 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn Like Humans: Use Meta-cognitive Reflection for Efficient Self-Improvement
Jan 17, 2026While Large Language Models (LLMs) enable complex autonomous behavior, current agents remain constrained by static, human-designed prompts that limit adaptability. Existing self-improving frameworks attempt to bridge this gap but typically rely on inefficient, multi-turn recursive loops that incur high computational costs. To address this, we propose Metacognitive Agent Reflective Self-improvement (MARS), a framework that achieves efficient self-evolution within a single recurrence cycle. Inspired by educational psychology, MARS mimics human learning by integrating principle-based reflection (abstracting normative rules to avoid errors) and procedural reflection (deriving step-by-step strategies for success). By synthesizing these insights into optimized instructions, MARS allows agents to systematically refine their reasoning logic without continuous online feedback. Extensive experiments on six benchmarks demonstrate that MARS outperforms state-of-the-art self-evolving systems while significantly reducing computational overhead.
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
T2I-Based Physical-World Appearance Attack against Traffic Sign Recognition Systems in Autonomous Driving
Nov 17, 2025Traffic Sign Recognition (TSR) systems play a critical role in Autonomous Driving (AD) systems, enabling real-time detection of road signs, such as STOP and speed limit signs. While these systems are increasingly integrated into commercial vehicles, recent research has exposed their vulnerability to physical-world adversarial appearance attacks. In such attacks, carefully crafted visual patterns are misinterpreted by TSR models as legitimate traffic signs, while remaining inconspicuous or benign to human observers. However, existing adversarial appearance attacks suffer from notable limitations. Pixel-level perturbation-based methods often lack stealthiness and tend to overfit to specific surrogate models, resulting in poor transferability to real-world TSR systems. On the other hand, text-to-image (T2I) diffusion model-based approaches demonstrate limited effectiveness and poor generalization to out-of-distribution sign types. In this paper, we present DiffSign, a novel T2I-based appearance attack framework designed to generate physically robust, highly effective, transferable, practical, and stealthy appearance attacks against TSR systems. To overcome the limitations of prior approaches, we propose a carefully designed attack pipeline that integrates CLIP-based loss and masked prompts to improve attack focus and controllability. We also propose two novel style customization methods to guide visual appearance and improve out-of-domain traffic sign attack generalization and attack stealthiness. We conduct extensive evaluations of DiffSign under varied real-world conditions, including different distances, angles, light conditions, and sign categories. Our method achieves an average physical-world attack success rate of 83.3%, leveraging DiffSign's high effectiveness in attack transferability.
Beyond Pixels: Semantic-aware Typographic Attack for Geo-Privacy Protection
Nov 16, 2025Large Visual Language Models (LVLMs) now pose a serious yet overlooked privacy threat, as they can infer a social media user's geolocation directly from shared images, leading to unintended privacy leakage. While adversarial image perturbations provide a potential direction for geo-privacy protection, they require relatively strong distortions to be effective against LVLMs, which noticeably degrade visual quality and diminish an image's value for sharing. To overcome this limitation, we identify typographical attacks as a promising direction for protecting geo-privacy by adding text extension outside the visual content. We further investigate which textual semantics are effective in disrupting geolocation inference and design a two-stage, semantics-aware typographical attack that generates deceptive text to protect user privacy. Extensive experiments across three datasets demonstrate that our approach significantly reduces geolocation prediction accuracy of five state-of-the-art commercial LVLMs, establishing a practical and visually-preserving protection strategy against emerging geo-privacy threats.
Retrieval Augmented Generation-Enhanced Distributed LLM Agents for Generalizable Traffic Signal Control with Emergency Vehicles
Oct 30, 2025



With increasing urban traffic complexity, Traffic Signal Control (TSC) is essential for optimizing traffic flow and improving road safety. Large Language Models (LLMs) emerge as promising approaches for TSC. However, they are prone to hallucinations in emergencies, leading to unreliable decisions that may cause substantial delays for emergency vehicles. Moreover, diverse intersection types present substantial challenges for traffic state encoding and cross-intersection training, limiting generalization across heterogeneous intersections. Therefore, this paper proposes Retrieval Augmented Generation (RAG)-enhanced distributed LLM agents with Emergency response for Generalizable TSC (REG-TSC). Firstly, this paper presents an emergency-aware reasoning framework, which dynamically adjusts reasoning depth based on the emergency scenario and is equipped with a novel Reviewer-based Emergency RAG (RERAG) to distill specific knowledge and guidance from historical cases, enhancing the reliability and rationality of agents' emergency decisions. Secondly, this paper designs a type-agnostic traffic representation and proposes a Reward-guided Reinforced Refinement (R3) for heterogeneous intersections. R3 adaptively samples training experience from diverse intersections with environment feedback-based priority and fine-tunes LLM agents with a designed reward-weighted likelihood loss, guiding REG-TSC toward high-reward policies across heterogeneous intersections. On three real-world road networks with 17 to 177 heterogeneous intersections, extensive experiments show that REG-TSC reduces travel time by 42.00%, queue length by 62.31%, and emergency vehicle waiting time by 83.16%, outperforming other state-of-the-art methods.
OBJVanish: Physically Realizable Text-to-3D Adv. Generation of LiDAR-Invisible Objects
Oct 08, 2025LiDAR-based 3D object detectors are fundamental to autonomous driving, where failing to detect objects poses severe safety risks. Developing effective 3D adversarial attacks is essential for thoroughly testing these detection systems and exposing their vulnerabilities before real-world deployment. However, existing adversarial attacks that add optimized perturbations to 3D points have two critical limitations: they rarely cause complete object disappearance and prove difficult to implement in physical environments. We introduce the text-to-3D adversarial generation method, a novel approach enabling physically realizable attacks that can generate 3D models of objects truly invisible to LiDAR detectors and be easily realized in the real world. Specifically, we present the first empirical study that systematically investigates the factors influencing detection vulnerability by manipulating the topology, connectivity, and intensity of individual pedestrian 3D models and combining pedestrians with multiple objects within the CARLA simulation environment. Building on the insights, we propose the physically-informed text-to-3D adversarial generation (Phy3DAdvGen) that systematically optimizes text prompts by iteratively refining verbs, objects, and poses to produce LiDAR-invisible pedestrians. To ensure physical realizability, we construct a comprehensive object pool containing 13 3D models of real objects and constrain Phy3DAdvGen to generate 3D objects based on combinations of objects in this set. Extensive experiments demonstrate that our approach can generate 3D pedestrians that evade six state-of-the-art (SOTA) LiDAR 3D detectors in both CARLA simulation and physical environments, thereby highlighting vulnerabilities in safety-critical applications.
FOCUS: Frequency-Optimized Conditioning of DiffUSion Models for mitigating catastrophic forgetting during Test-Time Adaptation
Aug 20, 2025Test-time adaptation enables models to adapt to evolving domains. However, balancing the tradeoff between preserving knowledge and adapting to domain shifts remains challenging for model adaptation methods, since adapting to domain shifts can induce forgetting of task-relevant knowledge. To address this problem, we propose FOCUS, a novel frequency-based conditioning approach within a diffusion-driven input-adaptation framework. Utilising learned, spatially adaptive frequency priors, our approach conditions the reverse steps during diffusion-driven denoising to preserve task-relevant semantic information for dense prediction. FOCUS leverages a trained, lightweight, Y-shaped Frequency Prediction Network (Y-FPN) that disentangles high and low frequency information from noisy images. This minimizes the computational costs involved in implementing our approach in a diffusion-driven framework. We train Y-FPN with FrequencyMix, a novel data augmentation method that perturbs the images across diverse frequency bands, which improves the robustness of our approach to diverse corruptions. We demonstrate the effectiveness of FOCUS for semantic segmentation and monocular depth estimation across 15 corruption types and three datasets, achieving state-of-the-art averaged performance. In addition to improving standalone performance, FOCUS complements existing model adaptation methods since we can derive pseudo labels from FOCUS-denoised images for additional supervision. Even under limited, intermittent supervision with the pseudo labels derived from the FOCUS denoised images, we show that FOCUS mitigates catastrophic forgetting for recent model adaptation methods.
PhysPatch: A Physically Realizable and Transferable Adversarial Patch Attack for Multimodal Large Language Models-based Autonomous Driving Systems
Aug 07, 2025

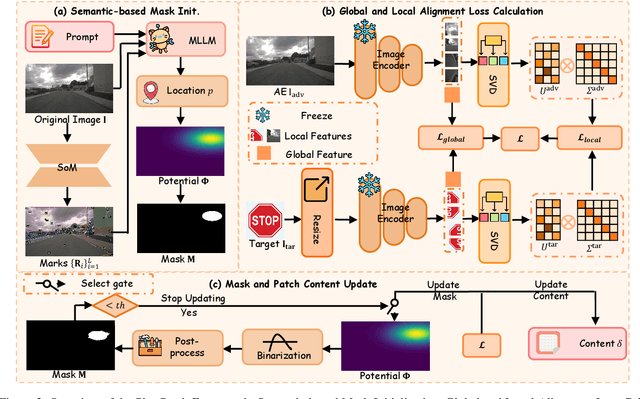

Multimodal Large Language Models (MLLMs) are becoming integral to autonomous driving (AD) systems due to their strong vision-language reasoning capabilities. However, MLLMs are vulnerable to adversarial attacks, particularly adversarial patch attacks, which can pose serious threats in real-world scenarios. Existing patch-based attack methods are primarily designed for object detection models and perform poorly when transferred to MLLM-based systems due to the latter's complex architectures and reasoning abilities. To address these limitations, we propose PhysPatch, a physically realizable and transferable adversarial patch framework tailored for MLLM-based AD systems. PhysPatch jointly optimizes patch location, shape, and content to enhance attack effectiveness and real-world applicability. It introduces a semantic-based mask initialization strategy for realistic placement, an SVD-based local alignment loss with patch-guided crop-resize to improve transferability, and a potential field-based mask refinement method. Extensive experiments across open-source, commercial, and reasoning-capable MLLMs demonstrate that PhysPatch significantly outperforms prior methods in steering MLLM-based AD systems toward target-aligned perception and planning outputs. Moreover, PhysPatch consistently places adversarial patches in physically feasible regions of AD scenes, ensuring strong real-world applicability and deployability.
Investigating Training Data Detection in AI Coders
Jul 23, 2025Recent advances in code large language models (CodeLLMs) have made them indispensable tools in modern software engineering. However, these models occasionally produce outputs that contain proprietary or sensitive code snippets, raising concerns about potential non-compliant use of training data, and posing risks to privacy and intellectual property. To ensure responsible and compliant deployment of CodeLLMs, training data detection (TDD) has become a critical task. While recent TDD methods have shown promise in natural language settings, their effectiveness on code data remains largely underexplored. This gap is particularly important given code's structured syntax and distinct similarity criteria compared to natural language. To address this, we conduct a comprehensive empirical study of seven state-of-the-art TDD methods on source code data, evaluating their performance across eight CodeLLMs. To support this evaluation, we introduce CodeSnitch, a function-level benchmark dataset comprising 9,000 code samples in three programming languages, each explicitly labeled as either included or excluded from CodeLLM training. Beyond evaluation on the original CodeSnitch, we design targeted mutation strategies to test the robustness of TDD methods under three distinct settings. These mutation strategies are grounded in the well-established Type-1 to Type-4 code clone detection taxonomy. Our study provides a systematic assessment of current TDD techniques for code and offers insights to guide the development of more effective and robust detection methods in the future.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.