 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Heterogeneity Hypothesis: Finding Layer-Wise Dissimilated Network Architecture
Paper and Code
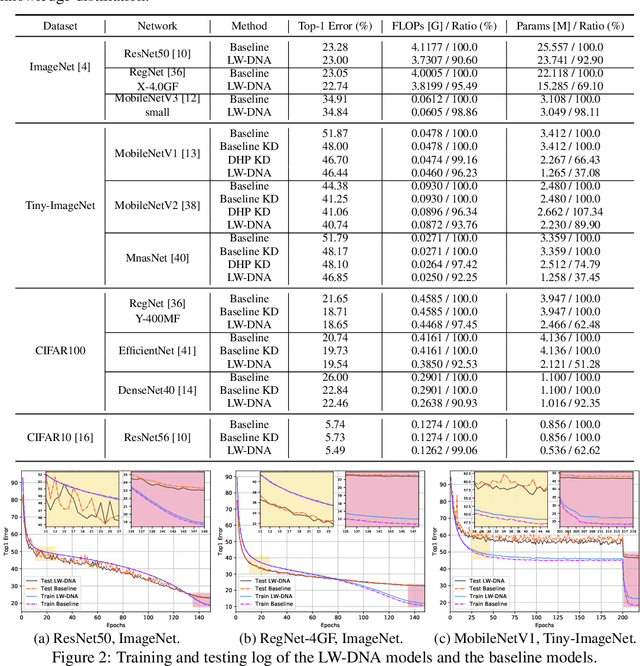
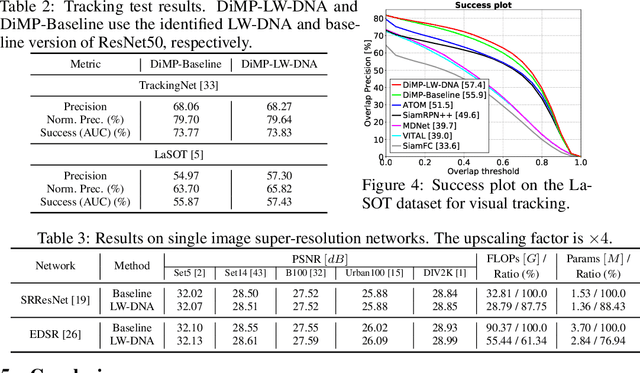
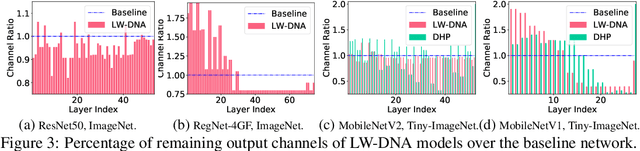
In this paper, we tackle the problem of convolutional neural network design. Instead of focusing on the overall architecture design, we investigate a design space that is usually overlooked, \ie adjusting the channel configurations of predefined networks. We find that this adjustment can be achieved by pruning widened baseline networks and leads to superior performance. Base on that, we articulate the ``heterogeneity hypothesis'': with the same training protocol, there exists a layer-wise dissimilated network architecture (LW-DNA) that can outperform the original network with regular channel configurations under lower level of model complexity. The LW-DNA models are identified without added computational cost and training time compared with the original network. This constraint leads to controlled experiment which directs the focus to the importance of layer-wise specific channel configurations. Multiple sources of hints relate the benefits of LW-DNA models to overfitting, \ie the relative relationship between model complexity and dataset size. Experiments are conducted on various networks and datasets for image classification, visual tracking and image restoration. The resultant LW-DNA models consistently outperform the compared baseline models.