 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurse of Knowledge: When Complex Evaluation Context Benefits yet Biases LLM Judges
Sep 03, 2025As large language models (LLMs) grow more capable, they face increasingly diverse and complex tasks, making reliable evaluation challenging. The paradigm of LLMs as judges has emerged as a scalable solution, yet prior work primarily focuses on simple settings. Their reliability in complex tasks--where multi-faceted rubrics, unstructured reference answers, and nuanced criteria are critical--remains understudied. In this paper, we constructed ComplexEval, a challenge benchmark designed to systematically expose and quantify Auxiliary Information Induced Biases. We systematically investigated and validated 6 previously unexplored biases across 12 basic and 3 advanced scenarios. Key findings reveal: (1) all evaluated models exhibit significant susceptibility to these biases, with bias magnitude scaling with task complexity; (2) notably, Large Reasoning Models (LRMs) show paradoxical vulnerability. Our in-depth analysis offers crucial insights for improving the accuracy and verifiability of evaluation signals, paving the way for more general and robust evaluation models.
SSFO: Self-Supervised Faithfulness Optimization for Retrieval-Augmented Generation
Aug 24, 2025Retrieval-Augmented Generation (RAG) systems require Large Language Models (LLMs) to generate responses that are faithful to the retrieved context. However, faithfulness hallucination remains a critical challenge, as existing methods often require costly supervision and post-training or significant inference burdens. To overcome these limitations, we introduce Self-Supervised Faithfulness Optimization (SSFO), the first self-supervised alignment approach for enhancing RAG faithfulness. SSFO constructs preference data pairs by contrasting the model's outputs generated with and without the context. Leveraging Direct Preference Optimization (DPO), SSFO aligns model faithfulness without incurring labeling costs or additional inference burden. We theoretically and empirically demonstrate that SSFO leverages a benign form of \emph{likelihood displacement}, transferring probability mass from parametric-based tokens to context-aligned tokens. Based on this insight, we propose a modified DPO loss function to encourage likelihood displacement. Comprehensive evaluations show that SSFO significantly outperforms existing methods, achieving state-of-the-art faithfulness on multiple context-based question-answering datasets. Notably, SSFO exhibits strong generalization, improving cross-lingual faithfulness and preserving general instruction-following capabilities. We release our code and model at the anonymous link: https://github.com/chkwy/SSFO
Multi-modal Knowledge Decomposition based Online Distillation for Biomarker Prediction in Breast Cancer Histopathology
Aug 24, 2025Immunohistochemical (IHC) biomarker prediction benefits from multi-modal data fusion analysis. However, the simultaneous acquisition of multi-modal data, such as genomic and pathological information, is often challenging due to cost or technical limitations. To address this challenge, we propose an online distillation approach based on Multi-modal Knowledge Decomposition (MKD) to enhance IHC biomarker prediction in haematoxylin and eosin (H\&E) stained histopathology images. This method leverages paired genomic-pathology data during training while enabling inference using either pathology slides alone or both modalities. Two teacher and one student models are developed to extract modality-specific and modality-general features by minimizing the MKD loss. To maintain the internal structural relationships between samples, Similarity-preserving Knowledge Distillation (SKD) is applied. Additionally, Collaborative Learning for Online Distillation (CLOD) facilitates mutual learning between teacher and student models, encouraging diverse and complementary learning dynamics. Experiments on the TCGA-BRCA and in-house QHSU datasets demonstrate that our approach achieves superior performance in IHC biomarker prediction using uni-modal data. Our code is available at https://github.com/qiyuanzz/MICCAI2025_MKD.
Fairy$\pm i$: the First 2-bit Complex LLM with All Parameters in $\{\pm1, \pm i\}$
Aug 07, 2025Quantization-Aware Training (QAT) integrates quantization into the training loop, enabling LLMs to learn robust low-bit representations, and is widely recognized as one of the most promising research directions. All current QAT research focuses on minimizing quantization error on full-precision models, where the full-precision accuracy acts as an upper bound (accuracy ceiling). No existing method has even attempted to surpass this ceiling. To break this ceiling, we propose a new paradigm: raising the ceiling (full-precision model), and then still quantizing it efficiently into 2 bits. We propose Fairy$\pm i$, the first 2-bit quantization framework for complex-valued LLMs. Specifically, our method leverages the representational advantages of the complex domain to boost full-precision accuracy. We map weights to the fourth roots of unity $\{\pm1, \pm i\}$, forming a perfectly symmetric and information-theoretically optimal 2-bit representation. Importantly, each quantized weight has either a zero real or imaginary part, enabling multiplication-free inference using only additions and element swaps. Experimental results show that Fairy$\pm i$ outperforms the ceiling of existing 2-bit quantization approaches in terms of both PPL and downstream tasks, while maintaining strict storage and compute efficiency. This work opens a new direction for building highly accurate and practical LLMs under extremely low-bit constraints.
URWKV: Unified RWKV Model with Multi-state Perspective for Low-light Image Restoration
May 29, 2025Existing low-light image enhancement (LLIE) and joint LLIE and deblurring (LLIE-deblur) models have made strides in addressing predefined degradations, yet they are often constrained by dynamically coupled degradations. To address these challenges, we introduce a Unified Receptance Weighted Key Value (URWKV) model with multi-state perspective, enabling flexible and effective degradation restoration for low-light images. Specifically, we customize the core URWKV block to perceive and analyze complex degradations by leveraging multiple intra- and inter-stage states. First, inspired by the pupil mechanism in the human visual system, we propose Luminance-adaptive Normalization (LAN) that adjusts normalization parameters based on rich inter-stage states, allowing for adaptive, scene-aware luminance modulation. Second, we aggregate multiple intra-stage states through exponential moving average approach, effectively capturing subtle variations while mitigating information loss inherent in the single-state mechanism. To reduce the degradation effects commonly associated with conventional skip connections, we propose the State-aware Selective Fusion (SSF) module, which dynamically aligns and integrates multi-state features across encoder stages, selectively fusing contextual information. In comparison to state-of-the-art models, our URWKV model achieves superior performance on various benchmarks, while requiring significantly fewer parameters and computational resources.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025
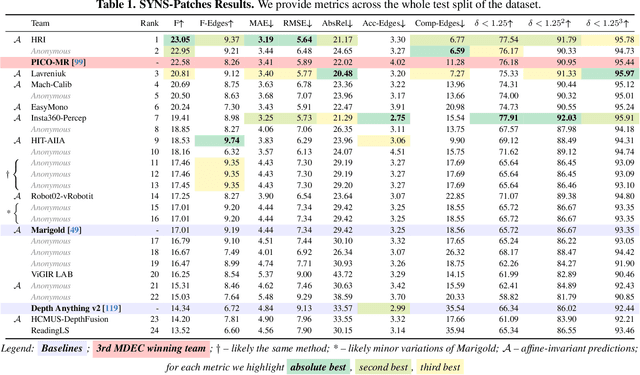
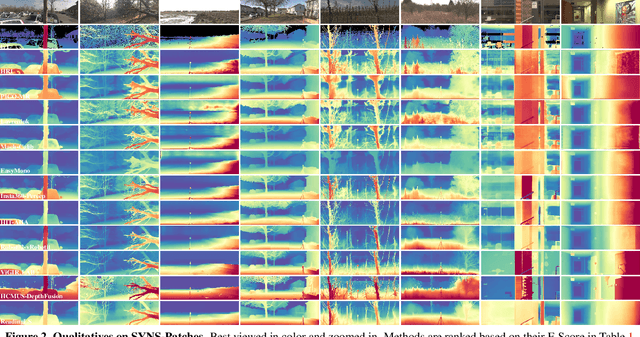
This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Memetic Search for Green Vehicle Routing Problem with Private Capacitated Refueling Stations
Apr 06, 2025



The green vehicle routing problem with private capacitated alternative fuel stations (GVRP-PCAFS) extends the traditional green vehicle routing problem by considering refueling stations limited capacity, where a limited number of vehicles can refuel simultaneously with additional vehicles must wait. This feature presents new challenges for route planning, as waiting times at stations must be managed while keeping route durations within limits and reducing total travel distance. This article presents METS, a novel memetic algorithm (MA) with separate constraint-based tour segmentation (SCTS) and efficient local search (ELS) for solving GVRP-PCAFS. METS combines global and local search effectively through three novelties. For global search, the SCTS strategy splits giant tours to generate diverse solutions, and the search process is guided by a comprehensive fitness evaluation function to dynamically control feasibility and diversity to produce solutions that are both diverse and near-feasible. For local search, ELS incorporates tailored move operators with constant-time move evaluation mechanisms, enabling efficient exploration of large solution neighborhoods. Experimental results demonstrate that METS discovers 31 new best-known solutions out of 40 instances in existing benchmark sets, achieving substantial improvements over current state-of-the-art methods. Additionally, a new large-scale benchmark set based on real-world logistics data is introduced to facilitate future research.
Integrating mobile and fixed monitoring data for high-resolution PM2.5 mapping using machine learning
Mar 16, 2025


Constructing high resolution air pollution maps at lower cost is crucial for sustainable city management and public health risk assessment. However, traditional fixed-site monitoring lacks spatial coverage, while mobile low-cost sensors exhibit significant data instability. This study integrates PM2.5 data from 320 taxi-mounted mobile low-cost sensors and 52 fixed monitoring stations to address these limitations. By employing the machine learning methods, an appropriate mapping relationship was established between fixed and mobile monitoring concentration. The resulting pollution maps achieved 500-meter spatial and 5-minute temporal resolutions, showing close alignment with fixed monitoring data (+4.35% bias) but significant deviation from raw mobile data (-31.77%). The fused map exhibits the fine-scale spatial variability also observed in the mobile pollution map, while showing the stable temporal variability closer to that of the fixed pollution map (fixed: 1.12 plus or minus 0.73%, mobile: 3.15 plus or minus 2.44%, mapped: 1.01 plus or minus 0.65%). These findings demonstrate the potential of large-scale mobile low-cost sensor networks for high-resolution air quality mapping, supporting targeted urban environmental governance and health risk mitigation.
Guess What I am Thinking: A Benchmark for Inner Thought Reasoning of Role-Playing Language Agents
Mar 11, 2025



Recent advances in LLM-based role-playing language agents (RPLAs) have attracted broad attention in various applications. While chain-of-thought reasoning has shown importance in many tasks for LLMs, the internal thinking processes of RPLAs remain unexplored. Understanding characters' inner thoughts is crucial for developing advanced RPLAs. In this paper, we introduce ROLETHINK, a novel benchmark constructed from literature for evaluating character thought generation. We propose the task of inner thought reasoning, which includes two sets: the gold set that compares generated thoughts with original character monologues, and the silver set that uses expert synthesized character analyses as references. To address this challenge, we propose MIRROR, a chain-of-thought approach that generates character thoughts by retrieving memories, predicting character reactions, and synthesizing motivations. Through extensive experiments, we demonstrate the importance of inner thought reasoning for RPLAs, and MIRROR consistently outperforms existing methods. Resources are available at https://github.com/airaer1998/RPA_Thought.
A$^2$ATS: Retrieval-Based KV Cache Reduction via Windowed Rotary Position Embedding and Query-Aware Vector Quantization
Feb 18, 2025



Long context large language models (LLMs) pose significant challenges for efficient serving due to the large memory footprint and high access overhead of KV cache. Retrieval-based KV cache reduction methods can mitigate these challenges, typically by offloading the complete KV cache to CPU and retrieving necessary tokens on demand during inference. However, these methods still suffer from unsatisfactory accuracy degradation and extra retrieval overhead. To address these limitations, this paper proposes A$^2$ATS, a novel retrieval-based KV cache reduction method. A$^2$ATS aims to obtain an accurate approximation of attention scores by applying the vector quantization technique to key states, thereby enabling efficient and precise retrieval of the top-K tokens. First, we propose Windowed Rotary Position Embedding, which decouples the positional dependency from query and key states after position embedding. Then, we propose query-aware vector quantization that optimizes the objective of attention score approximation directly. Finally, we design the heterogeneous inference architecture for KV cache offloading, enabling long context serving with larger batch sizes. Experimental results demonstrate that A$^2$ATS can achieve a lower performance degradation with similar or lower overhead compared to existing methods, thereby increasing long context serving throughput by up to $2.7 \times$.