 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Blind Denoising via Swin-Conv-UNet and Data Synthesis
Mar 28, 2022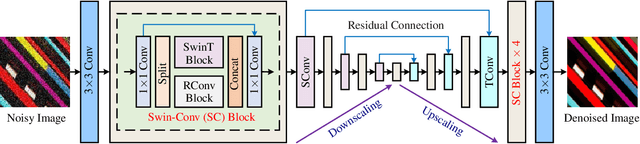
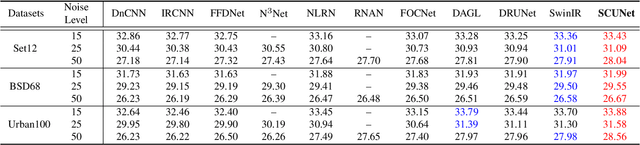
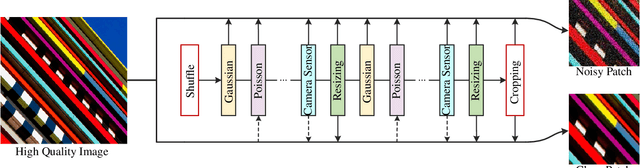

While recent years have witnessed a dramatic upsurge of exploiting deep neural networks toward solving image denoising, existing methods mostly rely on simple noise assumptions, such as additive white Gaussian noise (AWGN), JPEG compression noise and camera sensor noise, and a general-purpose blind denoising method for real images remains unsolved. In this paper, we attempt to solve this problem from the perspective of network architecture design and training data synthesis. Specifically, for the network architecture design, we propose a swin-conv block to incorporate the local modeling ability of residual convolutional layer and non-local modeling ability of swin transformer block, and then plug it as the main building block into the widely-used image-to-image translation UNet architecture. For the training data synthesis, we design a practical noise degradation model which takes into consideration different kinds of noise (including Gaussian, Poisson, speckle, JPEG compression, and processed camera sensor noises) and resizing, and also involves a random shuffle strategy and a double degradation strategy. Extensive experiments on AGWN removal and real image denoising demonstrate that the new network architecture design achieves state-of-the-art performance and the new degradation model can help to significantly improve the practicability. We believe our work can provide useful insights into current denoising research.
Transform your Smartphone into a DSLR Camera: Learning the ISP in the Wild
Mar 22, 2022

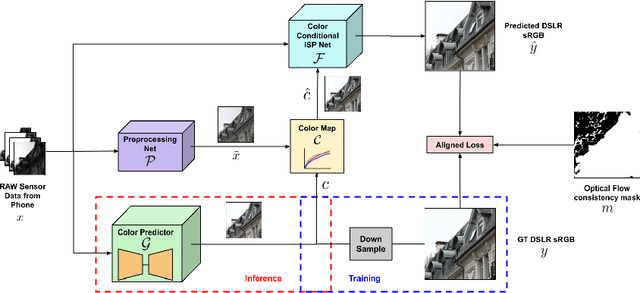

We propose a trainable Image Signal Processing (ISP) framework that produces DSLR quality images given RAW images captured by a smartphone. To address the color misalignments between training image pairs, we employ a color-conditional ISP network and optimize a novel parametric color mapping between each input RAW and reference DSLR image. During inference, we predict the target color image by designing a color prediction network with efficient Global Context Transformer modules. The latter effectively leverage global information to learn consistent color and tone mappings. We further propose a robust masked aligned loss to identify and discard regions with inaccurate motion estimation during training. Lastly, we introduce the ISP in the Wild (ISPW) dataset, consisting of weakly paired phone RAW and DSLR sRGB images. We extensively evaluate our method, setting a new state-of-the-art on two datasets.
Coarse-to-Fine Sparse Transformer for Hyperspectral Image Reconstruction
Mar 09, 2022
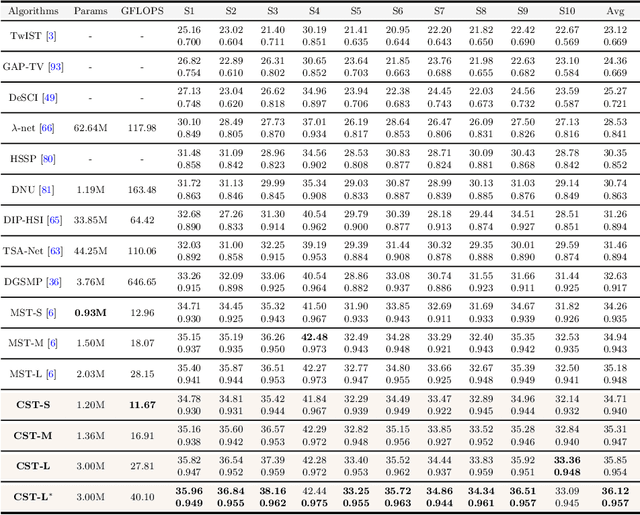
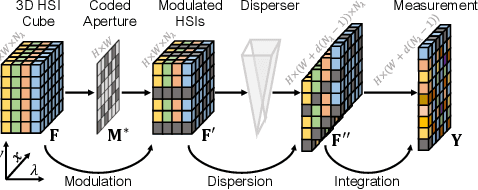
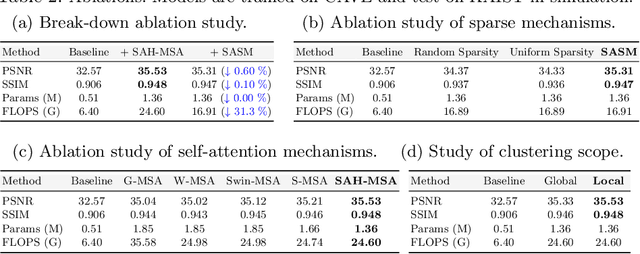
Many algorithms have been developed to solve the inverse problem of coded aperture snapshot spectral imaging (CASSI), i.e., recovering the 3D hyperspectral images (HSIs) from a 2D compressive measurement. In recent years, learning-based methods have demonstrated promising performance and dominated the mainstream research direction. However, existing CNN-based methods show limitations in capturing long-range dependencies and non-local self-similarity. Previous Transformer-based methods densely sample tokens, some of which are uninformative, and calculate the multi-head self-attention (MSA) between some tokens that are unrelated in content. This does not fit the spatially sparse nature of HSI signals and limits the model scalability. In this paper, we propose a novel Transformer-based method, coarse-to-fine sparse Transformer (CST), firstly embedding HSI sparsity into deep learning for HSI reconstruction. In particular, CST uses our proposed spectra-aware screening mechanism (SASM) for coarse patch selecting. Then the selected patches are fed into our customized spectra-aggregation hashing multi-head self-attention (SAH-MSA) for fine pixel clustering and self-similarity capturing. Comprehensive experiments show that our CST significantly outperforms state-of-the-art methods while requiring cheaper computational costs. The code and models will be made public.
HDNet: High-resolution Dual-domain Learning for Spectral Compressive Imaging
Mar 04, 2022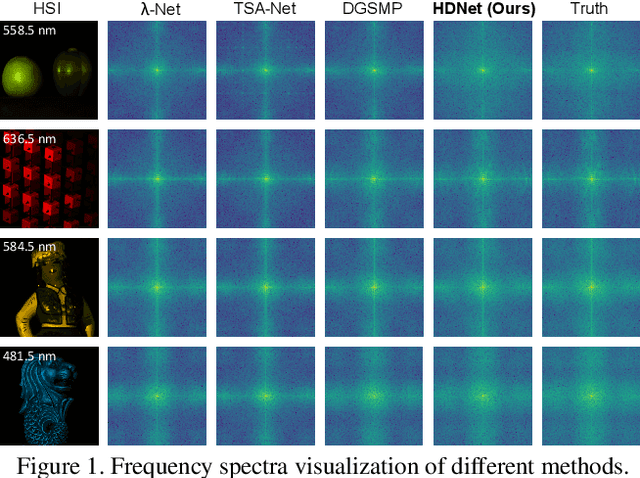
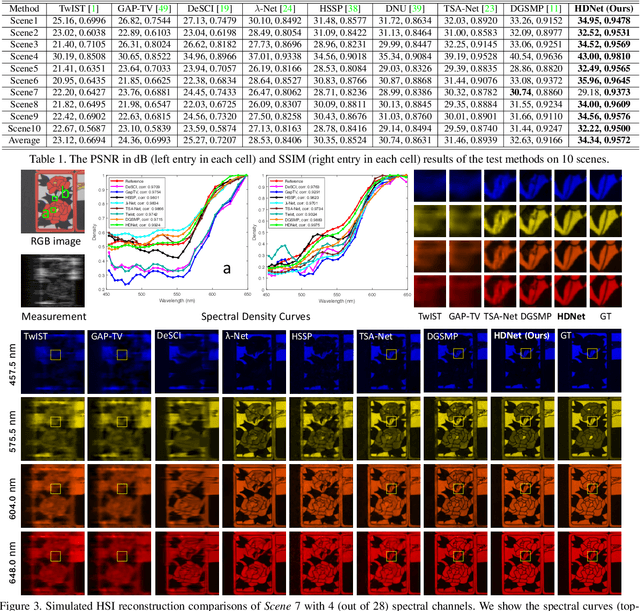
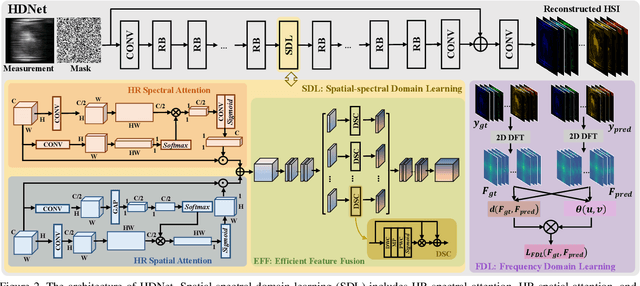

The rapid development of deep learning provides a better solution for the end-to-end reconstruction of hyperspectral image (HSI). However, existing learning-based methods have two major defects. Firstly, networks with self-attention usually sacrifice internal resolution to balance model performance against complexity, losing fine-grained high-resolution (HR) features. Secondly, even if the optimization focusing on spatial-spectral domain learning (SDL) converges to the ideal solution, there is still a significant visual difference between the reconstructed HSI and the truth. Therefore, we propose a high-resolution dual-domain learning network (HDNet) for HSI reconstruction. On the one hand, the proposed HR spatial-spectral attention module with its efficient feature fusion provides continuous and fine pixel-level features. On the other hand, frequency domain learning (FDL) is introduced for HSI reconstruction to narrow the frequency domain discrepancy. Dynamic FDL supervision forces the model to reconstruct fine-grained frequencies and compensate for excessive smoothing and distortion caused by pixel-level losses. The HR pixel-level attention and frequency-level refinement in our HDNet mutually promote HSI perceptual quality. Extensive quantitative and qualitative evaluation experiments show that our method achieves SOTA performance on simulated and real HSI datasets. Code and models will be released.
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
Feb 07, 2022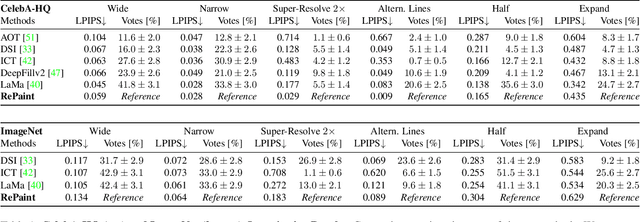
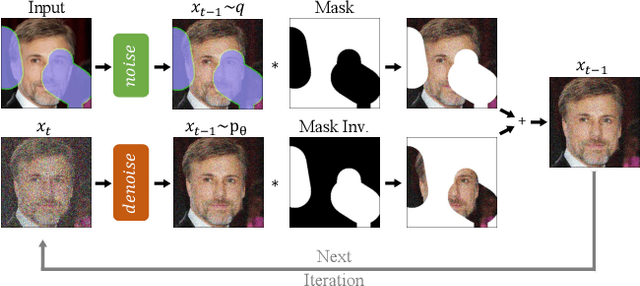


Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: git.io/RePaint
Fast Online Video Super-Resolution with Deformable Attention Pyramid
Feb 03, 2022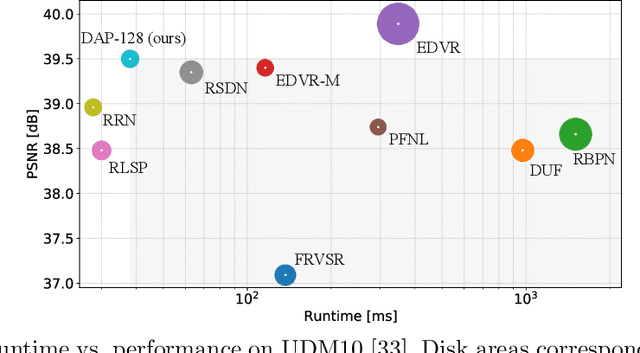

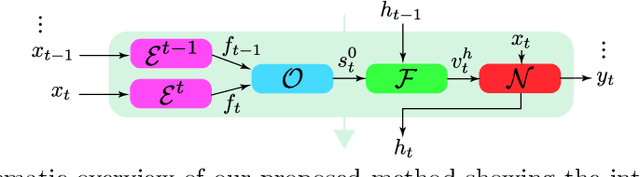

Video super-resolution (VSR) has many applications that pose strict causal, real-time, and latency constraints, including video streaming and TV. We address the VSR problem under these settings, which poses additional important challenges since information from future frames are unavailable. Importantly, designing efficient, yet effective frame alignment and fusion modules remain central problems. In this work, we propose a recurrent VSR architecture based on a deformable attention pyramid (DAP). Our DAP aligns and integrates information from the recurrent state into the current frame prediction. To circumvent the computational cost of traditional attention-based methods, we only attend to a limited number of spatial locations, which are dynamically predicted by the DAP. Comprehensive experiments and analysis of the proposed key innovations show the effectiveness of our approach. We significantly reduce processing time in comparison to state-of-the-art methods, while maintaining a high performance. We surpass state-of-the-art method EDVR-M on two standard benchmarks with a speed-up of over 3x.
VRT: A Video Restoration Transformer
Jan 28, 2022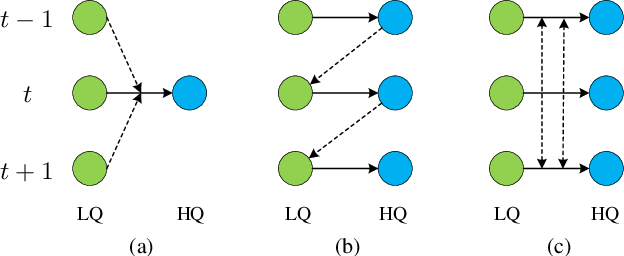
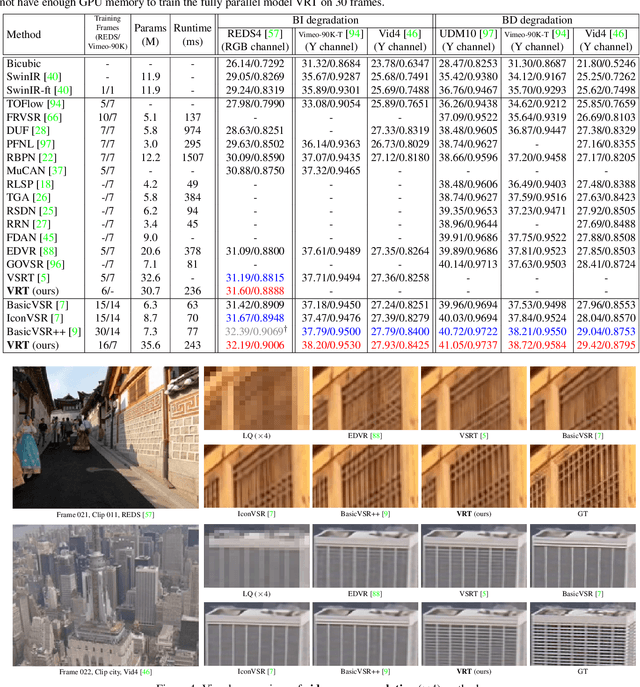
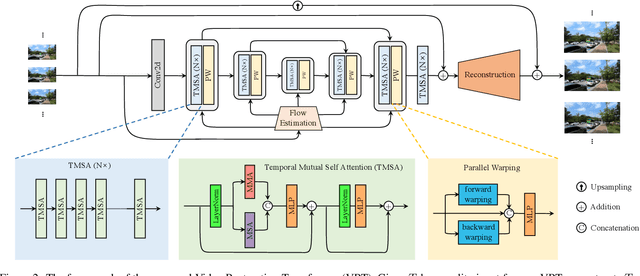
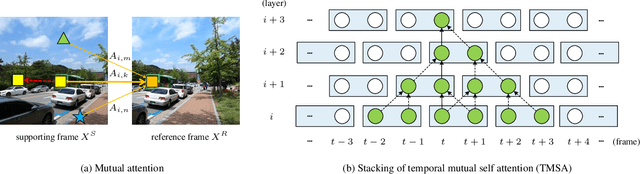
Video restoration (e.g., video super-resolution) aims to restore high-quality frames from low-quality frames. Different from single image restoration, video restoration generally requires to utilize temporal information from multiple adjacent but usually misaligned video frames. Existing deep methods generally tackle with this by exploiting a sliding window strategy or a recurrent architecture, which either is restricted by frame-by-frame restoration or lacks long-range modelling ability. In this paper, we propose a Video Restoration Transformer (VRT) with parallel frame prediction and long-range temporal dependency modelling abilities. More specifically, VRT is composed of multiple scales, each of which consists of two kinds of modules: temporal mutual self attention (TMSA) and parallel warping. TMSA divides the video into small clips, on which mutual attention is applied for joint motion estimation, feature alignment and feature fusion, while self attention is used for feature extraction. To enable cross-clip interactions, the video sequence is shifted for every other layer. Besides, parallel warping is used to further fuse information from neighboring frames by parallel feature warping. Experimental results on three tasks, including video super-resolution, video deblurring and video denoising, demonstrate that VRT outperforms the state-of-the-art methods by large margins ($\textbf{up to 2.16dB}$) on nine benchmark datasets.
Flow-Guided Sparse Transformer for Video Deblurring
Jan 06, 2022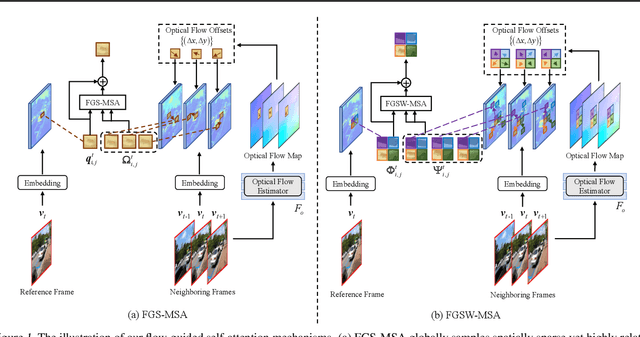
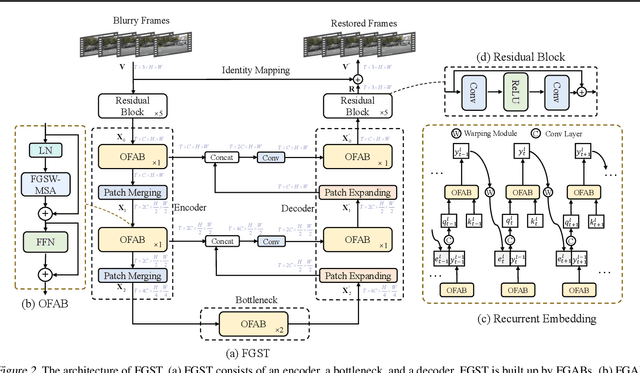

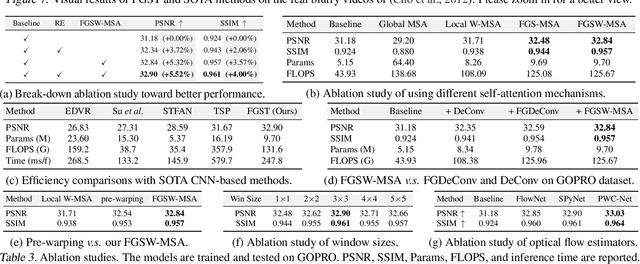
Exploiting similar and sharper scene patches in spatio-temporal neighborhoods is critical for video deblurring. However, CNN-based methods show limitations in capturing long-range dependencies and modeling non-local self-similarity. In this paper, we propose a novel framework, Flow-Guided Sparse Transformer (FGST), for video deblurring. In FGST, we customize a self-attention module, Flow-Guided Sparse Window-based Multi-head Self-Attention (FGSW-MSA). For each $query$ element on the blurry reference frame, FGSW-MSA enjoys the guidance of the estimated optical flow to globally sample spatially sparse yet highly related $key$ elements corresponding to the same scene patch in neighboring frames. Besides, we present a Recurrent Embedding (RE) mechanism to transfer information from past frames and strengthen long-range temporal dependencies. Comprehensive experiments demonstrate that our proposed FGST outperforms state-of-the-art (SOTA) methods on both DVD and GOPRO datasets and even yields more visually pleasing results in real video deblurring. Code and models will be released to the public.
Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model
Nov 26, 2021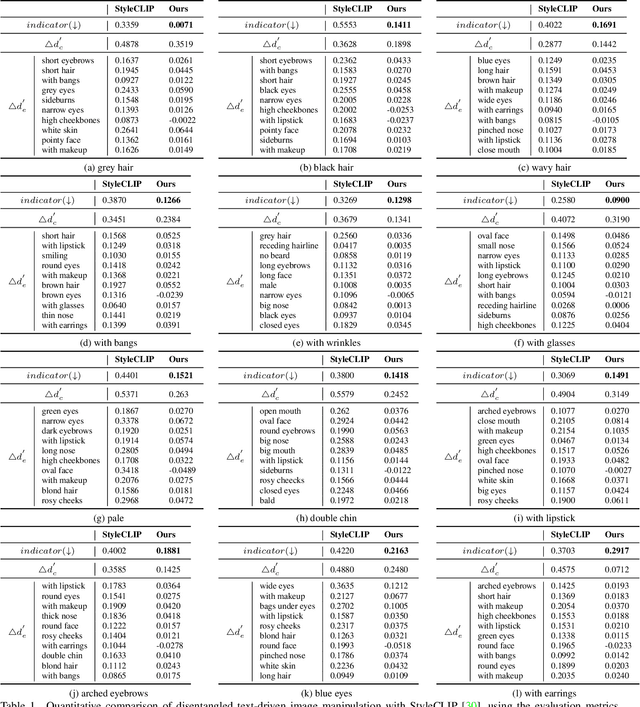
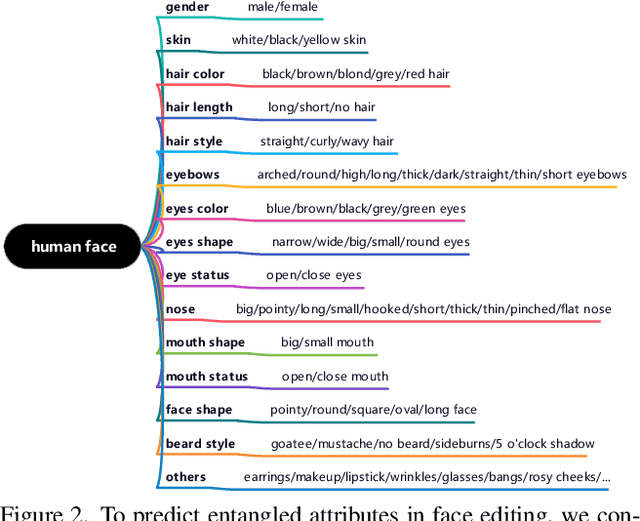
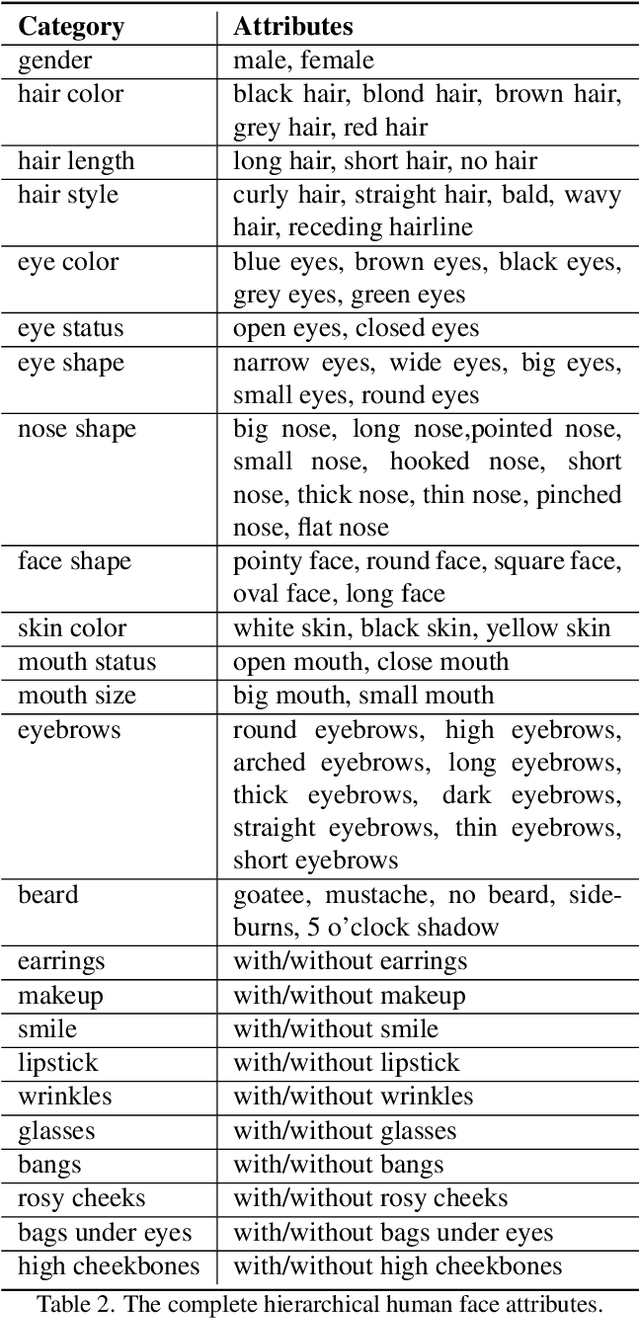

To achieve disentangled image manipulation, previous works depend heavily on manual annotation. Meanwhile, the available manipulations are limited to a pre-defined set the models were trained for. In this paper, we propose a novel framework, i.e., Predict, Prevent, and Evaluate (PPE), for disentangled text-driven image manipulation, which does not need manual annotation and thus is not limited to fixed manipulations. Our method approaches the targets by deeply exploiting the power of the large scale pre-trained vision-language model CLIP. Concretely, we firstly Predict the possibly entangled attributes for a given text command. Then, based on the predicted attributes, we introduce an entanglement loss to Prevent entanglements during training. Finally, we propose a new evaluation metric to Evaluate the disentangled image manipulation. We verify the effectiveness of our method on the challenging face editing task. Extensive experiments show that the proposed PPE framework achieves much better quantitative and qualitative results than the up-to-date StyleCLIP baseline.
Global and Local Alignment Networks for Unpaired Image-to-Image Translation
Nov 19, 2021
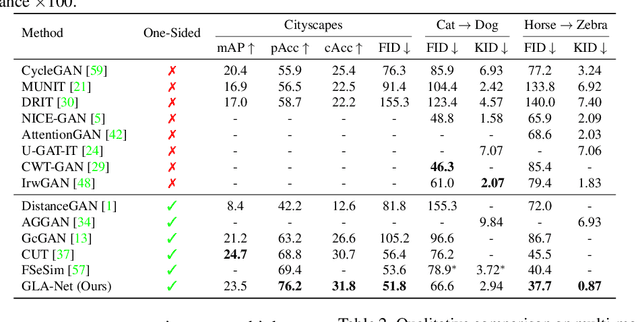
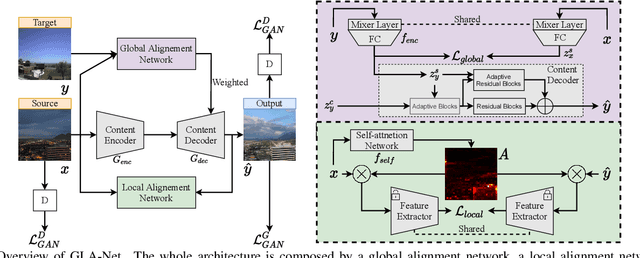
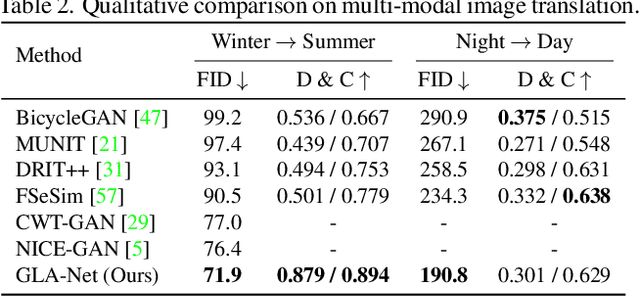
The goal of unpaired image-to-image translation is to produce an output image reflecting the target domain's style while keeping unrelated contents of the input source image unchanged. However, due to the lack of attention to the content change in existing methods, the semantic information from source images suffers from degradation during translation. In the paper, to address this issue, we introduce a novel approach, Global and Local Alignment Networks (GLA-Net). The global alignment network aims to transfer the input image from the source domain to the target domain. To effectively do so, we learn the parameters (mean and standard deviation) of multivariate Gaussian distributions as style features by using an MLP-Mixer based style encoder. To transfer the style more accurately, we employ an adaptive instance normalization layer in the encoder, with the parameters of the target multivariate Gaussian distribution as input. We also adopt regularization and likelihood losses to further reduce the domain gap and produce high-quality outputs. Additionally, we introduce a local alignment network, which employs a pretrained self-supervised model to produce an attention map via a novel local alignment loss, ensuring that the translation network focuses on relevant pixels. Extensive experiments conducted on five public datasets demonstrate that our method effectively generates sharper and more realistic images than existing approaches. Our code is available at https://github.com/ygjwd12345/GLANet.