 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Constraint by Only Support Constraint for Offline Reinforcement Learning
Mar 07, 2025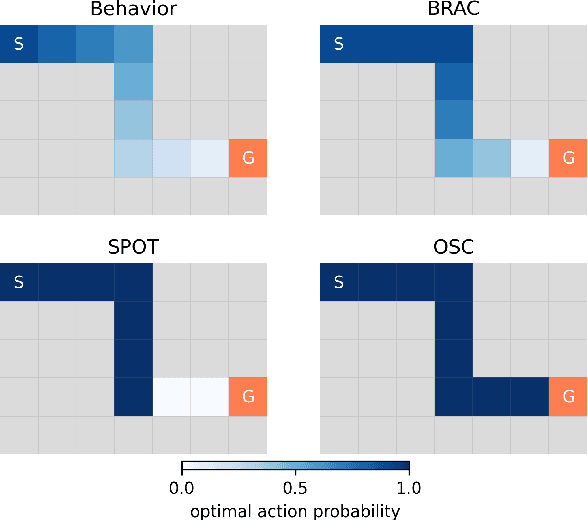
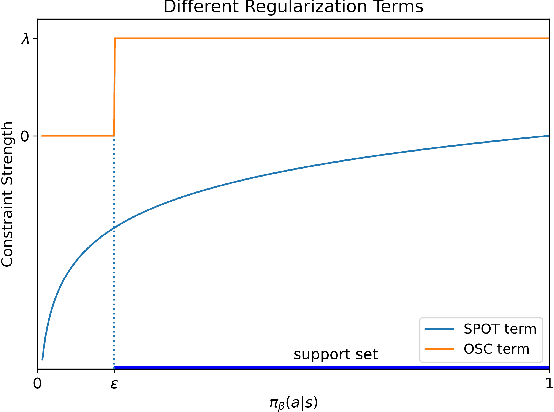

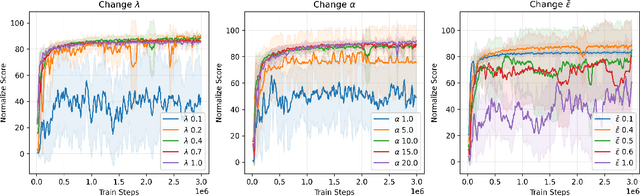
Offline reinforcement learning (RL) aims to optimize a policy by using pre-collected datasets, to maximize cumulative rewards. However, offline reinforcement learning suffers challenges due to the distributional shift between the learned and behavior policies, leading to errors when computing Q-values for out-of-distribution (OOD) actions. To mitigate this issue, policy constraint methods aim to constrain the learned policy's distribution with the distribution of the behavior policy or confine action selection within the support of the behavior policy. However, current policy constraint methods tend to exhibit excessive conservatism, hindering the policy from further surpassing the behavior policy's performance. In this work, we present Only Support Constraint (OSC) which is derived from maximizing the total probability of learned policy in the support of behavior policy, to address the conservatism of policy constraint. OSC presents a regularization term that only restricts policies to the support without imposing extra constraints on actions within the support. Additionally, to fully harness the performance of the new policy constraints, OSC utilizes a diffusion model to effectively characterize the support of behavior policies. Experimental evaluations across a variety of offline RL benchmarks demonstrate that OSC significantly enhances performance, alleviating the challenges associated with distributional shifts and mitigating conservatism of policy constraints. Code is available at https://github.com/MoreanP/OSC.
Intrinsic and Extrinsic Factor Disentanglement for Recommendation in Various Context Scenarios
Mar 05, 2025



In recommender systems, the patterns of user behaviors (e.g., purchase, click) may vary greatly in different contexts (e.g., time and location). This is because user behavior is jointly determined by two types of factors: intrinsic factors, which reflect consistent user preference, and extrinsic factors, which reflect external incentives that may vary in different contexts. Differentiating between intrinsic and extrinsic factors helps learn user behaviors better. However, existing studies have only considered differentiating them from a single, pre-defined context (e.g., time or location), ignoring the fact that a user's extrinsic factors may be influenced by the interplay of various contexts at the same time. In this paper, we propose the Intrinsic-Extrinsic Disentangled Recommendation (IEDR) model, a generic framework that differentiates intrinsic from extrinsic factors considering various contexts simultaneously, enabling more accurate differentiation of factors and hence the improvement of recommendation accuracy. IEDR contains a context-invariant contrastive learning component to capture intrinsic factors, and a disentanglement component to extract extrinsic factors under the interplay of various contexts. The two components work together to achieve effective factor learning. Extensive experiments on real-world datasets demonstrate IEDR's effectiveness in learning disentangled factors and significantly improving recommendation accuracy by up to 4% in NDCG.
A General Optimization Framework for Tackling Distance Constraints in Movable Antenna-Aided Systems
Mar 04, 2025The recently emerged movable antenna (MA) shows great promise in leveraging spatial degrees of freedom to enhance the performance of wireless systems. However, resource allocation in MA-aided systems faces challenges due to the nonconvex and coupled constraints on antenna positions. This paper systematically reveals the challenges posed by the minimum antenna separation distance constraints. Furthermore, we propose a penalty optimization framework for resource allocation under such new constraints for MA-aided systems. Specifically, the proposed framework separates the non-convex and coupled antenna distance constraints from the movable region constraints by introducing auxiliary variables. Subsequently, the resulting problem is efficiently solved by alternating optimization, where the optimization of the original variables resembles that in conventional resource allocation problem while the optimization with respect to the auxiliary variables is achieved in closedform solutions. To illustrate the effectiveness of the proposed framework, we present three case studies: capacity maximization, latency minimization, and regularized zero-forcing precoding. Simulation results demonstrate that the proposed optimization framework consistently outperforms state-of-the-art schemes.
EPEE: Towards Efficient and Effective Foundation Models in Biomedicine
Mar 03, 2025Foundation models, including language models, e.g., GPT, and vision models, e.g., CLIP, have significantly advanced numerous biomedical tasks. Despite these advancements, the high inference latency and the "overthinking" issues in model inference impair the efficiency and effectiveness of foundation models, thus limiting their application in real-time clinical settings. To address these challenges, we proposed EPEE (Entropy- and Patience-based Early Exiting), a novel hybrid strategy designed to improve the inference efficiency of foundation models. The core idea was to leverage the strengths of entropy-based and patience-based early exiting methods to overcome their respective weaknesses. To evaluate EPEE, we conducted experiments on three core biomedical tasks-classification, relation extraction, and event extraction-using four foundation models (BERT, ALBERT, GPT-2, and ViT) across twelve datasets, including clinical notes and medical images. The results showed that EPEE significantly reduced inference time while maintaining or improving accuracy, demonstrating its adaptability to diverse datasets and tasks. EPEE addressed critical barriers to deploying foundation models in healthcare by balancing efficiency and effectiveness. It potentially provided a practical solution for real-time clinical decision-making with foundation models, supporting reliable and efficient workflows.
Hierarchically Tunable 6DMA for Wireless Communication and Sensing: Modeling and Performance Optimization
Mar 03, 2025This paper proposes a new hierarchically tunable six-dimensional movable antenna (HT-6DMA) architecture for base station (BS) in future wireless networks. The HT-6DMA BS consists of multiple antenna arrays that can flexibly move on a spherical surface, with their three-dimensional (3D) positions and 3D rotations/orientations efficiently characterized in the global spherical coordinate system (SCS) and their individual local SCSs, respectively. As a result, the 6DMA system is hierarchically tunable in the sense that each array's global position and local rotation can be separately adjusted in a sequential manner with the other being fixed, thus greatly reducing their design complexity and improving the achievable performance. In particular, we consider an HT-6DMA BS serving multiple single-antenna users in the uplink communication or sensing potential unmanned aerial vehicles (UAVs)/drones in a given airway area. Specifically, for the communication scenario, we aim to maximize the average sum rate of communication users in the long term by optimizing the positions and rotations of all 6DMA arrays at the BS. While for the airway sensing scenario, we maximize the minimum received sensing signal power along the airway by optimizing the 6DMA arrays' positions and rotations along with the BS's transmit covariance matrix. Despite that the formulated problems are both non-convex, we propose efficient solutions to them by exploiting the hierarchical tunability of positions/rotations of 6DMA arrays in our proposed model. Numerical results show that the proposed HT-6DMA design significantly outperforms not only the traditional BS with fixed-position antennas (FPAs), but also the existing 6DMA scheme. Furthermore, it is unveiled that the performance gains of HT-6DMA mostly come from the arrays' global position adjustments on the spherical surface, rather than their local rotation adjustments.
Movable Antenna Aided Multiuser Communications: Antenna Position Optimization Based on Statistical Channel Information
Feb 28, 2025



The movable antenna (MA) technology has attracted great attention recently due to its promising capability in improving wireless channel conditions by flexibly adjusting antenna positions. To reap maximal performance gains of MA systems, existing works mainly focus on MA position optimization to cater to the instantaneous channel state information (CSI). However, the resulting real-time antenna movement may face challenges in practical implementation due to the additional time overhead and energy consumption required, especially in fast time-varying channel scenarios. To address this issue, we propose in this paper a new approach to optimize the MA positions based on the users' statistical CSI over a large timescale. In particular, we propose a general field response based statistical channel model to characterize the random channel variations caused by the local movement of users. Based on this model, a two-timescale optimization problem is formulated to maximize the ergodic sum rate of multiple users, where the precoding matrix and the positions of MAs at the base station (BS) are optimized based on the instantaneous and statistical CSI, respectively. To solve this non-convex optimization problem, a log-barrier penalized gradient ascent algorithm is developed to optimize the MA positions, where two methods are proposed to approximate the ergodic sum rate and its gradients with different complexities. Finally, we present simulation results to evaluate the performance of the proposed design and algorithms based on practical channels generated by ray-tracing. The results verify the performance advantages of MA systems compared to their fixed-position antenna (FPA) counterparts in terms of long-term rate improvement, especially for scenarios with more diverse channel power distributions in the angular domain.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
A Tutorial on Movable Antennas for Wireless Networks
Feb 25, 2025



Movable antenna (MA) has been recognized as a promising technology to enhance the performance of wireless communication and sensing by enabling antenna movement. Such a significant paradigm shift from conventional fixed antennas (FAs) to MAs offers tremendous new opportunities towards realizing more versatile, adaptive and efficient next-generation wireless networks such as 6G. In this paper, we provide a comprehensive tutorial on the fundamentals and advancements in the area of MA-empowered wireless networks. First, we overview the historical development and contemporary applications of MA technologies. Next, to characterize the continuous variation in wireless channels with respect to antenna position and/or orientation, we present new field-response channel models tailored for MAs, which are applicable to narrowband and wideband systems as well as far-field and near-field propagation conditions. Subsequently, we review the state-of-the-art architectures for implementing MAs and discuss their practical constraints. A general optimization framework is then formulated to fully exploit the spatial degrees of freedom (DoFs) in antenna movement for performance enhancement in wireless systems. In particular, we delve into two major design issues for MA systems. First, we address the intricate antenna movement optimization problem for various communication and/or sensing systems to maximize the performance gains achievable by MAs. Second, we deal with the challenging channel acquisition issue in MA systems for reconstructing the channel mapping between arbitrary antenna positions inside the transmitter and receiver regions. Moreover, we show existing prototypes developed for MA-aided communication/sensing and the experimental results based on them. Finally, the extension of MA design to other wireless systems and its synergy with other emerging wireless technologies are discussed.
MMRAG: Multi-Mode Retrieval-Augmented Generation with Large Language Models for Biomedical In-Context Learning
Feb 21, 2025



Objective: To optimize in-context learning in biomedical natural language processing by improving example selection. Methods: We introduce a novel multi-mode retrieval-augmented generation (MMRAG) framework, which integrates four retrieval strategies: (1) Random Mode, selecting examples arbitrarily; (2) Top Mode, retrieving the most relevant examples based on similarity; (3) Diversity Mode, ensuring variation in selected examples; and (4) Class Mode, selecting category-representative examples. This study evaluates MMRAG on three core biomedical NLP tasks: Named Entity Recognition (NER), Relation Extraction (RE), and Text Classification (TC). The datasets used include BC2GM for gene and protein mention recognition (NER), DDI for drug-drug interaction extraction (RE), GIT for general biomedical information extraction (RE), and HealthAdvice for health-related text classification (TC). The framework is tested with two large language models (Llama2-7B, Llama3-8B) and three retrievers (Contriever, MedCPT, BGE-Large) to assess performance across different retrieval strategies. Results: The results from the Random mode indicate that providing more examples in the prompt improves the model's generation performance. Meanwhile, Top mode and Diversity mode significantly outperform Random mode on the RE (DDI) task, achieving an F1 score of 0.9669, a 26.4% improvement. Among the three retrievers tested, Contriever outperformed the other two in a greater number of experiments. Additionally, Llama 2 and Llama 3 demonstrated varying capabilities across different tasks, with Llama 3 showing a clear advantage in handling NER tasks. Conclusion: MMRAG effectively enhances biomedical in-context learning by refining example selection, mitigating data scarcity issues, and demonstrating superior adaptability for NLP-driven healthcare applications.
Antenna Position and Beamforming Optimization for Movable Antenna Enabled ISAC: Optimal Solutions and Efficient Algorithms
Feb 20, 2025In this paper, we propose an integrated sensing and communication (ISAC) system enabled by movable antennas (MAs), which can dynamically adjust antenna positions to enhance both sensing and communication performance for future wireless networks. To characterize the benefits of MA-enabled ISAC systems, we first derive the Cram\'er-Rao bound (CRB) for angle estimation error, which is then minimized for optimizing the antenna position vector (APV) and beamforming design, subject to a pre-defined signal-to-noise ratio (SNR) constraint to ensure the communication performance. In particular, for the case with receive MAs only, we provide a closed-form optimal antenna position solution, and show that employing MAs over conventional fixed-position antennas (FPAs) can achieve a sensing performance gain upper-bounded by 4.77 dB. On the other hand, for the case with transmit MAs only, we develop a boundary traversal breadth-first search (BT-BFS) algorithm to obtain the global optimal solution in the line-of-sight (LoS) channel scenario, along with a lower-complexity boundary traversal depth-first search (BT-DFS) algorithm to find a local optimal solution efficiently. While in the scenario with non-LoS (NLoS) channels, a majorization-minimization (MM) based Rosen's gradient projection (RGP) algorithm with an efficient initialization method is proposed to obtain stationary solutions for the considered problem, which can be extended to the general case with both transmit and receive MAs. Extensive numerical results are presented to verify the effectiveness of the proposed algorithms, and demonstrate the superiority of the considered MA-enabled ISAC system over conventional ISAC systems with FPAs in terms of sensing and communication performance trade-off.