 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Space Adaptation for Robust Model Fine-Tuning
Paper and Code
Oct 22, 2025
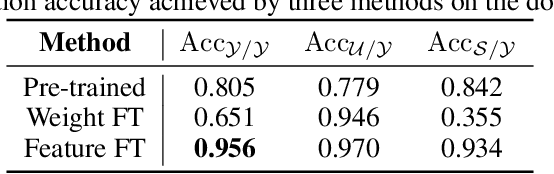

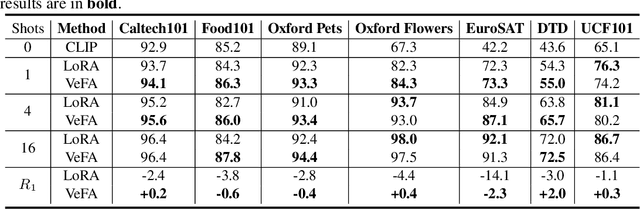
Catastrophic forgetting is a common issue in model fine-tuning, especially when the downstream domain contains limited labeled data or differs greatly from the pre-training distribution. Existing parameter-efficient fine-tuning methods operate in the weight space by modifying or augmenting the pre-trained model's parameters, which can yield models overly specialized to the available downstream data. To mitigate the risk of overwriting pre-trained knowledge and enhance robustness, we propose to fine-tune the pre-trained model in the feature space. Two new fine-tuning methods are proposed: LoRFA (Low-Rank Feature Adaptation) and VeFA (Vector-Based Feature Adaptation). Feature space adaptation is inspired by the idea of effect equivalence modeling (EEM) of downstream lurking variables causing distribution shifts, which posits that unobserved factors can be represented as the total equivalent amount on observed features. By compensating for the effects of downstream lurking variables via a lightweight feature-level transformation, the pre-trained representations can be preserved, which improves model generalization under distribution shift. We evaluate LoRFA and VeFA versus LoRA on image classification, NLU, and NLG, covering both standard fine-tuning metrics and robustness. Feature space adaptation achieves comparable fine-tuning results and consistently stronger robustness.