 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering LLMs with Parameterized Skills for Adversarial Long-Horizon Planning
Sep 16, 2025Recent advancements in Large Language Models(LLMs) have led to the development of LLM-based AI agents. A key challenge is the creation of agents that can effectively ground themselves in complex, adversarial long-horizon environments. Existing methods mainly focus on (1) using LLMs as policies to interact with the environment through generating low-level feasible actions, and (2) utilizing LLMs to generate high-level tasks or language guides to stimulate action generation. However, the former struggles to generate reliable actions, while the latter relies heavily on expert experience to translate high-level tasks into specific action sequences. To address these challenges, we introduce the Plan with Language, Act with Parameter (PLAP) planning framework that facilitates the grounding of LLM-based agents in long-horizon environments. The PLAP method comprises three key components: (1) a skill library containing environment-specific parameterized skills, (2) a skill planner powered by LLMs, and (3) a skill executor converting the parameterized skills into executable action sequences. We implement PLAP in MicroRTS, a long-horizon real-time strategy game that provides an unfamiliar and challenging environment for LLMs. The experimental results demonstrate the effectiveness of PLAP. In particular, GPT-4o-driven PLAP in a zero-shot setting outperforms 80% of baseline agents, and Qwen2-72B-driven PLAP, with carefully crafted few-shot examples, surpasses the top-tier scripted agent, CoacAI. Additionally, we design comprehensive evaluation metrics and test 6 closed-source and 2 open-source LLMs within the PLAP framework, ultimately releasing an LLM leaderboard ranking long-horizon skill planning ability. Our code is available at https://github.com/AI-Research-TeamX/PLAP.
Self-Guided Function Calling in Large Language Models via Stepwise Experience Recall
Aug 21, 2025Function calling enables large language models (LLMs) to interact with external systems by leveraging tools and APIs. When faced with multi-step tool usage, LLMs still struggle with tool selection, parameter generation, and tool-chain planning. Existing methods typically rely on manually designing task-specific demonstrations, or retrieving from a curated library. These approaches demand substantial expert effort and prompt engineering becomes increasingly complex and inefficient as tool diversity and task difficulty scale. To address these challenges, we propose a self-guided method, Stepwise Experience Recall (SEER), which performs fine-grained, stepwise retrieval from a continually updated experience pool. Instead of relying on static or manually curated library, SEER incrementally augments the experience pool with past successful trajectories, enabling continuous expansion of the pool and improved model performance over time. Evaluated on the ToolQA benchmark, SEER achieves an average improvement of 6.1\% on easy and 4.7\% on hard questions. We further test SEER on $\tau$-bench, which includes two real-world domains. Powered by Qwen2.5-7B and Qwen2.5-72B models, SEER demonstrates substantial accuracy gains of 7.44\% and 23.38\%, respectively.
MSCI: Addressing CLIP's Inherent Limitations for Compositional Zero-Shot Learning
May 15, 2025



Compositional Zero-Shot Learning (CZSL) aims to recognize unseen state-object combinations by leveraging known combinations. Existing studies basically rely on the cross-modal alignment capabilities of CLIP but tend to overlook its limitations in capturing fine-grained local features, which arise from its architectural and training paradigm. To address this issue, we propose a Multi-Stage Cross-modal Interaction (MSCI) model that effectively explores and utilizes intermediate-layer information from CLIP's visual encoder. Specifically, we design two self-adaptive aggregators to extract local information from low-level visual features and integrate global information from high-level visual features, respectively. These key information are progressively incorporated into textual representations through a stage-by-stage interaction mechanism, significantly enhancing the model's perception capability for fine-grained local visual information. Additionally, MSCI dynamically adjusts the attention weights between global and local visual information based on different combinations, as well as different elements within the same combination, allowing it to flexibly adapt to diverse scenarios. Experiments on three widely used datasets fully validate the effectiveness and superiority of the proposed model. Data and code are available at https://github.com/ltpwy/MSCI.
Strategy-Augmented Planning for Large Language Models via Opponent Exploitation
May 13, 2025Efficiently modeling and exploiting opponents is a long-standing challenge in adversarial domains. Large Language Models (LLMs) trained on extensive textual data have recently demonstrated outstanding performance in general tasks, introducing new research directions for opponent modeling. Some studies primarily focus on directly using LLMs to generate decisions based on the elaborate prompt context that incorporates opponent descriptions, while these approaches are limited to scenarios where LLMs possess adequate domain expertise. To address that, we introduce a two-stage Strategy-Augmented Planning (SAP) framework that significantly enhances the opponent exploitation capabilities of LLM-based agents by utilizing a critical component, the Strategy Evaluation Network (SEN). Specifically, in the offline stage, we construct an explicit strategy space and subsequently collect strategy-outcome pair data for training the SEN network. During the online phase, SAP dynamically recognizes the opponent's strategies and greedily exploits them by searching best response strategy on the well-trained SEN, finally translating strategy to a course of actions by carefully designed prompts. Experimental results show that SAP exhibits robust generalization capabilities, allowing it to perform effectively not only against previously encountered opponent strategies but also against novel, unseen strategies. In the MicroRTS environment, SAP achieves a 85.35\% performance improvement over baseline methods and matches the competitiveness of reinforcement learning approaches against state-of-the-art (SOTA) rule-based AI.
TUMS: Enhancing Tool-use Abilities of LLMs with Multi-structure Handlers
May 13, 2025Recently, large language models(LLMs) have played an increasingly important role in solving a wide range of NLP tasks, leveraging their capabilities of natural language understanding and generating. Integration with external tools further enhances LLMs' effectiveness, providing more precise, timely, and specialized responses. However, LLMs still encounter difficulties with non-executable actions and improper actions, which are primarily attributed to incorrect parameters. The process of generating parameters by LLMs is confined to the tool level, employing the coarse-grained strategy without considering the different difficulties of various tools. To address this issue, we propose TUMS, a novel framework designed to enhance the tool-use capabilities of LLMs by transforming tool-level processing into parameter-level processing. Specifically, our framework consists of four key components: (1) an intent recognizer that identifies the user's intent to help LLMs better understand the task; (2) a task decomposer that breaks down complex tasks into simpler subtasks, each involving a tool call; (3) a subtask processor equipped with multi-structure handlers to generate accurate parameters; and (4) an executor. Our empirical studies have evidenced the effectiveness and efficiency of the TUMS framework with an average of 19.6\% and 50.6\% improvement separately on easy and hard benchmarks of ToolQA, meanwhile, we demonstrated the key contribution of each part with ablation experiments, offering more insights and stimulating future research on Tool-augmented LLMs.
Taylor Unswift: Secured Weight Release for Large Language Models via Taylor Expansion
Oct 06, 2024



Ensuring the security of released large language models (LLMs) poses a significant dilemma, as existing mechanisms either compromise ownership rights or raise data privacy concerns. To address this dilemma, we introduce TaylorMLP to protect the ownership of released LLMs and prevent their abuse. Specifically, TaylorMLP preserves the ownership of LLMs by transforming the weights of LLMs into parameters of Taylor-series. Instead of releasing the original weights, developers can release the Taylor-series parameters with users, thereby ensuring the security of LLMs. Moreover, TaylorMLP can prevent abuse of LLMs by adjusting the generation speed. It can induce low-speed token generation for the protected LLMs by increasing the terms in the Taylor-series. This intentional delay helps LLM developers prevent potential large-scale unauthorized uses of their models. Empirical experiments across five datasets and three LLM architectures demonstrate that TaylorMLP induces over 4x increase in latency, producing the tokens precisely matched with original LLMs. Subsequent defensive experiments further confirm that TaylorMLP effectively prevents users from reconstructing the weight values based on downstream datasets.
Learning the Market: Sentiment-Based Ensemble Trading Agents
Feb 02, 2024



We propose the integration of sentiment analysis and deep-reinforcement learning ensemble algorithms for stock trading, and design a strategy capable of dynamically altering its employed agent given concurrent market sentiment. In particular, we create a simple-yet-effective method for extracting news sentiment and combine this with general improvements upon existing works, resulting in automated trading agents that effectively consider both qualitative market factors and quantitative stock data. We show that our approach results in a strategy that is profitable, robust, and risk-minimal -- outperforming the traditional ensemble strategy as well as single agent algorithms and market metrics. Our findings determine that the conventional practice of switching ensemble agents every fixed-number of months is sub-optimal, and that a dynamic sentiment-based framework greatly unlocks additional performance within these agents. Furthermore, as we have designed our algorithm with simplicity and efficiency in mind, we hypothesize that the transition of our method from historical evaluation towards real-time trading with live data should be relatively simple.
Winner-Take-All Column Row Sampling for Memory Efficient Adaptation of Language Model
May 24, 2023With the rapid growth in model size, fine-tuning the large pre-trained language model has become increasingly difficult due to its extensive memory usage. Previous works usually focus on reducing the number of trainable parameters in the network. While the model parameters do contribute to memory usage, the primary memory bottleneck during training arises from storing feature maps, also known as activations, as they are crucial for gradient calculation. Notably, neural networks are usually trained using stochastic gradient descent. We argue that in stochastic optimization, models can handle noisy gradients as long as the gradient estimator is unbiased with reasonable variance. Following this motivation, we propose a new family of unbiased estimators called WTA-CRS, for matrix production with reduced variance, which only requires storing the sub-sampled activations for calculating the gradient. Our work provides both theoretical and experimental evidence that, in the context of tuning transformers, our proposed estimators exhibit lower variance compared to existing ones. By replacing the linear operation with our approximated one in transformers, we can achieve up to 2.7$\times$ peak memory reduction with almost no accuracy drop and enables up to $6.4\times$ larger batch size. Under the same hardware, WTA-CRS enables better down-streaming task performance by applying larger models and/or faster training speed with larger batch sizes.
Improving CNN-base Stock Trading By Considering Data Heterogeneity and Burst
Mar 14, 2023



In recent years, there have been quite a few attempts to apply intelligent techniques to financial trading, i.e., constructing automatic and intelligent trading framework based on historical stock price. Due to the unpredictable, uncertainty and volatile nature of financial market, researchers have also resorted to deep learning to construct the intelligent trading framework. In this paper, we propose to use CNN as the core functionality of such framework, because it is able to learn the spatial dependency (i.e., between rows and columns) of the input data. However, different with existing deep learning-based trading frameworks, we develop novel normalization process to prepare the stock data. In particular, we first empirically observe that the stock data is intrinsically heterogeneous and bursty, and then validate the heterogeneity and burst nature of stock data from a statistical perspective. Next, we design the data normalization method in a way such that the data heterogeneity is preserved and bursty events are suppressed. We verify out developed CNN-based trading framework plus our new normalization method on 29 stocks. Experiment results show that our approach can outperform other comparing approaches.
Grad-CAM guided channel-spatial attention module for fine-grained visual classification
Jan 24, 2021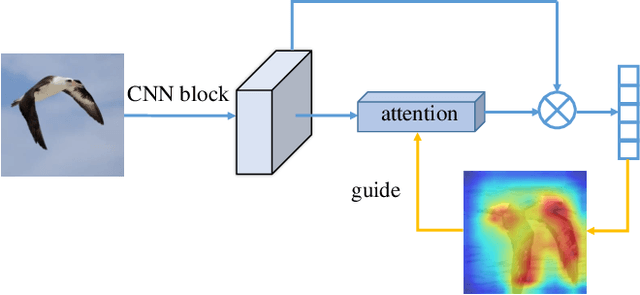
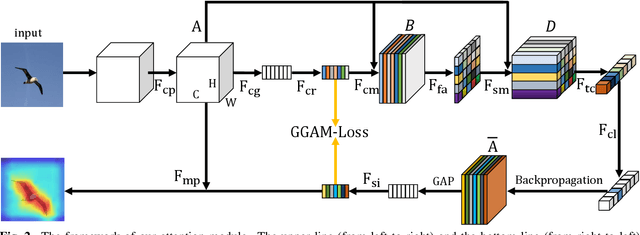
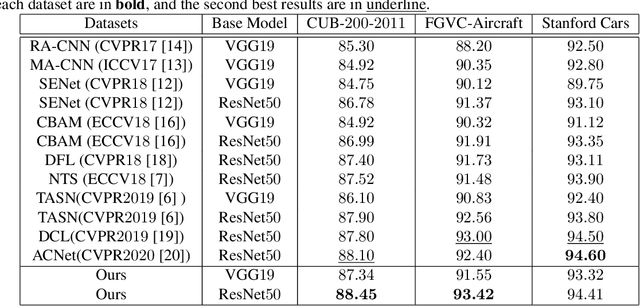
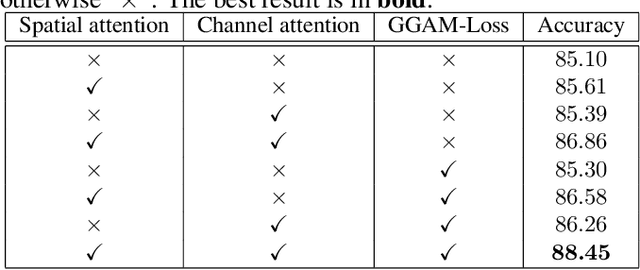
Fine-grained visual classification (FGVC) is becoming an important research field, due to its wide applications and the rapid development of computer vision technologies. The current state-of-the-art (SOTA) methods in the FGVC usually employ attention mechanisms to first capture the semantic parts and then discover their subtle differences between distinct classes. The channel-spatial attention mechanisms, which focus on the discriminative channels and regions simultaneously, have significantly improved the classification performance. However, the existing attention modules are poorly guided since part-based detectors in the FGVC depend on the network learning ability without the supervision of part annotations. As obtaining such part annotations is labor-intensive, some visual localization and explanation methods, such as gradient-weighted class activation mapping (Grad-CAM), can be utilized for supervising the attention mechanism. We propose a Grad-CAM guided channel-spatial attention module for the FGVC, which employs the Grad-CAM to supervise and constrain the attention weights by generating the coarse localization maps. To demonstrate the effectiveness of the proposed method, we conduct comprehensive experiments on three popular FGVC datasets, including CUB-$200$-$2011$, Stanford Cars, and FGVC-Aircraft datasets. The proposed method outperforms the SOTA attention modules in the FGVC task. In addition, visualizations of feature maps also demonstrate the superiority of the proposed method against the SOTA approaches.