 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Pseudo-labeled Data to Improve Direct Speech-to-Speech Translation
May 18, 2022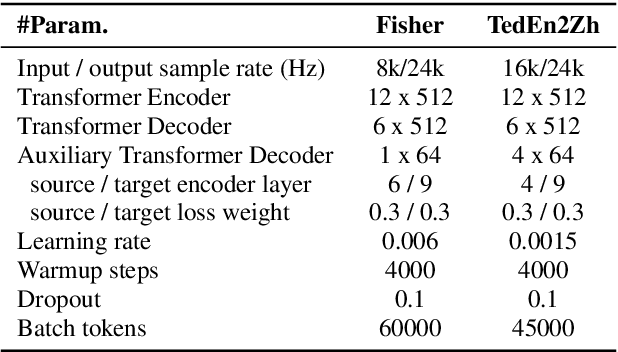
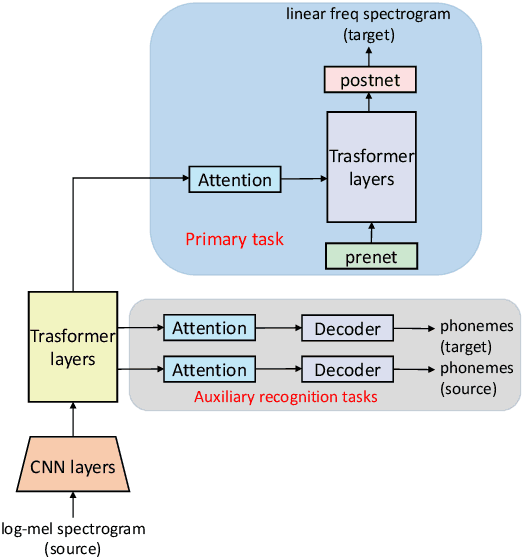
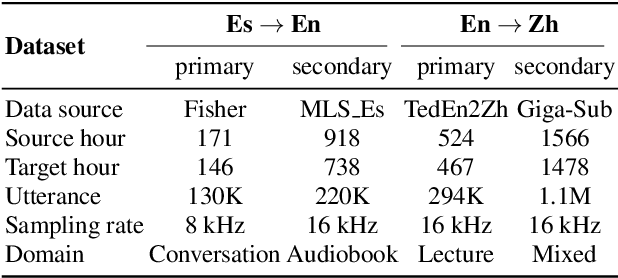
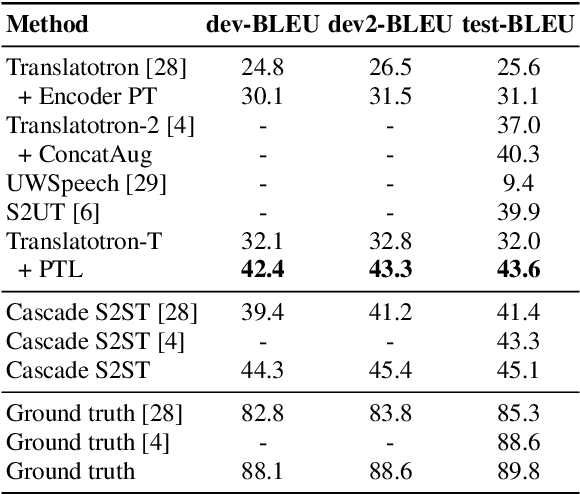
Direct Speech-to-speech translation (S2ST) has drawn more and more attention recently. The task is very challenging due to data scarcity and complex speech-to-speech mapping. In this paper, we report our recent achievements in S2ST. Firstly, we build a S2ST Transformer baseline which outperforms the original Translatotron. Secondly, we utilize the external data by pseudo-labeling and obtain a new state-of-the-art result on the Fisher English-to-Spanish test set. Indeed, we exploit the pseudo data with a combination of popular techniques which are not trivial when applied to S2ST. Moreover, we evaluate our approach on both syntactically similar (Spanish-English) and distant (English-Chinese) language pairs. Our implementation is available at https://github.com/fengpeng-yue/speech-to-speech-translation.
UniST: Unified End-to-end Model for Streaming and Non-streaming Speech Translation
Sep 15, 2021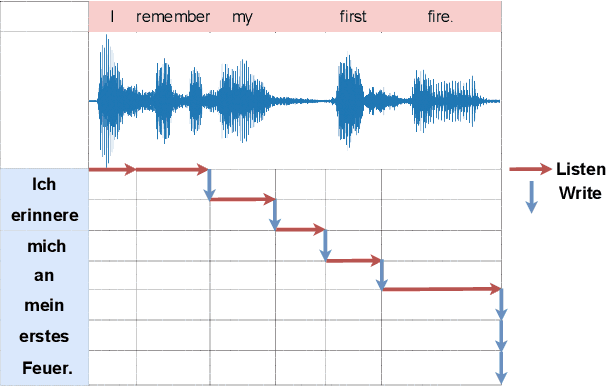


This paper presents a unified end-to-end frame-work for both streaming and non-streamingspeech translation. While the training recipes for non-streaming speech translation have been mature, the recipes for streaming speechtranslation are yet to be built. In this work, wefocus on developing a unified model (UniST) which supports streaming and non-streaming ST from the perspective of fundamental components, including training objective, attention mechanism and decoding policy. Experiments on the most popular speech-to-text translation benchmark dataset, MuST-C, show that UniST achieves significant improvement for non-streaming ST, and a better-learned trade-off for BLEU score and latency metrics for streaming ST, compared with end-to-end baselines and the cascaded models. We will make our codes and evaluation tools publicly available.
The Volctrans Neural Speech Translation System for IWSLT 2021
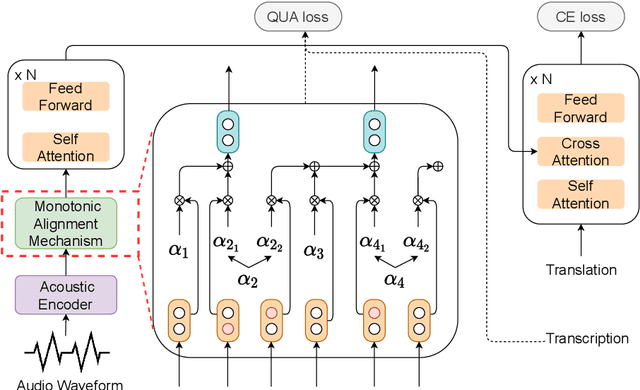
May 16, 2021
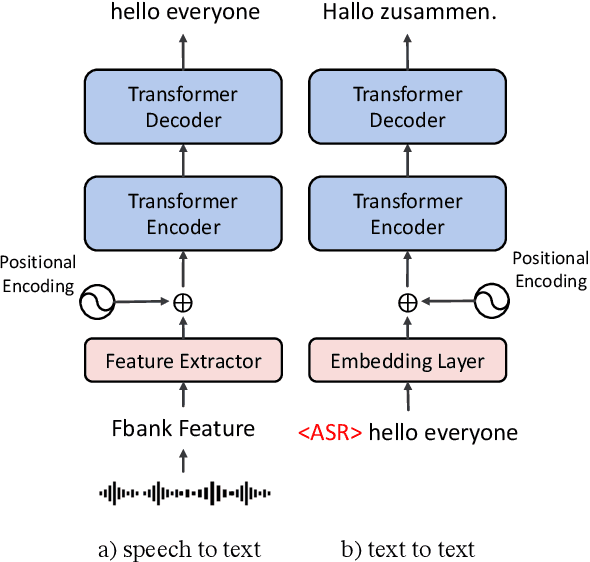
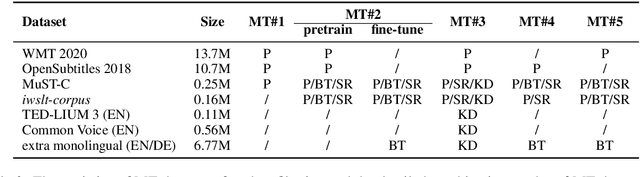
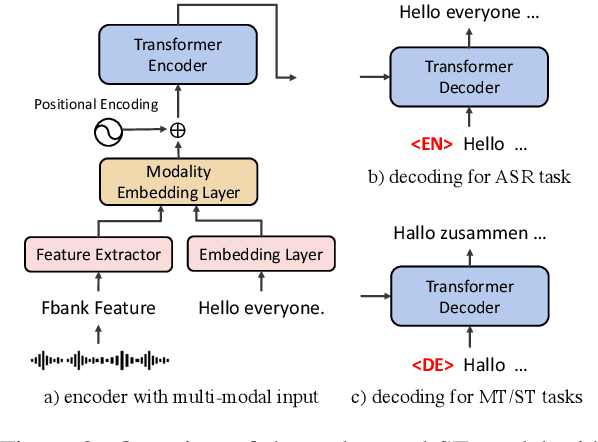
This paper describes the systems submitted to IWSLT 2021 by the Volctrans team. We participate in the offline speech translation and text-to-text simultaneous translation tracks. For offline speech translation, our best end-to-end model achieves 8.1 BLEU improvements over the benchmark on the MuST-C test set and is even approaching the results of a strong cascade solution. For text-to-text simultaneous translation, we explore the best practice to optimize the wait-k model. As a result, our final submitted systems exceed the benchmark at around 7 BLEU on the same latency regime. We will publish our code and model to facilitate both future research works and industrial applications.
SDST: Successive Decoding for Speech-to-text Translation
Sep 21, 2020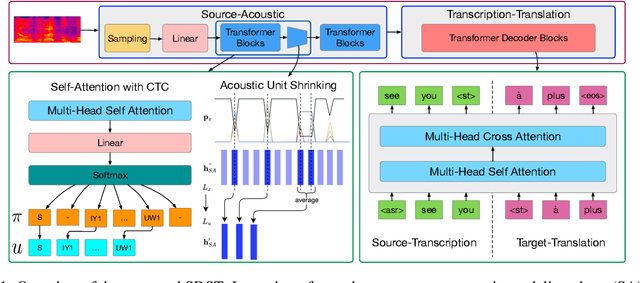

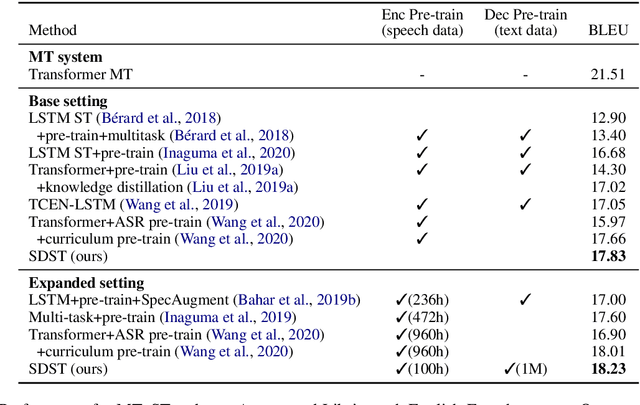
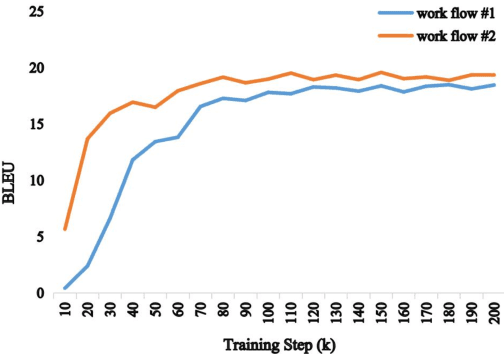
End-to-end speech-to-text translation (ST), which directly translates the source language speech to the target language text, has attracted intensive attention recently. However, the combination of speech recognition and machine translation in a single model poses a heavy burden on the direct cross-modal cross-lingual mapping. To reduce the learning difficulty, we propose SDST, an integral framework with \textbf{S}uccessive \textbf{D}ecoding for end-to-end \textbf{S}peech-to-text \textbf{T}ranslation task. This method is verified in two mainstream datasets. Experiments show that our proposed \method improves the previous state-of-the-art methods by big margins.
TED: Triple Supervision Decouples End-to-end Speech-to-text Translation
Sep 21, 2020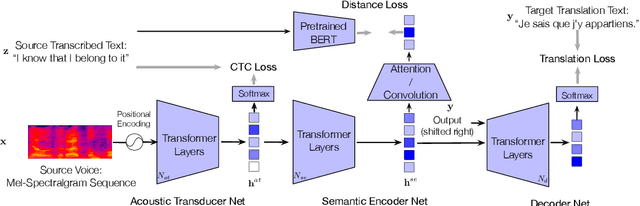
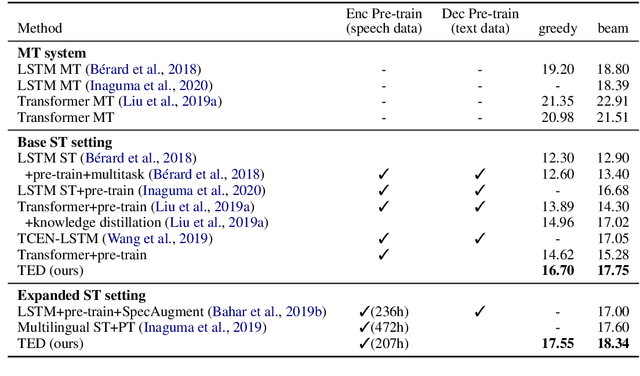
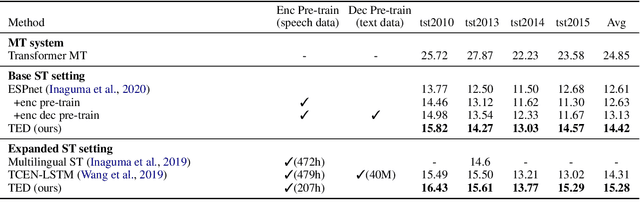
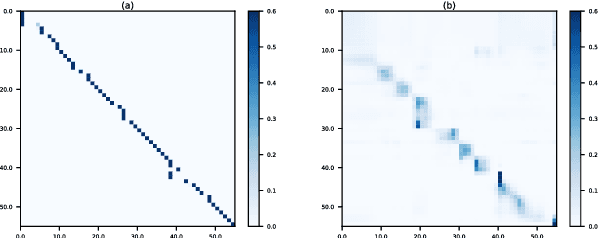
An end-to-end speech-to-text translation (ST) takes audio in a source language and outputs the text in a target language. Inspired by neuroscience, humans have perception systems and cognitive systems to process different information, we propose TED, \textbf{T}ransducer-\textbf{E}ncoder-\textbf{D}ecoder, a unified framework with triple supervision to decouple the end-to-end speech-to-text translation task. In addition to the target sentence translation loss, \method includes two auxiliary supervising signals to guide the acoustic transducer that extracts acoustic features from the input, and the semantic encoder to extract semantic features relevant to the source transcription text. Our method achieves state-of-the-art performance on both English-French and English-German speech translation benchmarks.
CLUE: A Chinese Language Understanding Evaluation Benchmark
Apr 14, 2020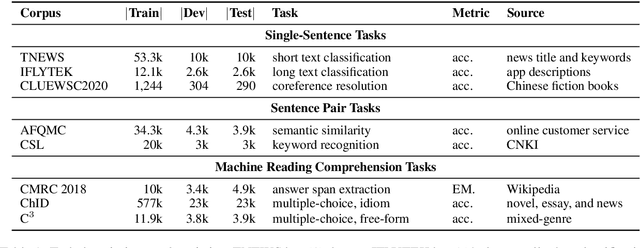
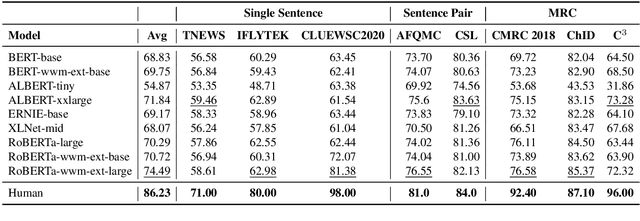
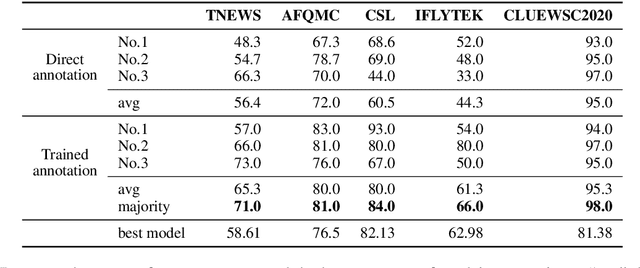
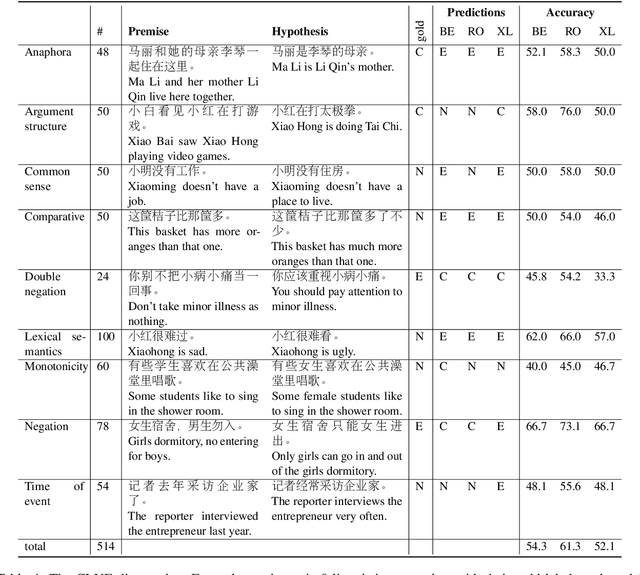
We introduce CLUE, a Chinese Language Understanding Evaluation benchmark. It contains eight different tasks, including single-sentence classification, sentence pair classification, and machine reading comprehension. We evaluate CLUE on a number of existing full-network pre-trained models for Chinese. We also include a small hand-crafted diagnostic test set designed to probe specific linguistic phenomena using different models, some of which are unique to Chinese. Along with CLUE, we release a large clean crawled raw text corpus that can be used for model pre-training. We release CLUE, baselines and pre-training dataset on Github.
CLUECorpus2020: A Large-scale Chinese Corpus for Pre-training Language Model
Mar 05, 2020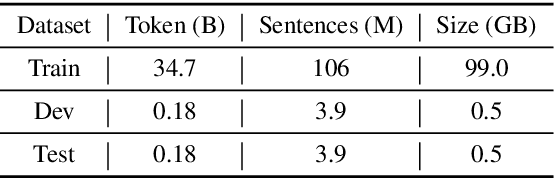
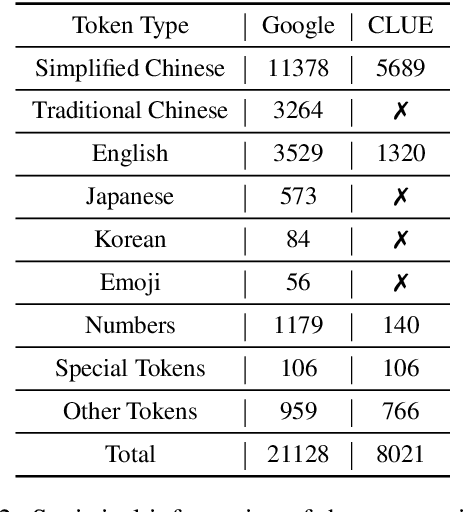
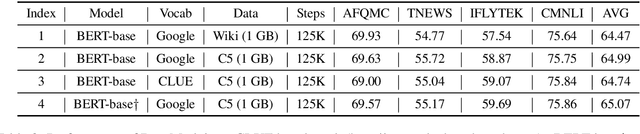

In this paper, we introduce the Chinese corpus from CLUE organization, CLUECorpus2020, a large-scale corpus that can be used directly for self-supervised learning such as pre-training of a language model, or language generation. It has 100G raw corpus with 35 billion Chinese characters, which is retrieved from Common Crawl. To better understand this corpus, we conduct language understanding experiments on both small and large scale, and results show that the models trained on this corpus can achieve excellent performance on Chinese. We release a new Chinese vocabulary with a size of 8K, which is only one-third of the vocabulary size used in Chinese Bert released by Google. It saves computational cost and memory while works as good as original vocabulary. We also release both large and tiny versions of the pre-trained model on this corpus. The former achieves the state-of-the-art result, and the latter retains most precision while accelerating training and prediction speed for eight times compared to Bert-base. To facilitate future work on self-supervised learning on Chinese, we release our dataset, new vocabulary, codes, and pre-trained models on Github.
CLUENER2020: Fine-grained Named Entity Recognition Dataset and Benchmark for Chinese
Jan 20, 2020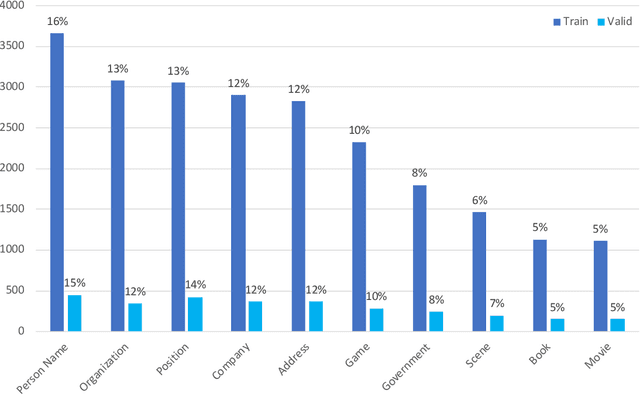

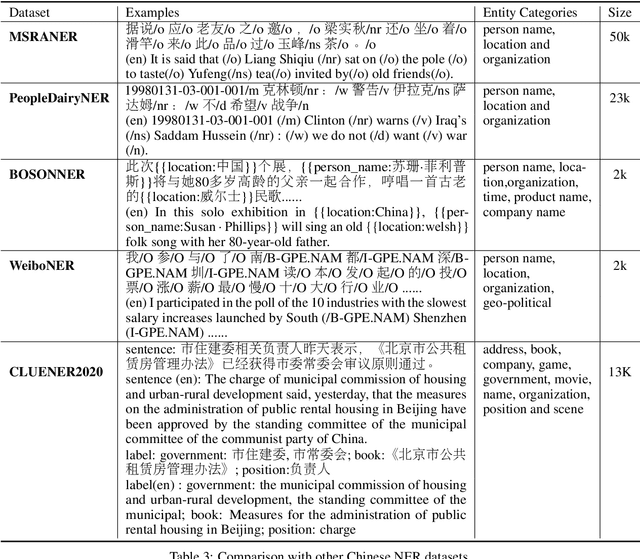
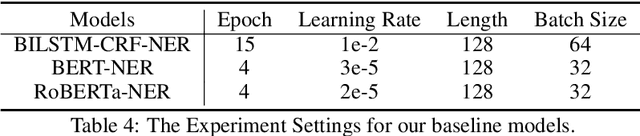
In this paper, we introduce the NER dataset from CLUE organization (CLUENER2020), a well-defined fine-grained dataset for named entity recognition in Chinese. CLUENER2020 contains 10 categories. Apart from common labels like person, organization, and location, it contains more diverse categories. It is more challenging than current other Chinese NER datasets and could better reflect real-world applications. For comparison, we implement several state-of-the-art baselines as sequence labeling tasks and report human performance, as well as its analysis. To facilitate future work on fine-grained NER for Chinese, we release our dataset, baselines, and leader-board.