 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Feature Enhancing and Fusion Framework for Strain Gauge Time Series Classification
Nov 07, 2025



Strain Gauge Status (SGS) recognition is crucial in the field of intelligent manufacturing based on the Internet of Things, as accurate identification helps timely detection of failed mechanical components, avoiding accidents. The loading and unloading sequences generated by strain gauges can be identified through time series classification (TSC) algorithms. Recently, deep learning models, e.g., convolutional neural networks (CNNs) have shown remarkable success in the TSC task, as they can extract discriminative local features from the subsequences to identify the time series. However, we observe that only the local features may not be sufficient for expressing the time series, especially when the local sub-sequences between different time series are very similar, e.g., SGS data of aircraft wings in static strength experiments. Nevertheless, CNNs suffer from the limitation in extracting global features due to the nature of convolution operations. For extracting global features to more comprehensively represent the SGS time series, we propose two insights: (i) Constructing global features through feature engineering. (ii) Learning high-order relationships between local features to capture global features. To realize and utilize them, we propose a hypergraph-based global feature learning and fusion framework, which learns and fuses global features for semantic consistency to enhance the representation of SGS time series, thereby improving recognition accuracy. Our method designs are validated on industrial SGS and public UCR datasets, showing better generalization for unseen data in SGS recognition.
Deep Learning in Dental Image Analysis: A Systematic Review of Datasets, Methodologies, and Emerging Challenges
Oct 23, 2025



Efficient analysis and processing of dental images are crucial for dentists to achieve accurate diagnosis and optimal treatment planning. However, dental imaging inherently poses several challenges, such as low contrast, metallic artifacts, and variations in projection angles. Combined with the subjectivity arising from differences in clinicians' expertise, manual interpretation often proves time-consuming and prone to inconsistency. Artificial intelligence (AI)-based automated dental image analysis (DIA) offers a promising solution to these issues and has become an integral part of computer-aided dental diagnosis and treatment. Among various AI technologies, deep learning (DL) stands out as the most widely applied and influential approach due to its superior feature extraction and representation capabilities. To comprehensively summarize recent progress in this field, we focus on the two fundamental aspects of DL research-datasets and models. In this paper, we systematically review 260 studies on DL applications in DIA, including 49 papers on publicly available dental datasets and 211 papers on DL-based algorithms. We first introduce the basic concepts of dental imaging and summarize the characteristics and acquisition methods of existing datasets. Then, we present the foundational techniques of DL and categorize relevant models and algorithms according to different DIA tasks, analyzing their network architectures, optimization strategies, training methods, and performance. Furthermore, we summarize commonly used training and evaluation metrics in the DIA domain. Finally, we discuss the current challenges of existing research and outline potential future directions. We hope that this work provides a valuable and systematic reference for researchers in this field. All supplementary materials and detailed comparison tables will be made publicly available on GitHub.
Feature Space Adaptation for Robust Model Fine-Tuning
Oct 22, 2025
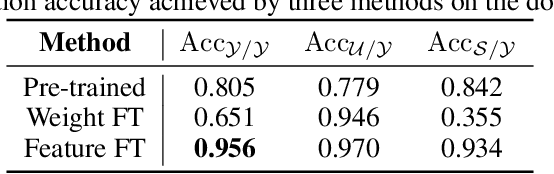

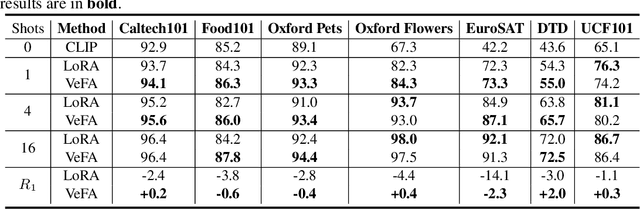
Catastrophic forgetting is a common issue in model fine-tuning, especially when the downstream domain contains limited labeled data or differs greatly from the pre-training distribution. Existing parameter-efficient fine-tuning methods operate in the weight space by modifying or augmenting the pre-trained model's parameters, which can yield models overly specialized to the available downstream data. To mitigate the risk of overwriting pre-trained knowledge and enhance robustness, we propose to fine-tune the pre-trained model in the feature space. Two new fine-tuning methods are proposed: LoRFA (Low-Rank Feature Adaptation) and VeFA (Vector-Based Feature Adaptation). Feature space adaptation is inspired by the idea of effect equivalence modeling (EEM) of downstream lurking variables causing distribution shifts, which posits that unobserved factors can be represented as the total equivalent amount on observed features. By compensating for the effects of downstream lurking variables via a lightweight feature-level transformation, the pre-trained representations can be preserved, which improves model generalization under distribution shift. We evaluate LoRFA and VeFA versus LoRA on image classification, NLU, and NLG, covering both standard fine-tuning metrics and robustness. Feature space adaptation achieves comparable fine-tuning results and consistently stronger robustness.
ToolExpander: Extending the Frontiers of Tool-Using Reinforcement Learning to Weak LLMs
Oct 09, 2025Training Large Language Models (LLMs) with Group Relative Policy Optimization (GRPO) encounters a significant challenge: models often fail to produce accurate responses, particularly in small-scale architectures. This limitation not only diminishes performance improvements and undermines the potential of GRPO but also frequently leads to mid-training collapse, adversely affecting stability and final efficacy. To address these issues, we propose ToolExpander, a novel framework that advances tool-oriented reinforcement learning for resource-constrained LLMs through two key innovations:(1) Dynamic Multi-Round Hard Sampling, which dynamically substitutes challenging samples(those without correct outputs over 10 rollouts) with high-quality few-shot demonstrations during training, coupled with an exponential learning rate decay strategy to mitigate oscillations;(2) Self-Exemplifying Thinking, an enhanced GRPO framework that eliminates KL divergence and incorporates adjusted clipping coefficients, encouraging models to autonomously generate and analyze few-shot examples via a minimal additional reward (0.01).Experimental results demonstrate that ToolExpander significantly enhances tool-using capabilities in LLMs, especially in weaker small-scale models, improving both training stability and overall performance.
MEMTRACK: Evaluating Long-Term Memory and State Tracking in Multi-Platform Dynamic Agent Environments
Oct 01, 2025



Recent works on context and memory benchmarking have primarily focused on conversational instances but the need for evaluating memory in dynamic enterprise environments is crucial for its effective application. We introduce MEMTRACK, a benchmark designed to evaluate long-term memory and state tracking in multi-platform agent environments. MEMTRACK models realistic organizational workflows by integrating asynchronous events across multiple communication and productivity platforms such as Slack, Linear and Git. Each benchmark instance provides a chronologically platform-interleaved timeline, with noisy, conflicting, cross-referring information as well as potential codebase/file-system comprehension and exploration. Consequently, our benchmark tests memory capabilities such as acquistion, selection and conflict resolution. We curate the MEMTRACK dataset through both manual expert driven design and scalable agent based synthesis, generating ecologically valid scenarios grounded in real world software development processes. We introduce pertinent metrics for Correctness, Efficiency, and Redundancy that capture the effectiveness of memory mechanisms beyond simple QA performance. Experiments across SoTA LLMs and memory backends reveal challenges in utilizing memory across long horizons, handling cross-platform dependencies, and resolving contradictions. Notably, the best performing GPT-5 model only achieves a 60\% Correctness score on MEMTRACK. This work provides an extensible framework for advancing evaluation research for memory-augmented agents, beyond existing focus on conversational setups, and sets the stage for multi-agent, multi-platform memory benchmarking in complex organizational settings
Mem4D: Decoupling Static and Dynamic Memory for Dynamic Scene Reconstruction
Aug 12, 2025Reconstructing dense geometry for dynamic scenes from a monocular video is a critical yet challenging task. Recent memory-based methods enable efficient online reconstruction, but they fundamentally suffer from a Memory Demand Dilemma: The memory representation faces an inherent conflict between the long-term stability required for static structures and the rapid, high-fidelity detail retention needed for dynamic motion. This conflict forces existing methods into a compromise, leading to either geometric drift in static structures or blurred, inaccurate reconstructions of dynamic objects. To address this dilemma, we propose Mem4D, a novel framework that decouples the modeling of static geometry and dynamic motion. Guided by this insight, we design a dual-memory architecture: 1) The Transient Dynamics Memory (TDM) focuses on capturing high-frequency motion details from recent frames, enabling accurate and fine-grained modeling of dynamic content; 2) The Persistent Structure Memory (PSM) compresses and preserves long-term spatial information, ensuring global consistency and drift-free reconstruction for static elements. By alternating queries to these specialized memories, Mem4D simultaneously maintains static geometry with global consistency and reconstructs dynamic elements with high fidelity. Experiments on challenging benchmarks demonstrate that our method achieves state-of-the-art or competitive performance while maintaining high efficiency. Codes will be publicly available.
Trajectory-adaptive Beam Shaping: Towards Beam-Management-Free Near-field Communications
Aug 12, 2025The quest for higher wireless carrier frequencies spanning the millimeter-wave (mmWave) and Terahertz (THz) bands heralds substantial enhancements in data throughput and spectral efficiency for next-generation wireless networks. However, these gains come at the cost of severe path loss and a heightened risk of beam misalignment due to user mobility, especially pronounced in near-field communication. Traditional solutions rely on extremely directional beamforming and frequent beam updates via beam management, but such techniques impose formidable computational and signaling overhead. In response, we propose a novel approach termed trajectory-adaptive beam shaping (TABS) that eliminates the need for real-time beam management by shaping the electromagnetic wavefront to follow the user's predefined trajectory. Drawing inspiration from self-accelerating beams in optics, TABS concentrates energy along pre-defined curved paths corresponding to the user's motion without requiring real-time beam reconfiguration. We further introduce a dedicated quantitative metric to characterize performance under the TABS framework. Comprehensive simulations substantiate the superiority of TABS in terms of link performance, overhead reduction, and implementation complexity.
UGOD: Uncertainty-Guided Differentiable Opacity and Soft Dropout for Enhanced Sparse-View 3DGS
Aug 07, 20253D Gaussian Splatting (3DGS) has become a competitive approach for novel view synthesis (NVS) due to its advanced rendering efficiency through 3D Gaussian projection and blending. However, Gaussians are treated equally weighted for rendering in most 3DGS methods, making them prone to overfitting, which is particularly the case in sparse-view scenarios. To address this, we investigate how adaptive weighting of Gaussians affects rendering quality, which is characterised by learned uncertainties proposed. This learned uncertainty serves two key purposes: first, it guides the differentiable update of Gaussian opacity while preserving the 3DGS pipeline integrity; second, the uncertainty undergoes soft differentiable dropout regularisation, which strategically transforms the original uncertainty into continuous drop probabilities that govern the final Gaussian projection and blending process for rendering. Extensive experimental results over widely adopted datasets demonstrate that our method outperforms rivals in sparse-view 3D synthesis, achieving higher quality reconstruction with fewer Gaussians in most datasets compared to existing sparse-view approaches, e.g., compared to DropGaussian, our method achieves 3.27\% PSNR improvements on the MipNeRF 360 dataset.
Unlearning of Knowledge Graph Embedding via Preference Optimization
Jul 28, 2025



Existing knowledge graphs (KGs) inevitably contain outdated or erroneous knowledge that needs to be removed from knowledge graph embedding (KGE) models. To address this challenge, knowledge unlearning can be applied to eliminate specific information while preserving the integrity of the remaining knowledge in KGs. Existing unlearning methods can generally be categorized into exact unlearning and approximate unlearning. However, exact unlearning requires high training costs while approximate unlearning faces two issues when applied to KGs due to the inherent connectivity of triples: (1) It fails to fully remove targeted information, as forgetting triples can still be inferred from remaining ones. (2) It focuses on local data for specific removal, which weakens the remaining knowledge in the forgetting boundary. To address these issues, we propose GraphDPO, a novel approximate unlearning framework based on direct preference optimization (DPO). Firstly, to effectively remove forgetting triples, we reframe unlearning as a preference optimization problem, where the model is trained by DPO to prefer reconstructed alternatives over the original forgetting triples. This formulation penalizes reliance on forgettable knowledge, mitigating incomplete forgetting caused by KG connectivity. Moreover, we introduce an out-boundary sampling strategy to construct preference pairs with minimal semantic overlap, weakening the connection between forgetting and retained knowledge. Secondly, to preserve boundary knowledge, we introduce a boundary recall mechanism that replays and distills relevant information both within and across time steps. We construct eight unlearning datasets across four popular KGs with varying unlearning rates. Experiments show that GraphDPO outperforms state-of-the-art baselines by up to 10.1% in MRR_Avg and 14.0% in MRR_F1.
Implicit Counterfactual Learning for Audio-Visual Segmentation
Jul 28, 2025



Audio-visual segmentation (AVS) aims to segment objects in videos based on audio cues. Existing AVS methods are primarily designed to enhance interaction efficiency but pay limited attention to modality representation discrepancies and imbalances. To overcome this, we propose the implicit counterfactual framework (ICF) to achieve unbiased cross-modal understanding. Due to the lack of semantics, heterogeneous representations may lead to erroneous matches, especially in complex scenes with ambiguous visual content or interference from multiple audio sources. We introduce the multi-granularity implicit text (MIT) involving video-, segment- and frame-level as the bridge to establish the modality-shared space, reducing modality gaps and providing prior guidance. Visual content carries more information and typically dominates, thereby marginalizing audio features in the decision-making. To mitigate knowledge preference, we propose the semantic counterfactual (SC) to learn orthogonal representations in the latent space, generating diverse counterfactual samples, thus avoiding biases introduced by complex functional designs and explicit modifications of text structures or attributes. We further formulate the collaborative distribution-aware contrastive learning (CDCL), incorporating factual-counterfactual and inter-modality contrasts to align representations, promoting cohesion and decoupling. Extensive experiments on three public datasets validate that the proposed method achieves state-of-the-art performance.