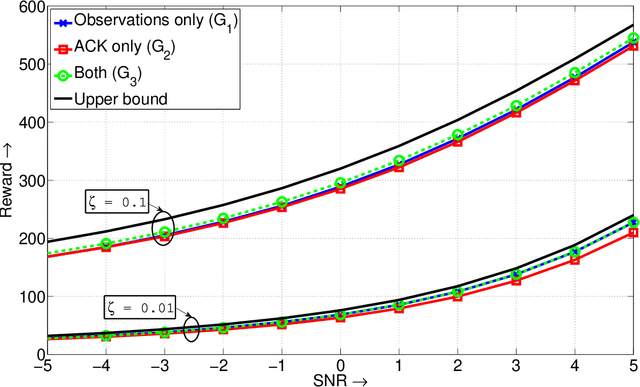
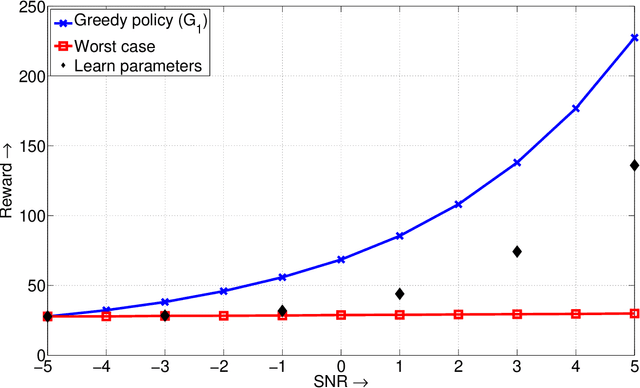
We study the problem of dynamic spectrum sensing and access in cognitive radio systems as a partially observed Markov decision process (POMDP). A group of cognitive users cooperatively tries to exploit vacancies in primary (licensed) channels whose occupancies follow a Markovian evolution. We first consider the scenario where the cognitive users have perfect knowledge of the distribution of the signals they receive from the primary users. For this problem, we obtain a greedy channel selection and access policy that maximizes the instantaneous reward, while satisfying a constraint on the probability of interfering with licensed transmissions. We also derive an analytical universal upper bound on the performance of the optimal policy. Through simulation, we show that our scheme achieves good performance relative to the upper bound and improved performance relative to an existing scheme. We then consider the more practical scenario where the exact distribution of the signal from the primary is unknown. We assume a parametric model for the distribution and develop an algorithm that can learn the true distribution, still guaranteeing the constraint on the interference probability. We show that this algorithm outperforms the naive design that assumes a worst case value for the parameter. We also provide a proof for the convergence of the learning algorithm.