 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARE: Privacy-Compliant Agentic Reasoning with Evidence Discordance
Apr 01, 2026Large language model (LLM) systems are increasingly used to support high-stakes decision-making, but they typically perform worse when the available evidence is internally inconsistent. Such a scenario exists in real-world healthcare settings, with patient-reported symptoms contradicting medical signs. To study this problem, we introduce MIMIC-DOS, a dataset for short-horizon organ dysfunction worsening prediction in the intensive care unit (ICU) setting. We derive this dataset from the widely recognized MIMIC-IV, a publicly available electronic health record dataset, and construct it exclusively from cases in which discordance between signs and symptoms exists. This setting poses a substantial challenge for existing LLM-based approaches, with single-pass LLMs and agentic pipelines often struggling to reconcile such conflicting signals. To address this problem, we propose CARE: a multi-stage privacy-compliant agentic reasoning framework in which a remote LLM provides guidance by generating structured categories and transitions without accessing sensitive patient data, while a local LLM uses these categories and transitions to support evidence acquisition and final decision-making. Empirically, CARE achieves stronger performance across all key metrics compared to multiple baseline settings, showing that CARE can more robustly handle conflicting clinical evidence while preserving privacy.
ReFilter: Improving Robustness of Retrieval-Augmented Generation via Gated Filter
Feb 13, 2026Retrieval-augmented generation (RAG) has become a dominant paradigm for grounding large language models (LLMs) with external evidence in knowledge-intensive question answering. A core design choice is how to fuse retrieved samples into the LLMs, where existing internal fusion approaches broadly fall into query-based fusion, parametric fusion, and latent-based fusion. Despite their effectiveness at modest retrieval scales, these methods often fail to scale gracefully as the number of retrieved candidates k increases: Larger k improves evidence coverage, yet realistic top-k retrieval inevitably contains irrelevant or redundant content and increases the inference cost. To address these limitations, we propose ReFilter, a novel latent-based fusion framework that performs token-level filtering and fusion. ReFilter consists of three key components: a context encoder for encoding context features, a gated filter for weighting each token, and a token fusion module for integrating the weighted token feature into the LLM's hidden states. Our experiments across four general-domain QA benchmarks show that ReFilter consistently achieves the best average performance under both in-domain adaptation and out-of-domain transfer. ReFilter further generalizes to five biomedical QA benchmarks in zero-shot transfer without domain fine-tuning, reaching 70.01% average accuracy with Qwen2.5-14B-Instruct.
Nav-EE: Navigation-Guided Early Exiting for Efficient Vision-Language Models in Autonomous Driving
Oct 02, 2025Vision-Language Models (VLMs) are increasingly applied in autonomous driving for unified perception and reasoning, but high inference latency hinders real-time deployment. Early-exit reduces latency by terminating inference at intermediate layers, yet its task-dependent nature limits generalization across diverse scenarios. We observe that this limitation aligns with autonomous driving: navigation systems can anticipate upcoming contexts (e.g., intersections, traffic lights), indicating which tasks will be required. We propose Nav-EE, a navigation-guided early-exit framework that precomputes task-specific exit layers offline and dynamically applies them online based on navigation priors. Experiments on CODA, Waymo, and BOSCH show that Nav-EE achieves accuracy comparable to full inference while reducing latency by up to 63.9%. Real-vehicle integration with Autoware Universe further demonstrates reduced inference latency (600ms to 300ms), supporting faster decision-making in complex scenarios. These results suggest that coupling navigation foresight with early-exit offers a viable path toward efficient deployment of large models in autonomous systems. Code and data are available at our anonymous repository: https://anonymous.4open.science/r/Nav-EE-BBC4
Beyond Semantic Similarity: Reducing Unnecessary API Calls via Behavior-Aligned Retriever
Aug 20, 2025Tool-augmented large language models (LLMs) leverage external functions to extend their capabilities, but inaccurate function calls can lead to inefficiencies and increased costs.Existing methods address this challenge by fine-tuning LLMs or using demonstration-based prompting, yet they often suffer from high training overhead and fail to account for inconsistent demonstration samples, which misguide the model's invocation behavior. In this paper, we trained a behavior-aligned retriever (BAR), which provides behaviorally consistent demonstrations to help LLMs make more accurate tool-using decisions. To train the BAR, we construct a corpus including different function-calling behaviors, i.e., calling or non-calling.We use the contrastive learning framework to train the BAR with customized positive/negative pairs and a dual-negative contrastive loss, ensuring robust retrieval of behaviorally consistent examples.Experiments demonstrate that our approach significantly reduces erroneous function calls while maintaining high task performance, offering a cost-effective and efficient solution for tool-augmented LLMs.
Lossless Compression of Large Language Model-Generated Text via Next-Token Prediction
May 07, 2025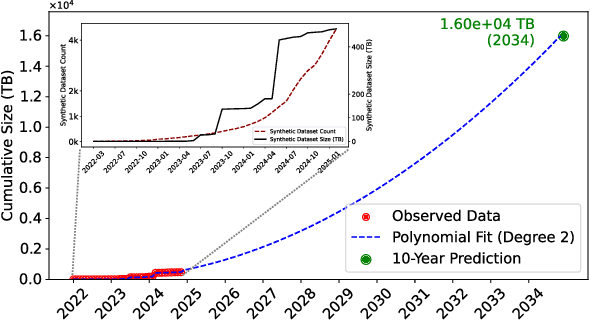
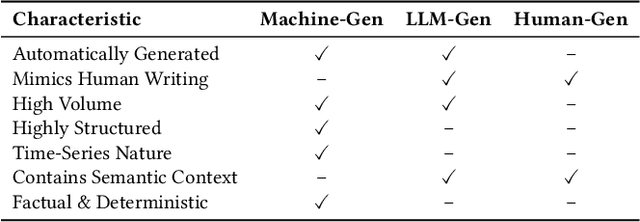
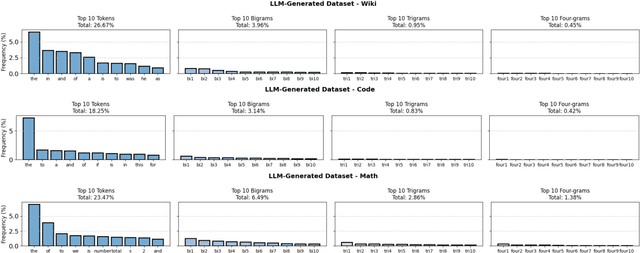

As large language models (LLMs) continue to be deployed and utilized across domains, the volume of LLM-generated data is growing rapidly. This trend highlights the increasing importance of effective and lossless compression for such data in modern text management systems. However, compressing LLM-generated data presents unique challenges compared to traditional human- or machine-generated content. Traditional machine-generated data is typically derived from computational processes or device outputs, often highly structured and limited to low-level elements like labels or numerical values. This structure enables conventional lossless compressors to perform efficiently. In contrast, LLM-generated data is more complex and diverse, requiring new approaches for effective compression. In this work, we conduct the first systematic investigation of lossless compression techniques tailored specifically to LLM-generated data. Notably, because LLMs are trained via next-token prediction, we find that LLM-generated data is highly predictable for the models themselves. This predictability enables LLMs to serve as efficient compressors of their own outputs. Through extensive experiments with 14 representative LLMs and 8 LLM-generated datasets from diverse domains, we show that LLM-based prediction methods achieve remarkable compression rates, exceeding 20x, far surpassing the 3x rate achieved by Gzip, a widely used general-purpose compressor. Furthermore, this advantage holds across different LLM sizes and dataset types, demonstrating the robustness and practicality of LLM-based methods in lossless text compression under generative AI workloads.
Easz: An Agile Transformer-based Image Compression Framework for Resource-constrained IoTs
May 03, 2025Neural image compression, necessary in various machine-to-machine communication scenarios, suffers from its heavy encode-decode structures and inflexibility in switching between different compression levels. Consequently, it raises significant challenges in applying the neural image compression to edge devices that are developed for powerful servers with high computational and storage capacities. We take a step to solve the challenges by proposing a new transformer-based edge-compute-free image coding framework called Easz. Easz shifts the computational overhead to the server, and hence avoids the heavy encoding and model switching overhead on the edge. Easz utilizes a patch-erase algorithm to selectively remove image contents using a conditional uniform-based sampler. The erased pixels are reconstructed on the receiver side through a transformer-based framework. To further reduce the computational overhead on the receiver, we then introduce a lightweight transformer-based reconstruction structure to reduce the reconstruction load on the receiver side. Extensive evaluations conducted on a real-world testbed demonstrate multiple advantages of Easz over existing compression approaches, in terms of adaptability to different compression levels, computational efficiency, and image reconstruction quality.
VLM-C4L: Continual Core Dataset Learning with Corner Case Optimization via Vision-Language Models for Autonomous Driving
Mar 29, 2025With the widespread adoption and deployment of autonomous driving, handling complex environments has become an unavoidable challenge. Due to the scarcity and diversity of extreme scenario datasets, current autonomous driving models struggle to effectively manage corner cases. This limitation poses a significant safety risk, according to the National Highway Traffic Safety Administration (NHTSA), autonomous vehicle systems have been involved in hundreds of reported crashes annually in the United States, occurred in corner cases like sun glare and fog, which caused a few fatal accident. Furthermore, in order to consistently maintain a robust and reliable autonomous driving system, it is essential for models not only to perform well on routine scenarios but also to adapt to newly emerging scenarios, especially those corner cases that deviate from the norm. This requires a learning mechanism that incrementally integrates new knowledge without degrading previously acquired capabilities. However, to the best of our knowledge, no existing continual learning methods have been proposed to ensure consistent and scalable corner case learning in autonomous driving. To address these limitations, we propose VLM-C4L, a continual learning framework that introduces Vision-Language Models (VLMs) to dynamically optimize and enhance corner case datasets, and VLM-C4L combines VLM-guided high-quality data extraction with a core data replay strategy, enabling the model to incrementally learn from diverse corner cases while preserving performance on previously routine scenarios, thus ensuring long-term stability and adaptability in real-world autonomous driving. We evaluate VLM-C4L on large-scale real-world autonomous driving datasets, including Waymo and the corner case dataset CODA.
FlexInfer: Breaking Memory Constraint via Flexible and Efficient Offloading for On-Device LLM Inference
Mar 04, 2025



Large Language Models (LLMs) face challenges for on-device inference due to high memory demands. Traditional methods to reduce memory usage often compromise performance and lack adaptability. We propose FlexInfer, an optimized offloading framework for on-device inference, addressing these issues with techniques like asynchronous prefetching, balanced memory locking, and flexible tensor preservation. These strategies enhance memory efficiency and mitigate I/O bottlenecks, ensuring high performance within user-specified resource constraints. Experiments demonstrate that FlexInfer significantly improves throughput under limited resources, achieving up to 12.5 times better performance than existing methods and facilitating the deployment of large models on resource-constrained devices.
CoT-VLM4Tar: Chain-of-Thought Guided Vision-Language Models for Traffic Anomaly Resolution
Mar 03, 2025



With the acceleration of urbanization, modern urban traffic systems are becoming increasingly complex, leading to frequent traffic anomalies. These anomalies encompass not only common traffic jams but also more challenging issues such as phantom traffic jams, intersection deadlocks, and accident liability analysis, which severely impact traffic flow, vehicular safety, and overall transportation efficiency. Currently, existing solutions primarily rely on manual intervention by traffic police or artificial intelligence-based detection systems. However, these methods often suffer from response delays and inconsistent management due to inadequate resources, while AI detection systems, despite enhancing efficiency to some extent, still struggle to handle complex traffic anomalies in a real-time and precise manner. To address these issues, we propose CoT-VLM4Tar: (Chain of Thought Visual-Language Model for Traffic Anomaly Resolution), this innovative approach introduces a new chain-of-thought to guide the VLM in analyzing, reasoning, and generating solutions for traffic anomalies with greater reasonable and effective solution, and to evaluate the performance and effectiveness of our method, we developed a closed-loop testing framework based on the CARLA simulator. Furthermore, to ensure seamless integration of the solutions generated by the VLM with the CARLA simulator, we implement an itegration module that converts these solutions into executable commands. Our results demonstrate the effectiveness of VLM in the resolution of real-time traffic anomalies, providing a proof-of-concept for its integration into autonomous traffic management systems.
When Compression Meets Model Compression: Memory-Efficient Double Compression for Large Language Models
Feb 21, 2025Large language models (LLMs) exhibit excellent performance in various tasks. However, the memory requirements of LLMs present a great challenge when deploying on memory-limited devices, even for quantized LLMs. This paper introduces a framework to compress LLM after quantization further, achieving about 2.2x compression ratio. A compression-aware quantization is first proposed to enhance model weight compressibility by re-scaling the model parameters before quantization, followed by a pruning method to improve further. Upon this, we notice that decompression can be a bottleneck during practical scenarios. We then give a detailed analysis of the trade-off between memory usage and latency brought by the proposed method. A speed-adaptive method is proposed to overcome it. The experimental results show inference with the compressed model can achieve a 40% reduction in memory size with negligible loss in accuracy and inference speed.