 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu-ACE: Adaptive Cascaded Experts for Educational Response Generation on EduBench
Apr 16, 2026Educational assistants should spend more computation only when the task needs it. This paper rewrites our earlier draft around the system that was actually implemented and archived in the repository: a sample-level 1B to 7B cascade for the shared-8 EduBench benchmark. The final system, Pangu-ACE, uses a 1B tutor-router to produce a draft answer plus routing signals, then either accepts the draft or escalates the sample to a 7B specialist prompt. We also correct a major offline evaluation bug: earlier summaries over-credited some open-form outputs that only satisfied superficial format checks. After CPU-side rescoring from saved prediction JSONL, the full Chinese test archive (7013 samples) shows that cascade_final improves deterministic quality from 0.457 to 0.538 and format validity from 0.707 to 0.866 over the legacy rule_v2 system while accepting 19.7% of requests directly at 1B. Routing is strongly task dependent: IP is accepted by 1B 78.0% of the time, while QG and EC still escalate almost always. The current archived deployment does not yet show latency gains, so the defensible efficiency story is routing selectivity rather than wall-clock speedup. We also package a reproducible artifact-first paper workflow and clarify the remaining external-baseline gap: GPT-5.4 re-judging is implemented locally, but the configured provider endpoint and key are invalid, so final sampled-baseline alignment with GPT-5.4 remains pending infrastructure repair.
Bridging the Micro--Macro Gap: Frequency-Aware Semantic Alignment for Image Manipulation Localization
Apr 14, 2026As generative image editing advances, image manipulation localization (IML) must handle both traditional manipulations with conspicuous forensic artifacts and diffusion-generated edits that appear locally realistic. Existing methods typically rely on either low-level forensic cues or high-level semantics alone, leading to a fundamental micro--macro gap. To bridge this gap, we propose FASA, a unified framework for localizing both traditional and diffusion-generated manipulations. Specifically, we extract manipulation-sensitive frequency cues through an adaptive dual-band DCT module and learn manipulation-aware semantic priors via patch-level contrastive alignment on frozen CLIP representations. We then inject these priors into a hierarchical frequency pathway through a semantic-frequency side adapter for multi-scale feature interaction, and employ a prototype-guided, frequency-gated mask decoder to integrate semantic consistency with boundary-aware localization for tampered region prediction. Extensive experiments on OpenSDI and multiple traditional manipulation benchmarks demonstrate state-of-the-art localization performance, strong cross-generator and cross-dataset generalization, and robust performance under common image degradations.
Geometry-Aware Localized Watermarking for Copyright Protection in Embedding-as-a-Service
Apr 13, 2026Embedding-as-a-Service (EaaS) has become an important semantic infrastructure for natural language and multimedia applications, but it is highly vulnerable to model stealing and copyright infringement. Existing EaaS watermarking methods face a fundamental robustness--utility--verifiability tension: trigger-based methods are fragile to paraphrasing, transformation-based methods are sensitive to dimensional perturbation, and region-based methods may incur false positives due to coincidental geometric affinity. To address this problem, we propose GeoMark, a geometry-aware localized watermarking framework for EaaS copyright protection. GeoMark uses a natural in-manifold embedding as a shared watermark target, constructs geometry-separated anchors with explicit target--anchor margins, and activates watermark injection only within adaptive local neighborhoods. This design decouples where watermarking is triggered from what ownership is attributed to, achieving localized triggering and centralized attribution. Experiments on four benchmark datasets show that GeoMark preserves downstream utility and geometric fidelity while maintaining robust copyright verification under paraphrasing, dimensional perturbation, and CSE (Clustering, Selection, Elimination) attacks, with improved verification stability and low false-positive risk.
OmniSonic: Towards Universal and Holistic Audio Generation from Video and Text
Apr 06, 2026In this paper, we propose Universal Holistic Audio Generation (UniHAGen), a task for synthesizing comprehensive auditory scenes that include both on-screen and off-screen sounds across diverse domains (e.g., ambient events, musical instruments, and human speech). Prior video-conditioned audio generation models typically focus on producing on-screen environmental sounds that correspond to visible sounding events, neglecting off-screen auditory events. While recent holistic joint text-video-to-audio generation models aim to produce auditory scenes with both on- and off-screen sound but they are limited to non-speech sounds, lacking the ability to generate or integrate human speech. To overcome these limitations, we introduce OmniSonic, a flow-matching-based diffusion framework jointly conditioned on video and text. It features a TriAttn-DiT architecture that performs three cross-attention operations to process on-screen environmental sound, off-screen environmental sound, and speech conditions simultaneously, with a Mixture-of-Experts (MoE) gating mechanism that adaptively balances their contributions during generation. Furthermore, we construct UniHAGen-Bench, a new benchmark with over one thousand samples covering three representative on/off-screen speech-environment scenarios. Extensive experiments show that OmniSonic consistently outperforms state-of-the-art approaches on both objective metrics and human evaluations, establishing a strong baseline for universal and holistic audio generation. Project page: https://weiguopian.github.io/OmniSonic_webpage/
REL-SF4PASS: Panoramic Semantic Segmentation with REL Depth Representation and Spherical Fusion
Jan 23, 2026As an important and challenging problem in computer vision, Panoramic Semantic Segmentation (PASS) aims to give complete scene perception based on an ultra-wide angle of view. Most PASS methods often focus on spherical geometry with RGB input or using the depth information in original or HHA format, which does not make full use of panoramic image geometry. To address these shortcomings, we propose REL-SF4PASS with our REL depth representation based on cylindrical coordinate and Spherical-dynamic Multi-Modal Fusion SMMF. REL is made up of Rectified Depth, Elevation-Gained Vertical Inclination Angle, and Lateral Orientation Angle, which fully represents 3D space in cylindrical coordinate style and the surface normal direction. SMMF aims to ensure the diversity of fusion for different panoramic image regions and reduce the breakage of cylinder side surface expansion in ERP projection, which uses different fusion strategies to match the different regions in panoramic images. Experimental results show that REL-SF4PASS considerably improves performance and robustness on popular benchmark, Stanford2D3D Panoramic datasets. It gains 2.35% average mIoU improvement on all 3 folds and reduces the performance variance by approximately 70% when facing 3D disturbance.
What Happens Next? Next Scene Prediction with a Unified Video Model
Dec 15, 2025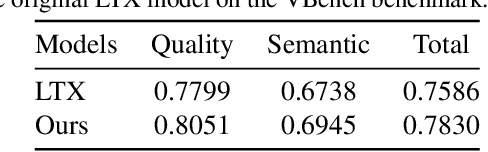
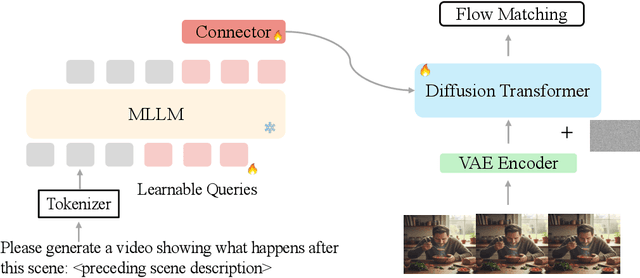
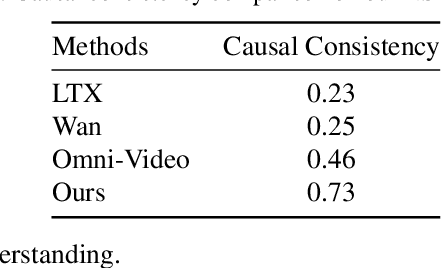
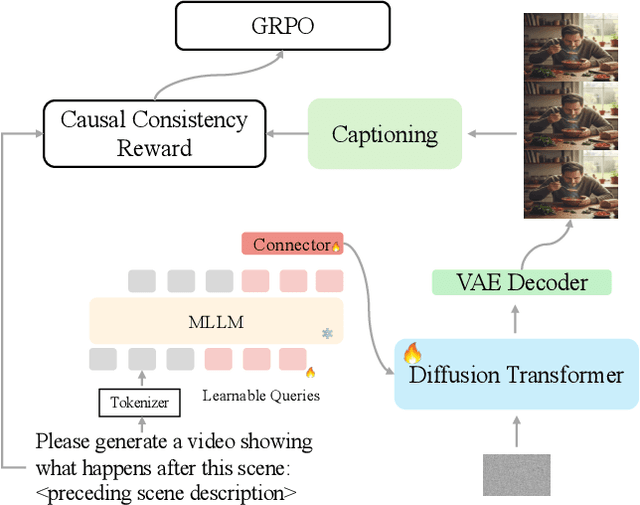
Recent unified models for joint understanding and generation have significantly advanced visual generation capabilities. However, their focus on conventional tasks like text-to-video generation has left the temporal reasoning potential of unified models largely underexplored. To address this gap, we introduce Next Scene Prediction (NSP), a new task that pushes unified video models toward temporal and causal reasoning. Unlike text-to-video generation, NSP requires predicting plausible futures from preceding context, demanding deeper understanding and reasoning. To tackle this task, we propose a unified framework combining Qwen-VL for comprehension and LTX for synthesis, bridged by a latent query embedding and a connector module. This model is trained in three stages on our newly curated, large-scale NSP dataset: text-to-video pre-training, supervised fine-tuning, and reinforcement learning (via GRPO) with our proposed causal consistency reward. Experiments demonstrate our model achieves state-of-the-art performance on our benchmark, advancing the capability of generalist multimodal systems to anticipate what happens next.
Limits To (Machine) Learning
Dec 14, 2025



Machine learning (ML) methods are highly flexible, but their ability to approximate the true data-generating process is fundamentally constrained by finite samples. We characterize a universal lower bound, the Limits-to-Learning Gap (LLG), quantifying the unavoidable discrepancy between a model's empirical fit and the population benchmark. Recovering the true population $R^2$, therefore, requires correcting observed predictive performance by this bound. Using a broad set of variables, including excess returns, yields, credit spreads, and valuation ratios, we find that the implied LLGs are large. This indicates that standard ML approaches can substantially understate true predictability in financial data. We also derive LLG-based refinements to the classic Hansen and Jagannathan (1991) bounds, analyze implications for parameter learning in general-equilibrium settings, and show that the LLG provides a natural mechanism for generating excess volatility.
VIDEOP2R: Video Understanding from Perception to Reasoning
Nov 14, 2025Reinforcement fine-tuning (RFT), a two-stage framework consisting of supervised fine-tuning (SFT) and reinforcement learning (RL) has shown promising results on improving reasoning ability of large language models (LLMs). Yet extending RFT to large video language models (LVLMs) remains challenging. We propose VideoP2R, a novel process-aware video RFT framework that enhances video reasoning by modeling perception and reasoning as distinct processes. In the SFT stage, we develop a three-step pipeline to generate VideoP2R-CoT-162K, a high-quality, process-aware chain-of-thought (CoT) dataset for perception and reasoning. In the RL stage, we introduce a novel process-aware group relative policy optimization (PA-GRPO) algorithm that supplies separate rewards for perception and reasoning. Extensive experiments show that VideoP2R achieves state-of-the-art (SotA) performance on six out of seven video reasoning and understanding benchmarks. Ablation studies further confirm the effectiveness of our process-aware modeling and PA-GRPO and demonstrate that model's perception output is information-sufficient for downstream reasoning.
DyConfidMatch: Dynamic Thresholding and Re-sampling for 3D Semi-supervised Learning
Nov 13, 2024



Semi-supervised learning (SSL) leverages limited labeled and abundant unlabeled data but often faces challenges with data imbalance, especially in 3D contexts. This study investigates class-level confidence as an indicator of learning status in 3D SSL, proposing a novel method that utilizes dynamic thresholding to better use unlabeled data, particularly from underrepresented classes. A re-sampling strategy is also introduced to mitigate bias towards well-represented classes, ensuring equitable class representation. Through extensive experiments in 3D SSL, our method surpasses state-of-the-art counterparts in classification and detection tasks, highlighting its effectiveness in tackling data imbalance. This approach presents a significant advancement in SSL for 3D datasets, providing a robust solution for data imbalance issues.
SAM-Guided Masked Token Prediction for 3D Scene Understanding
Oct 17, 2024



Foundation models have significantly enhanced 2D task performance, and recent works like Bridge3D have successfully applied these models to improve 3D scene understanding through knowledge distillation, marking considerable advancements. Nonetheless, challenges such as the misalignment between 2D and 3D representations and the persistent long-tail distribution in 3D datasets still restrict the effectiveness of knowledge distillation from 2D to 3D using foundation models. To tackle these issues, we introduce a novel SAM-guided tokenization method that seamlessly aligns 3D transformer structures with region-level knowledge distillation, replacing the traditional KNN-based tokenization techniques. Additionally, we implement a group-balanced re-weighting strategy to effectively address the long-tail problem in knowledge distillation. Furthermore, inspired by the recent success of masked feature prediction, our framework incorporates a two-stage masked token prediction process in which the student model predicts both the global embeddings and the token-wise local embeddings derived from the teacher models trained in the first stage. Our methodology has been validated across multiple datasets, including SUN RGB-D, ScanNet, and S3DIS, for tasks like 3D object detection and semantic segmentation. The results demonstrate significant improvements over current State-of-the-art self-supervised methods, establishing new benchmarks in this field.