 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Fairy$\pm i$: the First 2-bit Complex LLM with All Parameters in $\{\pm1, \pm i\}$
Aug 07, 2025Quantization-Aware Training (QAT) integrates quantization into the training loop, enabling LLMs to learn robust low-bit representations, and is widely recognized as one of the most promising research directions. All current QAT research focuses on minimizing quantization error on full-precision models, where the full-precision accuracy acts as an upper bound (accuracy ceiling). No existing method has even attempted to surpass this ceiling. To break this ceiling, we propose a new paradigm: raising the ceiling (full-precision model), and then still quantizing it efficiently into 2 bits. We propose Fairy$\pm i$, the first 2-bit quantization framework for complex-valued LLMs. Specifically, our method leverages the representational advantages of the complex domain to boost full-precision accuracy. We map weights to the fourth roots of unity $\{\pm1, \pm i\}$, forming a perfectly symmetric and information-theoretically optimal 2-bit representation. Importantly, each quantized weight has either a zero real or imaginary part, enabling multiplication-free inference using only additions and element swaps. Experimental results show that Fairy$\pm i$ outperforms the ceiling of existing 2-bit quantization approaches in terms of both PPL and downstream tasks, while maintaining strict storage and compute efficiency. This work opens a new direction for building highly accurate and practical LLMs under extremely low-bit constraints.
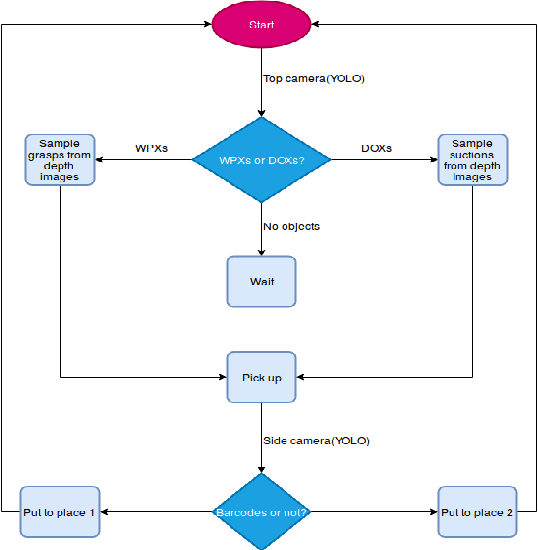
Object grasping planning for the situation when soft and rigid objects are mixed together
Sep 20, 2019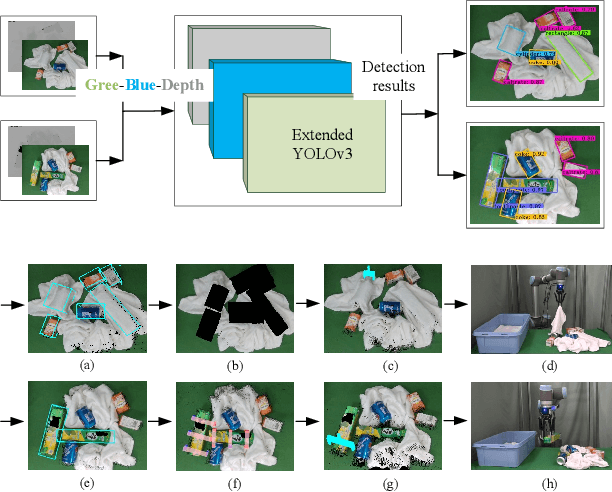
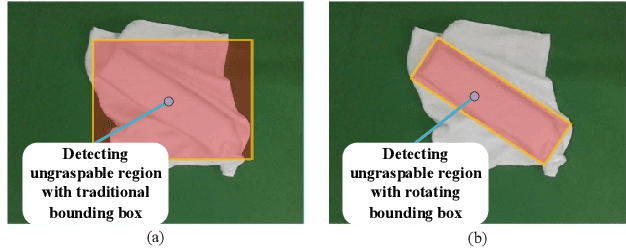
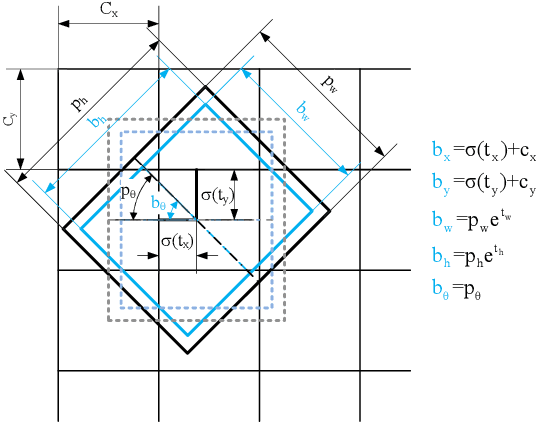

In this paper, we propose a object detection method expressed as rotated bounding box to solve grasping challenge in the scenes where rigid objects and soft objects are mixed together. Compared with traditional detection methods, this method can output the angle information of rotated objects and thus can guarantee that within each rotated bounding box, there is a single instance. This technology is especially useful in the case of pile of objects with different orientations. In our method, when uncategorized objects with specific geometry shapes (rectangle or cylinder) are detected, the program will conclude that some rigid objects are covered by the towels. If no covered objects are detected, the grasp planning is based on 3D point cloud obtained from the mapping between 2D object detection result and its corresponding 3D point cloud. Based on the information provided by the 3D bounding box covering the object, grasping strategy for multiple cluttered rigid objects, collision avoidance strategy are proposed. The proposed method is verified by the experiment in which rigid objects and towels are mixed together.
Assembly of randomly placed parts realized by using only one robot arm with a general parallel-jaw gripper
Sep 19, 2019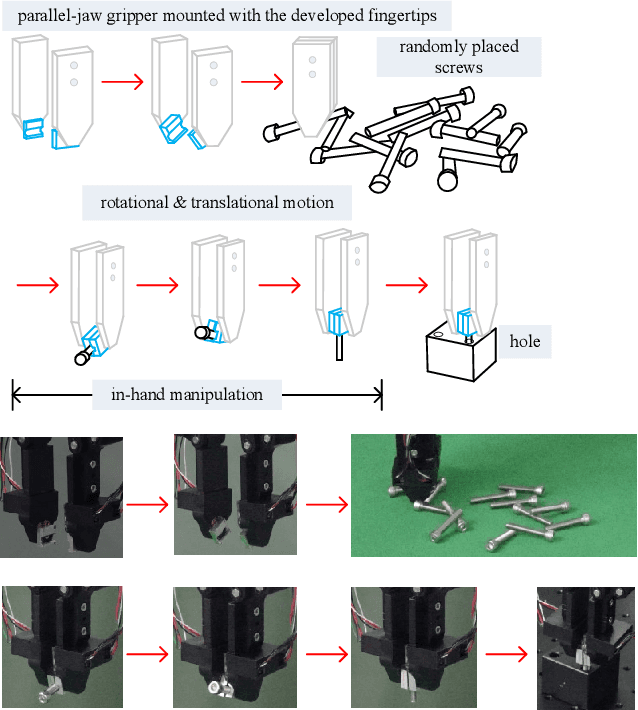
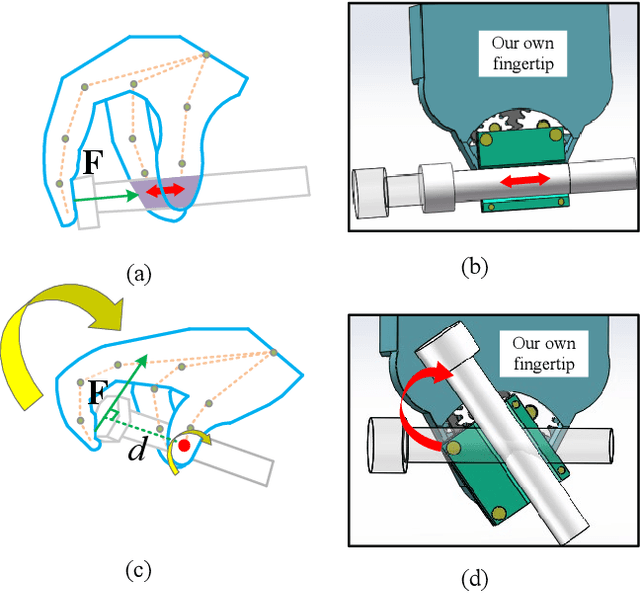
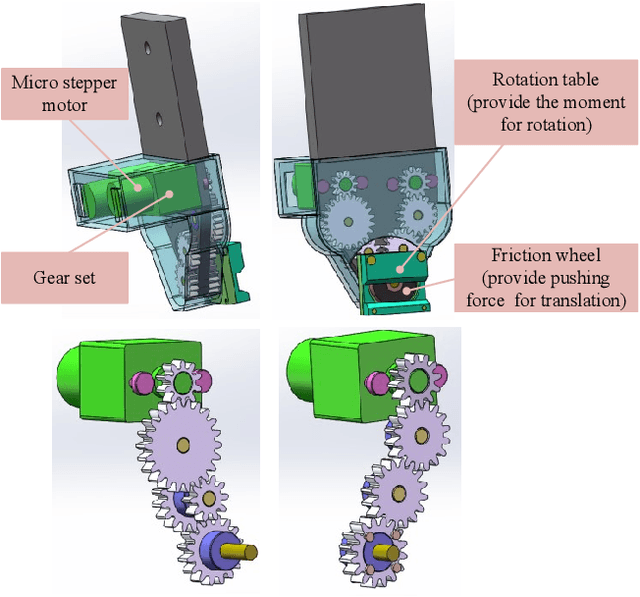
In industry assembly lines, parts feeding machines are widely employed as the prologue of the whole procedure. They play the role of sorting the parts randomly placed in bins to the state with specified pose. With the help of the parts feeding machines, the subsequent assembly processes by robot arm can always start from the same condition. Thus it is expected that function of parting feeding machine and the robotic assembly can be integrated with one robot arm. This scheme can provide great flexibility and can also contribute to reduce the cost. The difficulties involved in this scheme lie in the fact that in the part feeding phase, the pose of the part after grasping may be not proper for the subsequent assembly. Sometimes it can not even guarantee a stable grasp. In this paper, we proposed a method to integrate parts feeding and assembly within one robot arm. This proposal utilizes a specially designed gripper tip mounted on the jaws of a two-fingered gripper. With the modified gripper, in-hand manipulation of the grasped object is realized, which can ensure the control of the orientation and offset position of the grasped object. The proposal in this paper is verified by a simulated assembly in which a robot arm completed the assembly process including parts picking from bin and a subsequent peg-in-hole assembly.
Vision Based Picking System for Automatic Express Package Dispatching
Apr 09, 2019
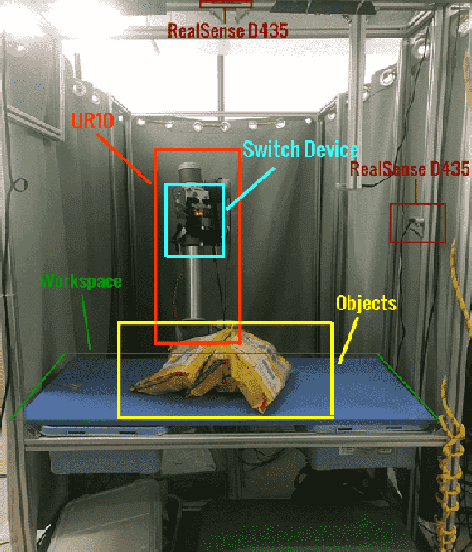

This paper presents a vision based robotic system to handle the picking problem involved in automatic express package dispatching. By utilizing two RealSense RGB-D cameras and one UR10 industrial robot, package dispatching task which is usually done by human can be completed automatically. In order to determine grasp point for overlapped deformable objects, we improved the sampling algorithm proposed by the group in Berkeley to directly generate grasp candidate from depth images. For the purpose of package recognition, the deep network framework YOLO is integrated. We also designed a multi-modal robot hand composed of a two-fingered gripper and a vacuum suction cup to deal with different kinds of packages. All the technologies have been integrated in a work cell which simulates the practical conditions of an express package dispatching scenario. The proposed system is verified by experiments conducted for two typical express items.
Efficient Fully Convolution Neural Network for Generating Pixel Wise Robotic Grasps With High Resolution Images
Feb 24, 2019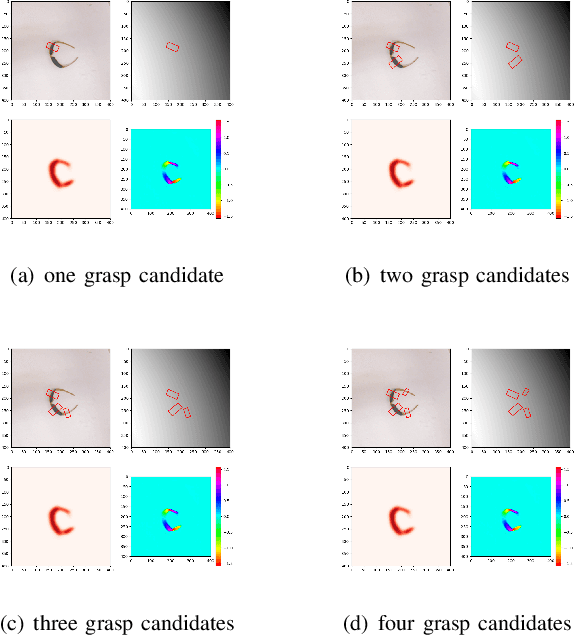

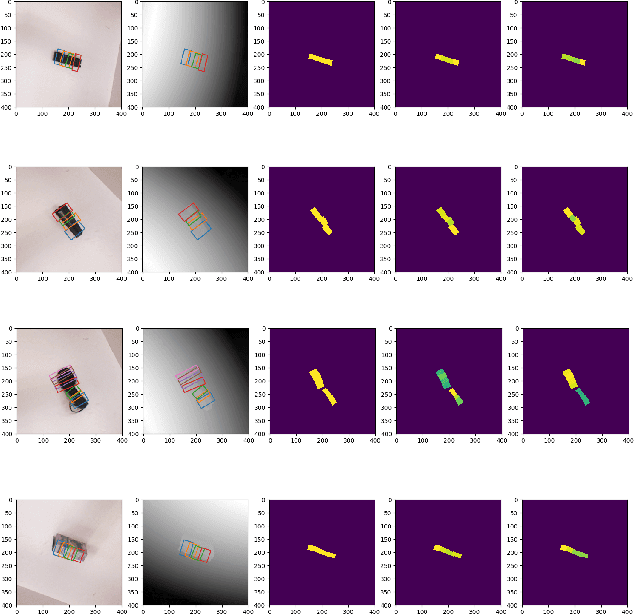
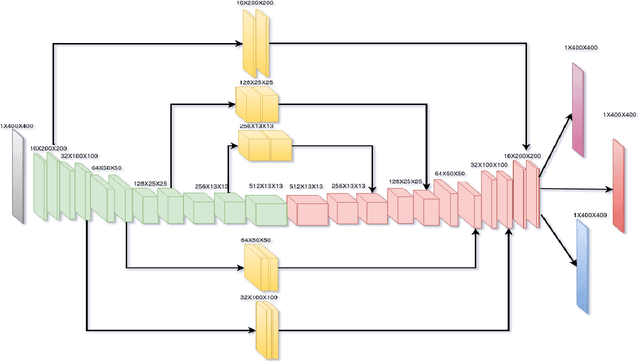
This paper presents an efficient neural network model to generate robotic grasps with high resolution images. The proposed model uses fully convolution neural network to generate robotic grasps for each pixel using 400 $\times$ 400 high resolution RGB-D images. It first down-sample the images to get features and then up-sample those features to the original size of the input as well as combines local and global features from different feature maps. Compared to other regression or classification methods for detecting robotic grasps, our method looks more like the segmentation methods which solves the problem through pixel-wise ways. We use Cornell Grasp Dataset to train and evaluate the model and get high accuracy about 94.42% for image-wise and 91.02% for object-wise and fast prediction time about 8ms. We also demonstrate that without training on the multiple objects dataset, our model can directly output robotic grasps candidates for different objects because of the pixel wise implementation.