 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking Heterogeneous Data with Coordinated Agent Flows for Social Media Analysis
Oct 30, 2025Social media platforms generate massive volumes of heterogeneous data, capturing user behaviors, textual content, temporal dynamics, and network structures. Analyzing such data is crucial for understanding phenomena such as opinion dynamics, community formation, and information diffusion. However, discovering insights from this complex landscape is exploratory, conceptually challenging, and requires expertise in social media mining and visualization. Existing automated approaches, though increasingly leveraging large language models (LLMs), remain largely confined to structured tabular data and cannot adequately address the heterogeneity of social media analysis. We present SIA (Social Insight Agents), an LLM agent system that links heterogeneous multi-modal data -- including raw inputs (e.g., text, network, and behavioral data), intermediate outputs, mined analytical results, and visualization artifacts -- through coordinated agent flows. Guided by a bottom-up taxonomy that connects insight types with suitable mining and visualization techniques, SIA enables agents to plan and execute coherent analysis strategies. To ensure multi-modal integration, it incorporates a data coordinator that unifies tabular, textual, and network data into a consistent flow. Its interactive interface provides a transparent workflow where users can trace, validate, and refine the agent's reasoning, supporting both adaptability and trustworthiness. Through expert-centered case studies and quantitative evaluation, we show that SIA effectively discovers diverse and meaningful insights from social media while supporting human-agent collaboration in complex analytical tasks.
TruePose: Human-Parsing-guided Attention Diffusion for Full-ID Preserving Pose Transfer
Feb 05, 2025Pose-Guided Person Image Synthesis (PGPIS) generates images that maintain a subject's identity from a source image while adopting a specified target pose (e.g., skeleton). While diffusion-based PGPIS methods effectively preserve facial features during pose transformation, they often struggle to accurately maintain clothing details from the source image throughout the diffusion process. This limitation becomes particularly problematic when there is a substantial difference between the source and target poses, significantly impacting PGPIS applications in the fashion industry where clothing style preservation is crucial for copyright protection. Our analysis reveals that this limitation primarily stems from the conditional diffusion model's attention modules failing to adequately capture and preserve clothing patterns. To address this limitation, we propose human-parsing-guided attention diffusion, a novel approach that effectively preserves both facial and clothing appearance while generating high-quality results. We propose a human-parsing-aware Siamese network that consists of three key components: dual identical UNets (TargetNet for diffusion denoising and SourceNet for source image embedding extraction), a human-parsing-guided fusion attention (HPFA), and a CLIP-guided attention alignment (CAA). The HPFA and CAA modules can embed the face and clothes patterns into the target image generation adaptively and effectively. Extensive experiments on both the in-shop clothes retrieval benchmark and the latest in-the-wild human editing dataset demonstrate our method's significant advantages over 13 baseline approaches for preserving both facial and clothes appearance in the source image.
Sonic: Shifting Focus to Global Audio Perception in Portrait Animation
Nov 25, 2024



The study of talking face generation mainly explores the intricacies of synchronizing facial movements and crafting visually appealing, temporally-coherent animations. However, due to the limited exploration of global audio perception, current approaches predominantly employ auxiliary visual and spatial knowledge to stabilize the movements, which often results in the deterioration of the naturalness and temporal inconsistencies.Considering the essence of audio-driven animation, the audio signal serves as the ideal and unique priors to adjust facial expressions and lip movements, without resorting to interference of any visual signals. Based on this motivation, we propose a novel paradigm, dubbed as Sonic, to {s}hift f{o}cus on the exploration of global audio per{c}ept{i}o{n}.To effectively leverage global audio knowledge, we disentangle it into intra- and inter-clip audio perception and collaborate with both aspects to enhance overall perception.For the intra-clip audio perception, 1). \textbf{Context-enhanced audio learning}, in which long-range intra-clip temporal audio knowledge is extracted to provide facial expression and lip motion priors implicitly expressed as the tone and speed of speech. 2). \textbf{Motion-decoupled controller}, in which the motion of the head and expression movement are disentangled and independently controlled by intra-audio clips. Most importantly, for inter-clip audio perception, as a bridge to connect the intra-clips to achieve the global perception, \textbf{Time-aware position shift fusion}, in which the global inter-clip audio information is considered and fused for long-audio inference via through consecutively time-aware shifted windows. Extensive experiments demonstrate that the novel audio-driven paradigm outperform existing SOTA methodologies in terms of video quality, temporally consistency, lip synchronization precision, and motion diversity.
FoolSDEdit: Deceptively Steering Your Edits Towards Targeted Attribute-aware Distribution
Feb 06, 2024Guided image synthesis methods, like SDEdit based on the diffusion model, excel at creating realistic images from user inputs such as stroke paintings. However, existing efforts mainly focus on image quality, often overlooking a key point: the diffusion model represents a data distribution, not individual images. This introduces a low but critical chance of generating images that contradict user intentions, raising ethical concerns. For example, a user inputting a stroke painting with female characteristics might, with some probability, get male faces from SDEdit. To expose this potential vulnerability, we aim to build an adversarial attack forcing SDEdit to generate a specific data distribution aligned with a specified attribute (e.g., female), without changing the input's attribute characteristics. We propose the Targeted Attribute Generative Attack (TAGA), using an attribute-aware objective function and optimizing the adversarial noise added to the input stroke painting. Empirical studies reveal that traditional adversarial noise struggles with TAGA, while natural perturbations like exposure and motion blur easily alter generated images' attributes. To execute effective attacks, we introduce FoolSDEdit: We design a joint adversarial exposure and blur attack, adding exposure and motion blur to the stroke painting and optimizing them together. We optimize the execution strategy of various perturbations, framing it as a network architecture search problem. We create the SuperPert, a graph representing diverse execution strategies for different perturbations. After training, we obtain the optimized execution strategy for effective TAGA against SDEdit. Comprehensive experiments on two datasets show our method compelling SDEdit to generate a targeted attribute-aware data distribution, significantly outperforming baselines.
An Embedding-Based Grocery Search Model at Instacart
Sep 12, 2022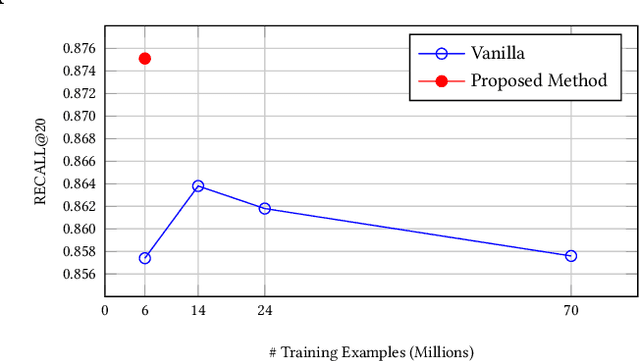

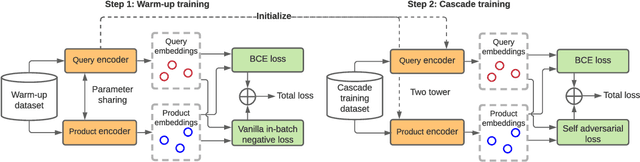
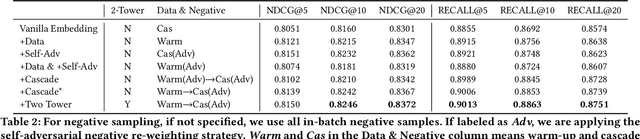
The key to e-commerce search is how to best utilize the large yet noisy log data. In this paper, we present our embedding-based model for grocery search at Instacart. The system learns query and product representations with a two-tower transformer-based encoder architecture. To tackle the cold-start problem, we focus on content-based features. To train the model efficiently on noisy data, we propose a self-adversarial learning method and a cascade training method. AccOn an offline human evaluation dataset, we achieve 10% relative improvement in RECALL@20, and for online A/B testing, we achieve 4.1% cart-adds per search (CAPS) and 1.5% gross merchandise value (GMV) improvement. We describe how we train and deploy the embedding based search model and give a detailed analysis of the effectiveness of our method.
Point-wise posteriori phase estimation in high-precision fringe projection profilometry
Jul 31, 2021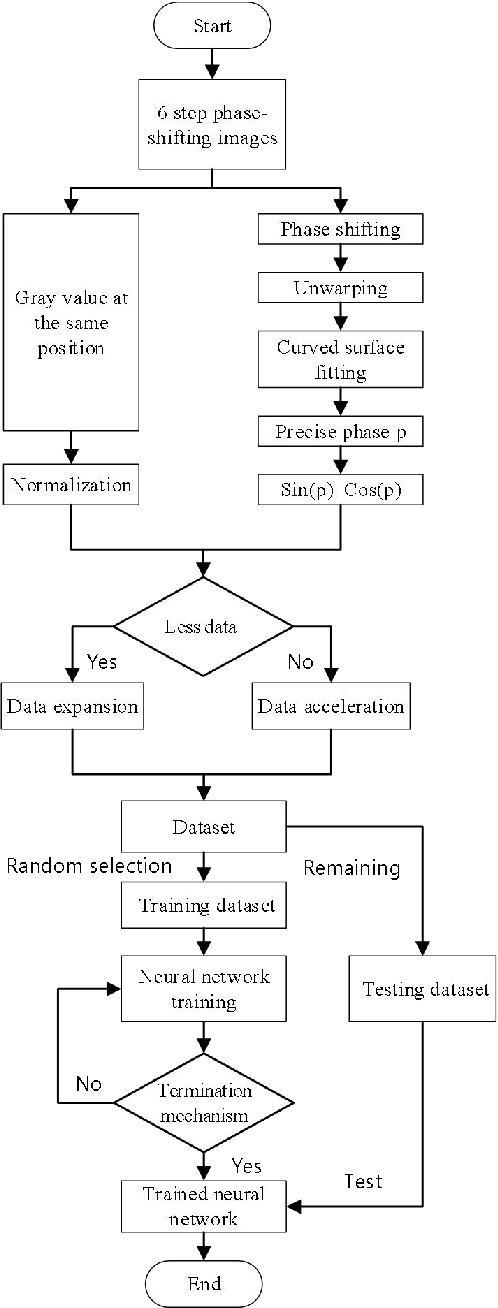
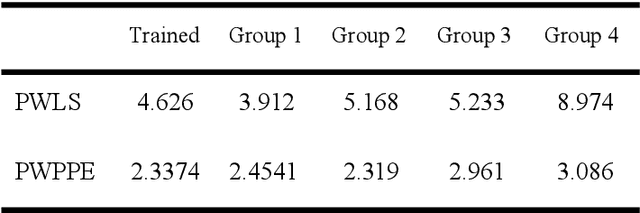

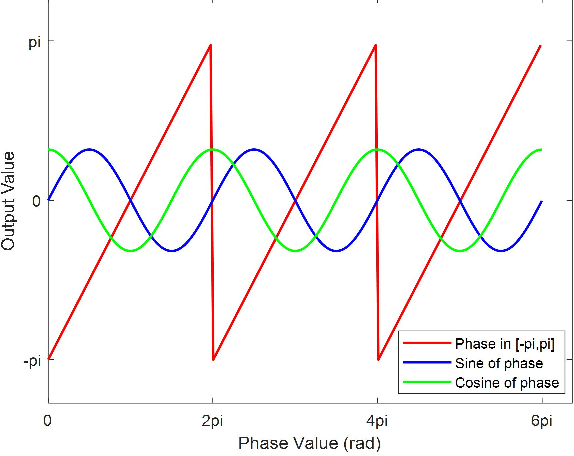
In fringe projection profilometry, the high-order harmonics information of non-sinusoidal fringes will lead to errors in the phase estimation. In order to solve this problem, a point-wise posterior phase estimation (PWPPE) method based on deep learning technique is proposed in this paper. The complex nonlinear mapping relationship between the multiple gray values and the sine / cosine value of the phase is constructed by using the feedforward neural network model. After the model training, it can estimate the phase values of each pixel location, and the accuracy is higher than the point-wise least-square (PWLS) method. To further verify the effectiveness of this method, a face mask is measured, the traditional PWLS method and the proposed PWPPE method are employed, respectively. The comparison results show that the traditional method is with periodic phase errors, while the proposed PWPPE method can effectively eliminate such phase errors caused by non-sinusoidal fringes.