 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOC-Bench: A Temporal Object Consistency Benchmark for Video Large Language Models
May 11, 2026Video large language models (Video-LLMs) have achieved remarkable progress in general video understanding, yet their ability to maintain temporal object consistency remains insufficiently explored. Existing benchmarks primarily focus on event recognition, action understanding, or coarse temporal reasoning, but rarely evaluate whether a model can consistently preserve the identity, state, and temporal continuity of the same object across occlusion, disappearance, reappearance, state transitions, and cross-object interactions. As a result, current evaluations may overestimate temporal reasoning ability while overlooking failures in object-centric temporal coherence. To address this issue, we introduce TOC-Bench, a diagnostic benchmark specifically designed to evaluate temporal object consistency in Video-LLMs. TOC-Bench is explicitly object-track grounded, where each queried subject is associated with a per frame object trajectory and structured temporal event timeline. To ensure that benchmark items depend on temporally ordered visual evidence rather than language priors, single-frame shortcuts, or unordered frame cues, we propose a three-layer temporal-necessity filtering protocol that removes 60.7% of candidate QA pairs and retains 17,900 temporally dependent items spanning 10 diagnostic dimensions. From this filtered pool, we further construct a human-verified benchmark containing 2,323 high-quality QA pairs over 1,951 videos. Experiments on representative Video-LLMs show that temporal object consistency remains a major unsolved challenge. Current models exhibit substantial weaknesses in event counting, event ordering, identity-sensitive reasoning, and hallucination-aware verification, despite strong performance on general video understanding benchmarks.
Infrastructure-Centric World Models: Bridging Temporal Depth and Spatial Breadth for Roadside Perception
Apr 19, 2026World models, generative AI systems that simulate how environments evolve, are transforming autonomous driving, yet all existing approaches adopt an ego-vehicle perspective, leaving the infrastructure viewpoint unexplored. We argue that infrastructure-centric world models offer a fundamentally complementary capability: the bird's-eye, multi-sensor, persistent viewpoint that roadside systems uniquely possess. Central to our thesis is a spatio-temporal complementarity: fixed roadside sensors excel at temporal depth, accumulating long-term behavioral distributions including rare safety-critical events, while vehicle-borne sensors excel at spatial breadth, sampling diverse scenes across large road networks. This paper presents a vision for Infrastructure-centric World Models (I-WM) in three phases: (I) generative scene understanding with quality-aware uncertainty propagation, (II) physics-informed predictive dynamics with multi-agent counterfactual reasoning, and (III) collaborative world models for V2X communication via latent space alignment. We propose a dual-layer architecture, annotation-free perception as a multi-modal data engine feeding end-to-end generative world models, with a phased sensor strategy from LiDAR through 4D radar and signal phase data to event cameras. We establish a taxonomy of driving world model paradigms, position I-WM relative to LeCun's JEPA, Li Fei-Fei's spatial intelligence, and VLA architectures, and introduce Infrastructure VLA (I-VLA) as a novel unification of roadside perception, language commands, and traffic control actions. Our vision builds upon existing multi-LiDAR pipelines and identifies open-source foundations for each phase, providing a path toward infrastructure that understands and anticipates traffic.
Mosaic: Data-Free Knowledge Distillation via Mixture-of-Experts for Heterogeneous Distributed Environments
May 26, 2025



Federated Learning (FL) is a decentralized machine learning paradigm that enables clients to collaboratively train models while preserving data privacy. However, the coexistence of model and data heterogeneity gives rise to inconsistent representations and divergent optimization dynamics across clients, ultimately hindering robust global performance. To transcend these challenges, we propose Mosaic, a novel data-free knowledge distillation framework tailored for heterogeneous distributed environments. Mosaic first trains local generative models to approximate each client's personalized distribution, enabling synthetic data generation that safeguards privacy through strict separation from real data. Subsequently, Mosaic forms a Mixture-of-Experts (MoE) from client models based on their specialized knowledge, and distills it into a global model using the generated data. To further enhance the MoE architecture, Mosaic integrates expert predictions via a lightweight meta model trained on a few representative prototypes. Extensive experiments on standard image classification benchmarks demonstrate that Mosaic consistently outperforms state-of-the-art approaches under both model and data heterogeneity. The source code has been published at https://github.com/Wings-Of-Disaster/Mosaic.
Adaptive Locomotion on Mud through Proprioceptive Sensing of Substrate Properties
Apr 28, 2025Muddy terrains present significant challenges for terrestrial robots, as subtle changes in composition and water content can lead to large variations in substrate strength and force responses, causing the robot to slip or get stuck. This paper presents a method to estimate mud properties using proprioceptive sensing, enabling a flipper-driven robot to adapt its locomotion through muddy substrates of varying strength. First, we characterize mud reaction forces through actuator current and position signals from a statically mounted robotic flipper. We use the measured force to determine key coefficients that characterize intrinsic mud properties. The proprioceptively estimated coefficients match closely with measurements from a lab-grade load cell, validating the effectiveness of the proposed method. Next, we extend the method to a locomoting robot to estimate mud properties online as it crawls across different mud mixtures. Experimental data reveal that mud reaction forces depend sensitively on robot motion, requiring joint analysis of robot movement with proprioceptive force to determine mud properties correctly. Lastly, we deploy this method in a flipper-driven robot moving across muddy substrates of varying strengths, and demonstrate that the proposed method allows the robot to use the estimated mud properties to adapt its locomotion strategy, and successfully avoid locomotion failures. Our findings highlight the potential of proprioception-based terrain sensing to enhance robot mobility in complex, deformable natural environments, paving the way for more robust field exploration capabilities.
HM-RAG: Hierarchical Multi-Agent Multimodal Retrieval Augmented Generation
Apr 13, 2025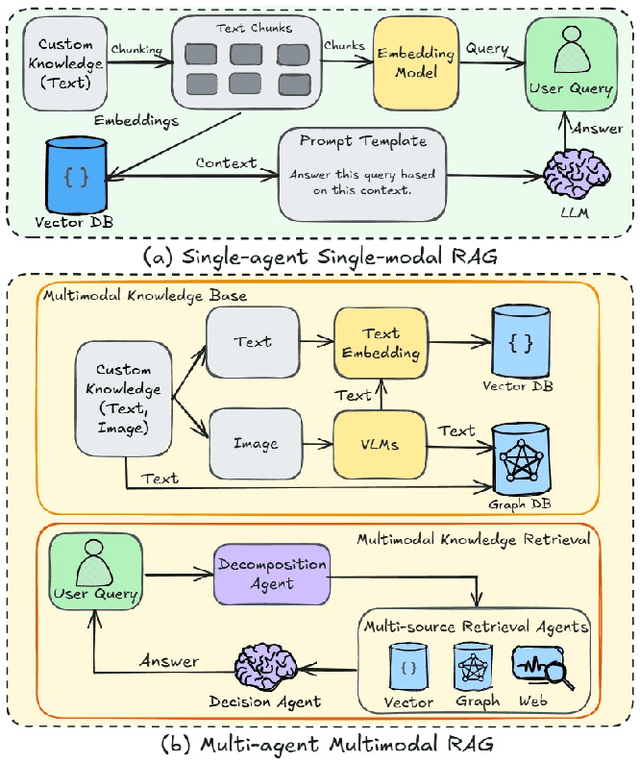
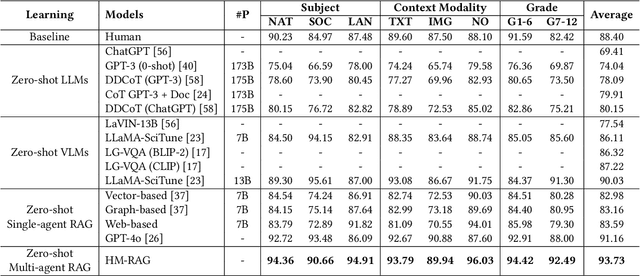
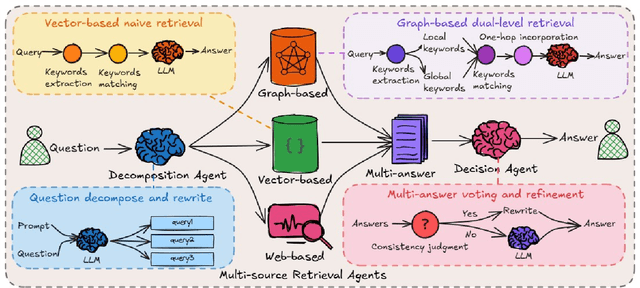
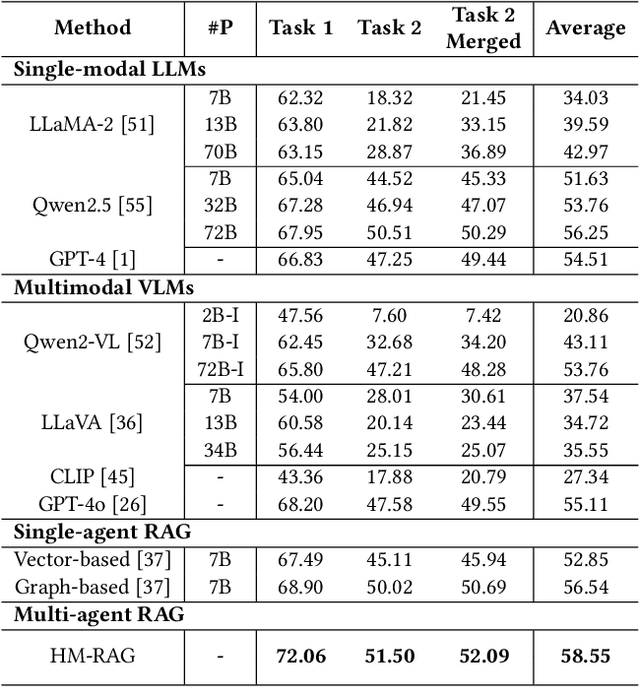
While Retrieval-Augmented Generation (RAG) augments Large Language Models (LLMs) with external knowledge, conventional single-agent RAG remains fundamentally limited in resolving complex queries demanding coordinated reasoning across heterogeneous data ecosystems. We present HM-RAG, a novel Hierarchical Multi-agent Multimodal RAG framework that pioneers collaborative intelligence for dynamic knowledge synthesis across structured, unstructured, and graph-based data. The framework is composed of three-tiered architecture with specialized agents: a Decomposition Agent that dissects complex queries into contextually coherent sub-tasks via semantic-aware query rewriting and schema-guided context augmentation; Multi-source Retrieval Agents that carry out parallel, modality-specific retrieval using plug-and-play modules designed for vector, graph, and web-based databases; and a Decision Agent that uses consistency voting to integrate multi-source answers and resolve discrepancies in retrieval results through Expert Model Refinement. This architecture attains comprehensive query understanding by combining textual, graph-relational, and web-derived evidence, resulting in a remarkable 12.95% improvement in answer accuracy and a 3.56% boost in question classification accuracy over baseline RAG systems on the ScienceQA and CrisisMMD benchmarks. Notably, HM-RAG establishes state-of-the-art results in zero-shot settings on both datasets. Its modular architecture ensures seamless integration of new data modalities while maintaining strict data governance, marking a significant advancement in addressing the critical challenges of multimodal reasoning and knowledge synthesis in RAG systems. Code is available at https://github.com/ocean-luna/HMRAG.
Aligning Vision to Language: Text-Free Multimodal Knowledge Graph Construction for Enhanced LLMs Reasoning
Mar 17, 2025Multimodal reasoning in Large Language Models (LLMs) struggles with incomplete knowledge and hallucination artifacts, challenges that textual Knowledge Graphs (KGs) only partially mitigate due to their modality isolation. While Multimodal Knowledge Graphs (MMKGs) promise enhanced cross-modal understanding, their practical construction is impeded by semantic narrowness of manual text annotations and inherent noise in visual-semantic entity linkages. In this paper, we propose Vision-align-to-Language integrated Knowledge Graph (VaLiK), a novel approach for constructing MMKGs that enhances LLMs reasoning through cross-modal information supplementation. Specifically, we cascade pre-trained Vision-Language Models (VLMs) to align image features with text, transforming them into descriptions that encapsulate image-specific information. Furthermore, we developed a cross-modal similarity verification mechanism to quantify semantic consistency, effectively filtering out noise introduced during feature alignment. Even without manually annotated image captions, the refined descriptions alone suffice to construct the MMKG. Compared to conventional MMKGs construction paradigms, our approach achieves substantial storage efficiency gains while maintaining direct entity-to-image linkage capability. Experimental results on multimodal reasoning tasks demonstrate that LLMs augmented with VaLiK outperform previous state-of-the-art models. Our code is published at https://github.com/Wings-Of-Disaster/VaLiK.