 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReversible Lifelong Model Editing via Semantic Routing-Based LoRA
Mar 11, 2026The dynamic evolution of real-world necessitates model editing within Large Language Models. While existing methods explore modular isolation or parameter-efficient strategies, they still suffer from semantic drift or knowledge forgetting due to continual updating. To address these challenges, we propose SoLA, a Semantic routing-based LoRA framework for lifelong model editing. In SoLA, each edit is encapsulated as an independent LoRA module, which is frozen after training and mapped to input by semantic routing, allowing dynamic activation of LoRA modules via semantic matching. This mechanism avoids semantic drift caused by cluster updating and mitigates catastrophic forgetting from parameter sharing. More importantly, SoLA supports precise revocation of specific edits by removing key from semantic routing, which restores model's original behavior. To our knowledge, this reversible rollback editing capability is the first to be achieved in existing literature. Furthermore, SoLA integrates decision-making process into edited layer, eliminating the need for auxiliary routing networks and enabling end-to-end decision-making process. Extensive experiments demonstrate that SoLA effectively learns and retains edited knowledge, achieving accurate, efficient, and reversible lifelong model editing.
Representation Finetuning for Continual Learning
Mar 11, 2026The world is inherently dynamic, and continual learning aims to enable models to adapt to ever-evolving data streams. While pre-trained models have shown powerful performance in continual learning, they still require finetuning to adapt effectively to downstream tasks. However, prevailing Parameter-Efficient Fine-Tuning (PEFT) methods operate through empirical, black-box optimization at the weight level. These approaches lack explicit control over representation drift, leading to sensitivity to domain shifts and catastrophic forgetting in continual learning scenarios. In this work, we introduce Continual Representation Learning (CoRe), a novel framework that for the first time shifts the finetuning paradigm from weight space to representation space. Unlike conventional methods, CoRe performs task-specific interventions within a low-rank linear subspace of hidden representations, adopting a learning process with explicit objectives, which ensures stability for past tasks while maintaining plasticity for new ones. By constraining updates to a low-rank subspace, CoRe achieves exceptional parameter efficiency. Extensive experiments across multiple continual learning benchmarks demonstrate that CoRe not only preserves parameter efficiency but also significantly outperforms existing state-of-the-art methods. Our work introduces representation finetuning as a new, more effective and interpretable paradigm for continual learning.
A Simple Efficiency Incremental Learning Framework via Vision-Language Model with Nonlinear Multi-Adapters
Mar 11, 2026Incremental Learning (IL) aims to learn new tasks while preserving previously acquired knowledge. Integrating the zero-shot learning capabilities of pre-trained vision-language models into IL methods has marked a significant advancement. However, these methods face three primary challenges: (1) the need for improved training efficiency; (2) reliance on a memory bank to store previous data; and (3) the necessity of a strong backbone to augment the model's capabilities. In this paper, we propose SimE, a Simple and Efficient framework that employs a vision-language model with adapters designed specifically for the IL task. We report a remarkable phenomenon: there is a nonlinear correlation between the number of adaptive adapter connections and the model's IL capabilities. While increasing adapter connections between transformer blocks improves model performance, adding more adaptive connections within transformer blocks during smaller incremental steps does not enhance, and may even degrade the model's IL ability. Extensive experimental results show that SimE surpasses traditional methods by 9.6% on TinyImageNet and outperforms other CLIP-based methods by 5.3% on CIFAR-100. Furthermore, we conduct a systematic study to enhance the utilization of the zero-shot capabilities of CLIP. We suggest replacing SimE's encoder with a CLIP model trained on larger datasets (e.g., LAION2B) and stronger architectures (e.g., ViT-L/14).
ULW-SleepNet: An Ultra-Lightweight Network for Multimodal Sleep Stage Scoring
Feb 27, 2026Automatic sleep stage scoring is crucial for the diagnosis and treatment of sleep disorders. Although deep learning models have advanced the field, many existing models are computationally demanding and designed for single-channel electroencephalography (EEG), limiting their practicality for multimodal polysomnography (PSG) data. To overcome this, we propose ULW-SleepNet, an ultra-lightweight multimodal sleep stage scoring framework that efficiently integrates information from multiple physiological signals. ULW-SleepNet incorporates a novel Dual-Stream Separable Convolution (DSSC) Block, depthwise separable convolutions, channel-wise parameter sharing, and global average pooling to reduce computational overhead while maintaining competitive accuracy. Evaluated on the Sleep-EDF-20 and Sleep-EDF-78 datasets, ULW-SleepNet achieves accuracies of 86.9% and 81.4%, respectively, with only 13.3K parameters and 7.89M FLOPs. Compared to state-of-the-art methods, our model reduces parameters by up to 98.6% with only marginal performance loss, demonstrating its strong potential for real-time sleep monitoring on wearable and IoT devices. The source code for this study is publicly available at https://github.com/wzw999/ULW-SLEEPNET.
Key-Value Pair-Free Continual Learner via Task-Specific Prompt-Prototype
Jan 08, 2026Continual learning aims to enable models to acquire new knowledge while retaining previously learned information. Prompt-based methods have shown remarkable performance in this domain; however, they typically rely on key-value pairing, which can introduce inter-task interference and hinder scalability. To overcome these limitations, we propose a novel approach employing task-specific Prompt-Prototype (ProP), thereby eliminating the need for key-value pairs. In our method, task-specific prompts facilitate more effective feature learning for the current task, while corresponding prototypes capture the representative features of the input. During inference, predictions are generated by binding each task-specific prompt with its associated prototype. Additionally, we introduce regularization constraints during prompt initialization to penalize excessively large values, thereby enhancing stability. Experiments on several widely used datasets demonstrate the effectiveness of the proposed method. In contrast to mainstream prompt-based approaches, our framework removes the dependency on key-value pairs, offering a fresh perspective for future continual learning research.
Multi-modal Knowledge Decomposition based Online Distillation for Biomarker Prediction in Breast Cancer Histopathology
Aug 24, 2025Immunohistochemical (IHC) biomarker prediction benefits from multi-modal data fusion analysis. However, the simultaneous acquisition of multi-modal data, such as genomic and pathological information, is often challenging due to cost or technical limitations. To address this challenge, we propose an online distillation approach based on Multi-modal Knowledge Decomposition (MKD) to enhance IHC biomarker prediction in haematoxylin and eosin (H\&E) stained histopathology images. This method leverages paired genomic-pathology data during training while enabling inference using either pathology slides alone or both modalities. Two teacher and one student models are developed to extract modality-specific and modality-general features by minimizing the MKD loss. To maintain the internal structural relationships between samples, Similarity-preserving Knowledge Distillation (SKD) is applied. Additionally, Collaborative Learning for Online Distillation (CLOD) facilitates mutual learning between teacher and student models, encouraging diverse and complementary learning dynamics. Experiments on the TCGA-BRCA and in-house QHSU datasets demonstrate that our approach achieves superior performance in IHC biomarker prediction using uni-modal data. Our code is available at https://github.com/qiyuanzz/MICCAI2025_MKD.
FCNCP: A Coupled Nonnegative CANDECOMP/PARAFAC Decomposition Based on Federated Learning
Apr 18, 2024



In the field of brain science, data sharing across servers is becoming increasingly challenging due to issues such as industry competition, privacy security, and administrative procedure policies and regulations. Therefore, there is an urgent need to develop new methods for data analysis and processing that enable scientific collaboration without data sharing. In view of this, this study proposes to study and develop a series of efficient non-negative coupled tensor decomposition algorithm frameworks based on federated learning called FCNCP for the EEG data arranged on different servers. It combining the good discriminative performance of tensor decomposition in high-dimensional data representation and decomposition, the advantages of coupled tensor decomposition in cross-sample tensor data analysis, and the features of federated learning for joint modelling in distributed servers. The algorithm utilises federation learning to establish coupling constraints for data distributed across different servers. In the experiments, firstly, simulation experiments are carried out using simulated data, and stable and consistent decomposition results are obtained, which verify the effectiveness of the proposed algorithms in this study. Then the FCNCP algorithm was utilised to decompose the fifth-order event-related potential (ERP) tensor data collected by applying proprioceptive stimuli on the left and right hands. It was found that contralateral stimulation induced more symmetrical components in the activation areas of the left and right hemispheres. The conclusions drawn are consistent with the interpretations of related studies in cognitive neuroscience, demonstrating that the method can efficiently process higher-order EEG data and that some key hidden information can be preserved.
Fast Learnings of Coupled Nonnegative Tensor Decomposition Using Optimal Gradient and Low-rank Approximation
Feb 10, 2023Nonnegative tensor decomposition has been widely applied in signal processing and neuroscience, etc. When it comes to group analysis of multi-block tensors, traditional tensor decomposition is insufficient to utilize the shared/similar information among tensors. In this study, we propose a coupled nonnegative CANDECOMP/PARAFAC decomposition algorithm optimized by the alternating proximal gradient method (CoNCPDAPG), which is capable of a simultaneous decomposition of tensors from different samples that are partially linked and a simultaneous extraction of common components, individual components and core tensors. Due to the low optimization efficiency brought by the nonnegative constraint and the high-dimensional nature of the data, we further propose the lraCoNCPD-APG algorithm by combining low-rank approximation and the proposed CoNCPD-APG method. When processing multi-block large-scale tensors, the proposed lraCoNCPD-APG algorithm can greatly reduce the computational load without compromising the decomposition quality. Experiment results of coupled nonnegative tensor decomposition problems designed for synthetic data, real-world face images and event-related potential data demonstrate the practicability and superiority of the proposed algorithms.
Sparse Nonnegative CANDECOMP/PARAFAC Decomposition in Block Coordinate Descent Framework: A Comparison Study
Dec 27, 2018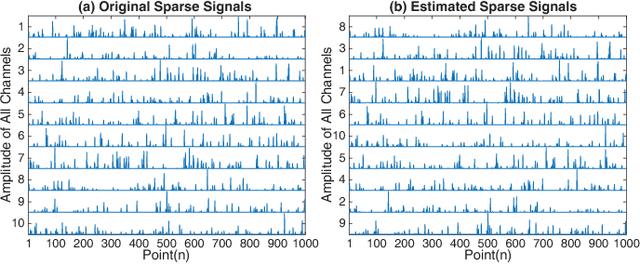
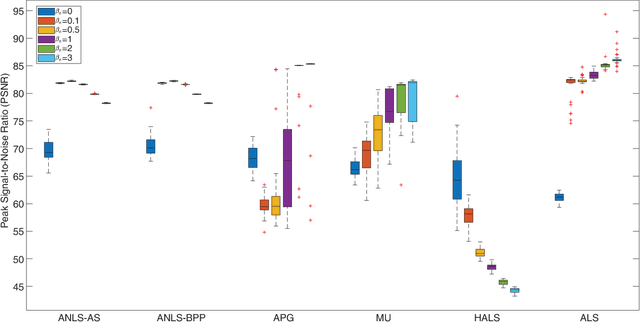
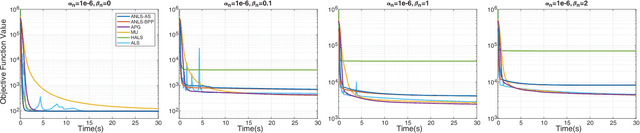
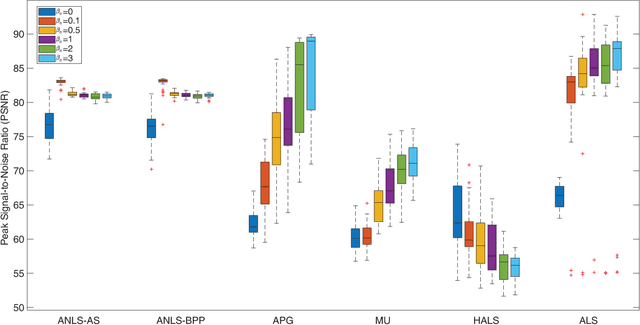
Nonnegative CANDECOMP/PARAFAC (NCP) decomposition is an important tool to process nonnegative tensor. Sometimes, additional sparse regularization is needed to extract meaningful nonnegative and sparse components. Thus, an optimization method for NCP that can impose sparsity efficiently is required. In this paper, we construct NCP with sparse regularization (sparse NCP) by l1-norm. Several popular optimization methods in block coordinate descent framework are employed to solve the sparse NCP, all of which are deeply analyzed with mathematical solutions. We compare these methods by experiments on synthetic and real tensor data, both of which contain third-order and fourth-order cases. After comparison, the methods that have fast computation and high effectiveness to impose sparsity will be concluded. In addition, we proposed an accelerated method to compute the objective function and relative error of sparse NCP, which has significantly improved the computation of tensor decomposition especially for higher-order tensor.
Diffusion map for clustering fMRI spatial maps extracted by independent component analysis
Sep 27, 2013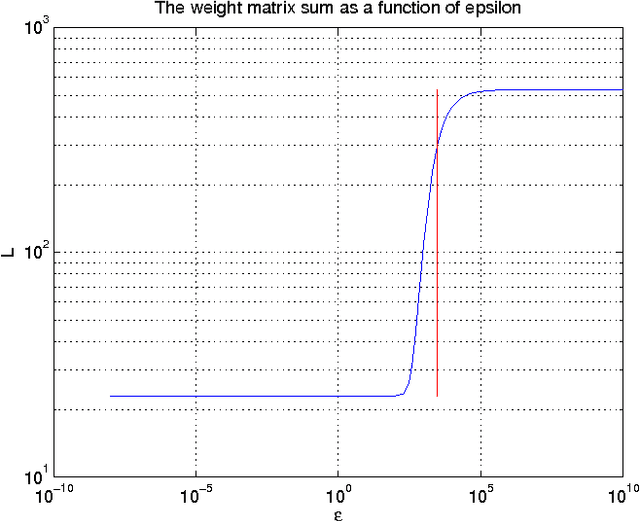
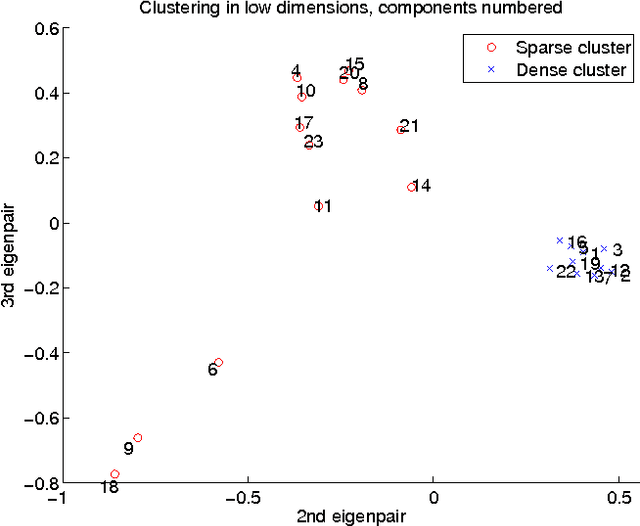
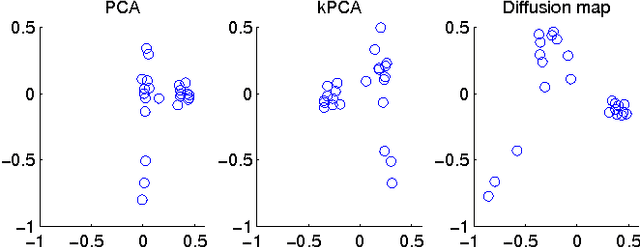
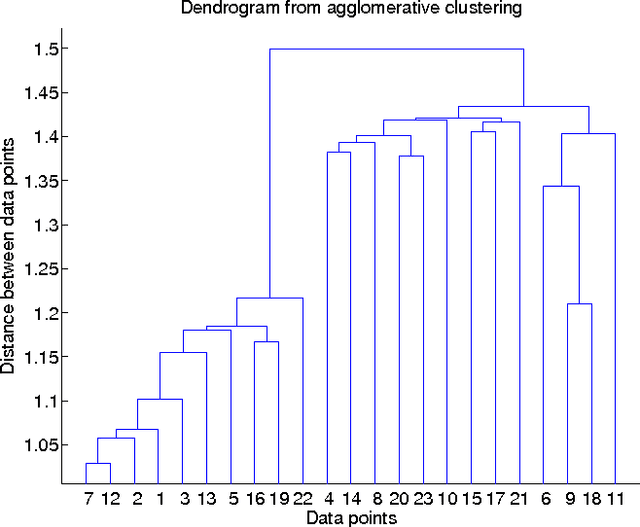
Functional magnetic resonance imaging (fMRI) produces data about activity inside the brain, from which spatial maps can be extracted by independent component analysis (ICA). In datasets, there are n spatial maps that contain p voxels. The number of voxels is very high compared to the number of analyzed spatial maps. Clustering of the spatial maps is usually based on correlation matrices. This usually works well, although such a similarity matrix inherently can explain only a certain amount of the total variance contained in the high-dimensional data where n is relatively small but p is large. For high-dimensional space, it is reasonable to perform dimensionality reduction before clustering. In this research, we used the recently developed diffusion map for dimensionality reduction in conjunction with spectral clustering. This research revealed that the diffusion map based clustering worked as well as the more traditional methods, and produced more compact clusters when needed.