 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMIX: Improving Importance Weighting for Subpopulation Shift via Uncertainty-Aware Mixup
Oct 10, 2022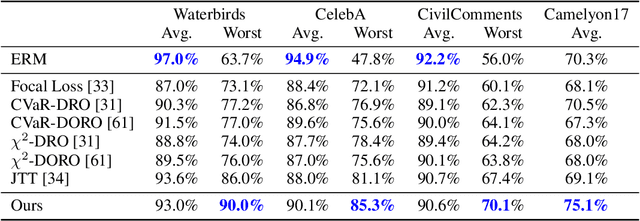
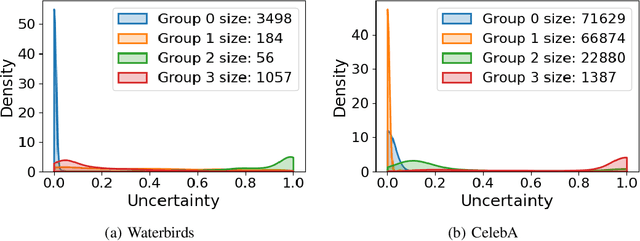
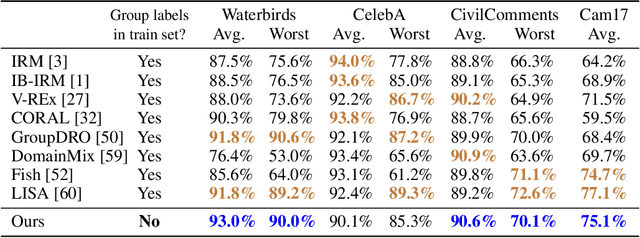
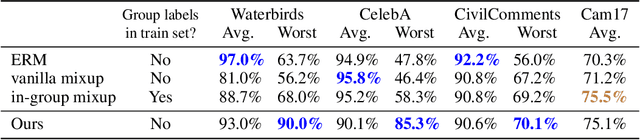
Subpopulation shift widely exists in many real-world machine learning applications, referring to the training and test distributions containing the same subpopulation groups but varying in subpopulation frequencies. Importance reweighting is a normal way to handle the subpopulation shift issue by imposing constant or adaptive sampling weights on each sample in the training dataset. However, some recent studies have recognized that most of these approaches fail to improve the performance over empirical risk minimization especially when applied to over-parameterized neural networks. In this work, we propose a simple yet practical framework, called uncertainty-aware mixup (UMIX), to mitigate the overfitting issue in over-parameterized models by reweighting the ''mixed'' samples according to the sample uncertainty. The training-trajectories-based uncertainty estimation is equipped in the proposed UMIX for each sample to flexibly characterize the subpopulation distribution. We also provide insightful theoretical analysis to verify that UMIX achieves better generalization bounds over prior works. Further, we conduct extensive empirical studies across a wide range of tasks to validate the effectiveness of our method both qualitatively and quantitatively. Code is available at https://github.com/TencentAILabHealthcare/UMIX.
Metro: Memory-Enhanced Transformer for Retrosynthetic Planning via Reaction Tree
Sep 30, 2022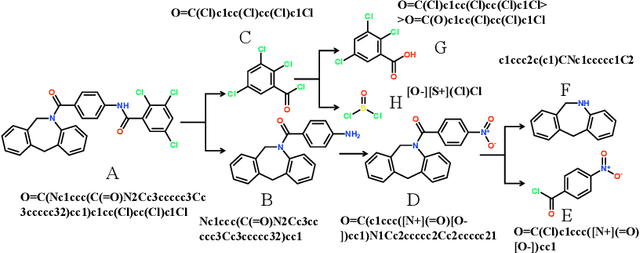
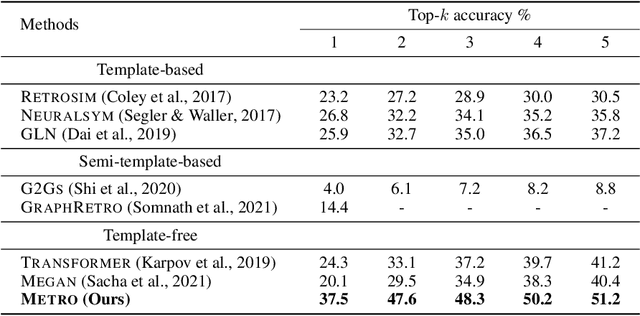
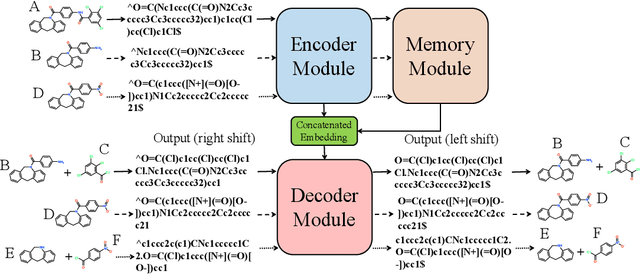

Retrosynthetic planning plays a critical role in drug discovery and organic chemistry. Starting from a target molecule as the root node, it aims to find a complete reaction tree subject to the constraint that all leaf nodes belong to a set of starting materials. The multi-step reactions are crucial because they determine the flow chart in the production of the Organic Chemical Industry. However, existing datasets lack curation of tree-structured multi-step reactions, and fail to provide such reaction trees, limiting models' understanding of organic molecule transformations. In this work, we first develop a benchmark curated for the retrosynthetic planning task, which consists of 124,869 reaction trees retrieved from the public USPTO-full dataset. On top of that, we propose Metro: Memory-Enhanced Transformer for RetrOsynthetic planning. Specifically, the dependency among molecules in the reaction tree is captured as context information for multi-step retrosynthesis predictions through transformers with a memory module. Extensive experiments show that Metro dramatically outperforms existing single-step retrosynthesis models by at least 10.7% in top-1 accuracy. The experiments demonstrate the superiority of exploiting context information in the retrosynthetic planning task. Moreover, the proposed model can be directly used for synthetic accessibility analysis, as it is trained on reaction trees with the shortest depths. Our work is the first step towards a brand new formulation for retrosynthetic planning in the aspects of data construction, model design, and evaluation. Code is available at https://github.com/SongtaoLiu0823/metro.
MARS: A Motif-based Autoregressive Model for Retrosynthesis Prediction
Sep 27, 2022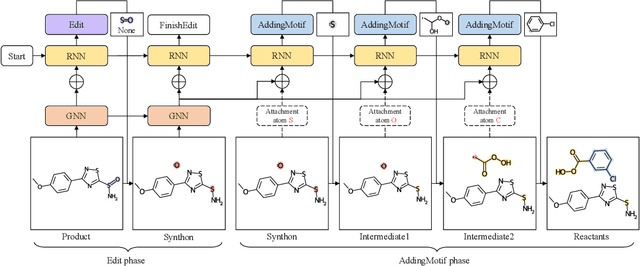
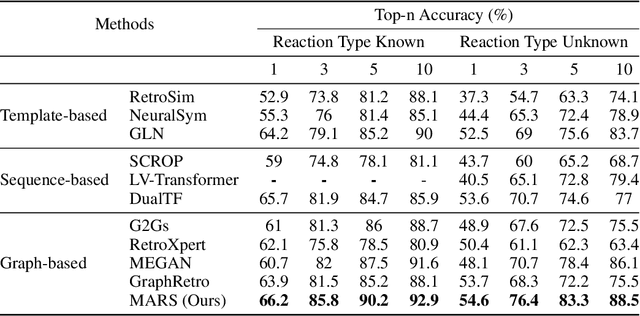
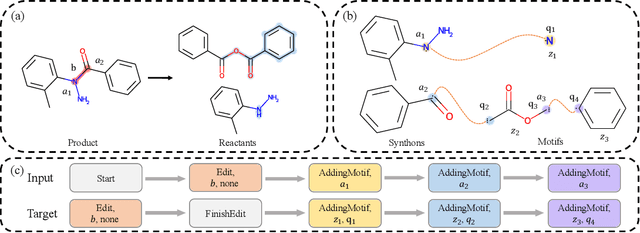
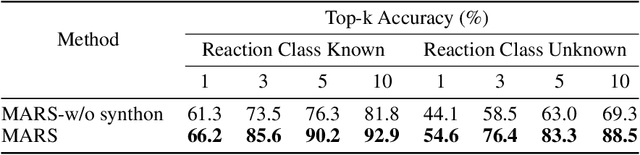
Retrosynthesis is a major task for drug discovery. It is formulated as a graph-generating problem by many existing approaches. Specifically, these methods firstly identify the reaction center, and break target molecule accordingly to generate synthons. Reactants are generated by either adding atoms sequentially to synthon graphs or directly adding proper leaving groups. However, both two strategies suffer since adding atoms results in a long prediction sequence which increases generation difficulty, while adding leaving groups can only consider the ones in the training set which results in poor generalization. In this paper, we propose a novel end-to-end graph generation model for retrosynthesis prediction, which sequentially identifies the reaction center, generates the synthons, and adds motifs to the synthons to generate reactants. Since chemically meaningful motifs are bigger than atoms and smaller than leaving groups, our method enjoys lower prediction complexity than adding atoms and better generalization than adding leaving groups. Experiments on a benchmark dataset show that the proposed model significantly outperforms previous state-of-the-art algorithms.
ImDrug: A Benchmark for Deep Imbalanced Learning in AI-aided Drug Discovery
Sep 16, 2022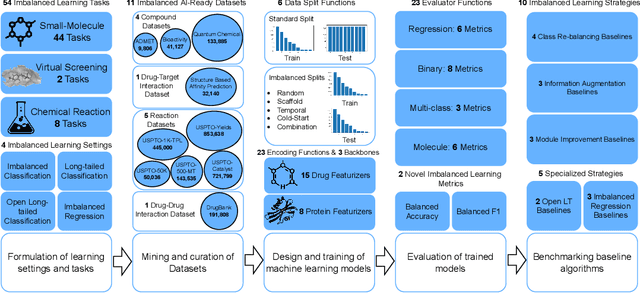

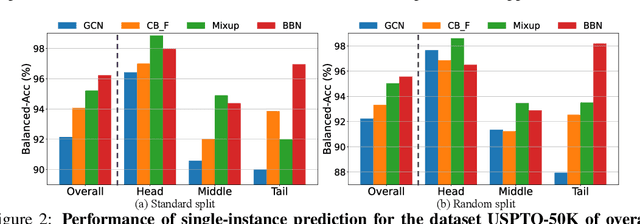
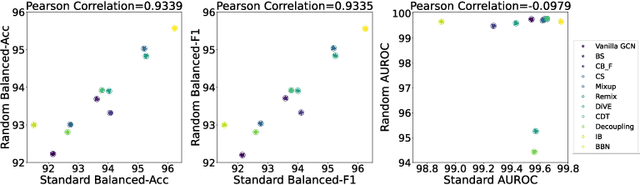
The last decade has witnessed a prosperous development of computational methods and dataset curation for AI-aided drug discovery (AIDD). However, real-world pharmaceutical datasets often exhibit highly imbalanced distribution, which is largely overlooked by the current literature but may severely compromise the fairness and generalization of machine learning applications. Motivated by this observation, we introduce ImDrug, a comprehensive benchmark with an open-source Python library which consists of 4 imbalance settings, 11 AI-ready datasets, 54 learning tasks and 16 baseline algorithms tailored for imbalanced learning. It provides an accessible and customizable testbed for problems and solutions spanning a broad spectrum of the drug discovery pipeline such as molecular modeling, drug-target interaction and retrosynthesis. We conduct extensive empirical studies with novel evaluation metrics, to demonstrate that the existing algorithms fall short of solving medicinal and pharmaceutical challenges in the data imbalance scenario. We believe that ImDrug opens up avenues for future research and development, on real-world challenges at the intersection of AIDD and deep imbalanced learning.
Quantized Adaptive Subgradient Algorithms and Their Applications
Aug 11, 2022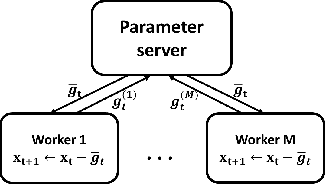
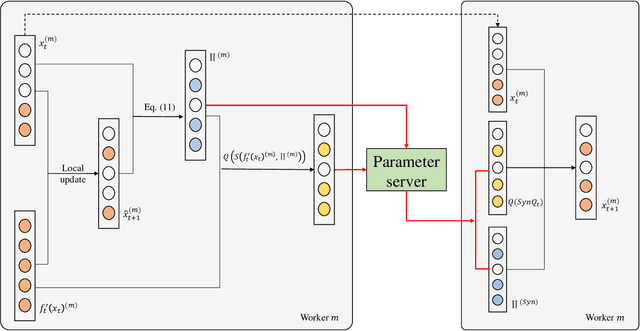
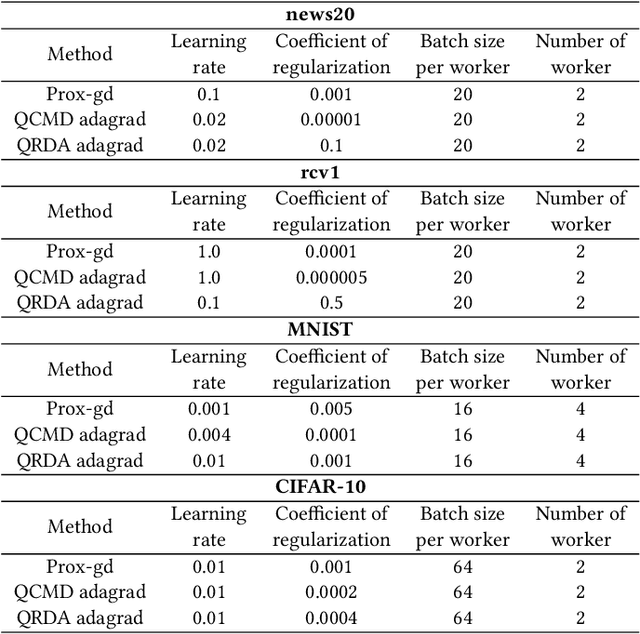

Data explosion and an increase in model size drive the remarkable advances in large-scale machine learning, but also make model training time-consuming and model storage difficult. To address the above issues in the distributed model training setting which has high computation efficiency and less device limitation, there are still two main difficulties. On one hand, the communication costs for exchanging information, e.g., stochastic gradients among different workers, is a key bottleneck for distributed training efficiency. On the other hand, less parameter model is easy for storage and communication, but the risk of damaging the model performance. To balance the communication costs, model capacity and model performance simultaneously, we propose quantized composite mirror descent adaptive subgradient (QCMD adagrad) and quantized regularized dual average adaptive subgradient (QRDA adagrad) for distributed training. To be specific, we explore the combination of gradient quantization and sparse model to reduce the communication cost per iteration in distributed training. A quantized gradient-based adaptive learning rate matrix is constructed to achieve a balance between communication costs, accuracy, and model sparsity. Moreover, we theoretically find that a large quantization error brings in extra noise, which influences the convergence and sparsity of the model. Therefore, a threshold quantization strategy with a relatively small error is adopted in QCMD adagrad and QRDA adagrad to improve the signal-to-noise ratio and preserve the sparsity of the model. Both theoretical analyses and empirical results demonstrate the efficacy and efficiency of the proposed algorithms.
ImGCL: Revisiting Graph Contrastive Learning on Imbalanced Node Classification
May 23, 2022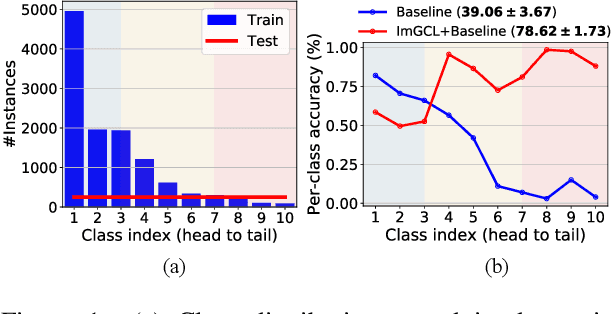
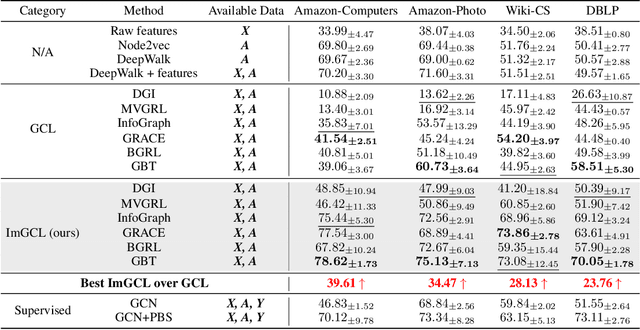
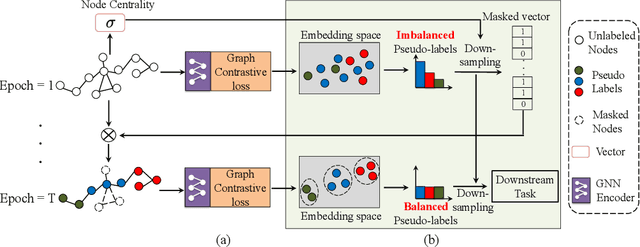
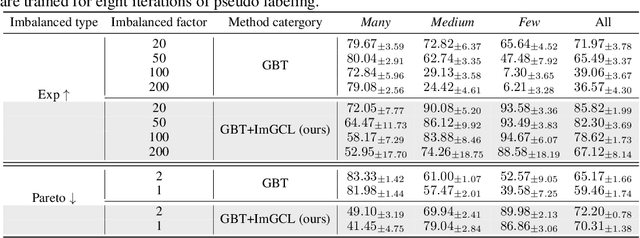
Graph contrastive learning (GCL) has attracted a surge of attention due to its superior performance for learning node/graph representations without labels. However, in practice, unlabeled nodes for the given graph usually follow an implicit imbalanced class distribution, where the majority of nodes belong to a small fraction of classes (a.k.a., head class) and the rest classes occupy only a few samples (a.k.a., tail classes). This highly imbalanced class distribution inevitably deteriorates the quality of learned node representations in GCL. Indeed, we empirically find that most state-of-the-art GCL methods exhibit poor performance on imbalanced node classification. Motivated by this observation, we propose a principled GCL framework on Imbalanced node classification (ImGCL), which automatically and adaptively balances the representation learned from GCL without knowing the labels. Our main inspiration is drawn from the recent progressively balanced sampling (PBS) method in the computer vision domain. We first introduce online clustering based PBS, which balances the training sets based on pseudo-labels obtained from learned representations. We then develop the node centrality based PBS method to better preserve the intrinsic structure of graphs, which highlight the important nodes of the given graph. Besides, we theoretically consolidate our method by proving that the classifier learned by balanced sampling without labels on an imbalanced dataset can converge to the optimal balanced classifier with a linear rate. Extensive experiments on multiple imbalanced graph datasets and imbalance settings verify the effectiveness of our proposed framework, which significantly improves the performance of the recent state-of-the-art GCL methods. Further experimental ablations and analysis show that the ImGCL framework remarkably improves the representations of nodes in tail classes.
A Survey of Trustworthy Graph Learning: Reliability, Explainability, and Privacy Protection
May 23, 2022


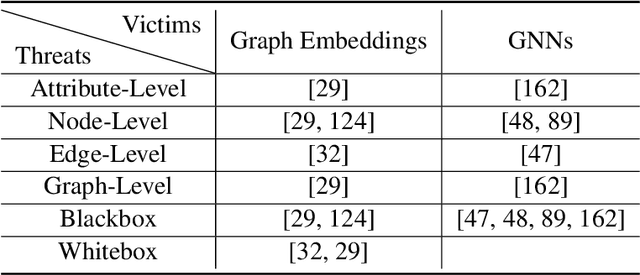
Deep graph learning has achieved remarkable progresses in both business and scientific areas ranging from finance and e-commerce, to drug and advanced material discovery. Despite these progresses, how to ensure various deep graph learning algorithms behave in a socially responsible manner and meet regulatory compliance requirements becomes an emerging problem, especially in risk-sensitive domains. Trustworthy graph learning (TwGL) aims to solve the above problems from a technical viewpoint. In contrast to conventional graph learning research which mainly cares about model performance, TwGL considers various reliability and safety aspects of the graph learning framework including but not limited to robustness, explainability, and privacy. In this survey, we provide a comprehensive review of recent leading approaches in the TwGL field from three dimensions, namely, reliability, explainability, and privacy protection. We give a general categorization for existing work and review typical work for each category. To give further insights for TwGL research, we provide a unified view to inspect previous works and build the connection between them. We also point out some important open problems remaining to be solved in the future developments of TwGL.
Multi-scale Attention Flow for Probabilistic Time Series Forecasting
May 16, 2022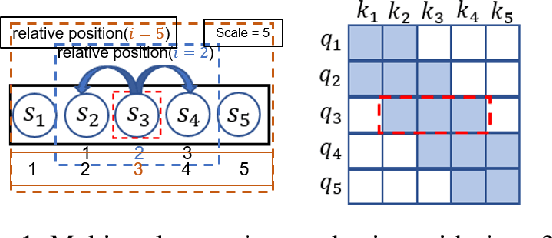
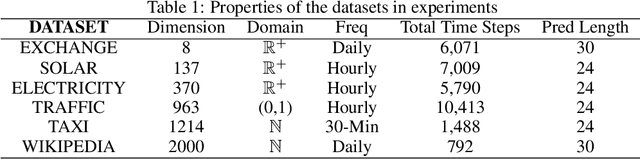
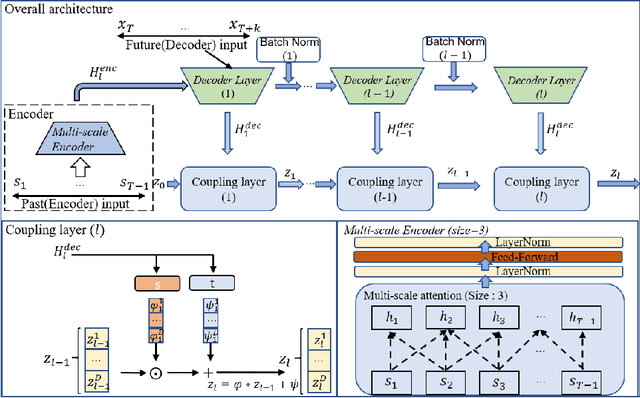
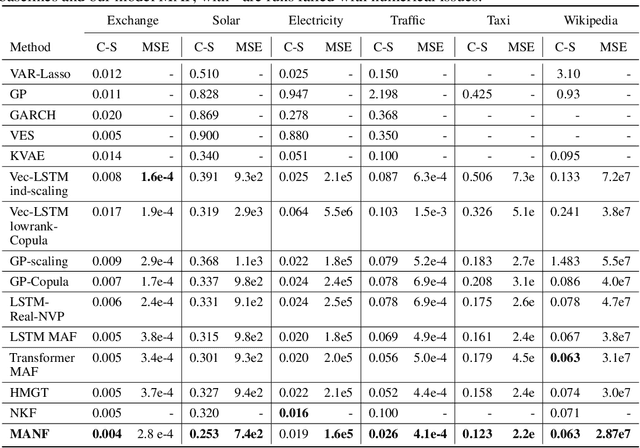
The probability prediction of multivariate time series is a notoriously challenging but practical task. On the one hand, the challenge is how to effectively capture the cross-series correlations between interacting time series, to achieve accurate distribution modeling. On the other hand, we should consider how to capture the contextual information within time series more accurately to model multivariate temporal dynamics of time series. In this work, we proposed a novel non-autoregressive deep learning model, called Multi-scale Attention Normalizing Flow(MANF), where we integrate multi-scale attention and relative position information and the multivariate data distribution is represented by the conditioned normalizing flow. Additionally, compared with autoregressive modeling methods, our model avoids the influence of cumulative error and does not increase the time complexity. Extensive experiments demonstrate that our model achieves state-of-the-art performance on many popular multivariate datasets.
GPN: A Joint Structural Learning Framework for Graph Neural Networks
May 12, 2022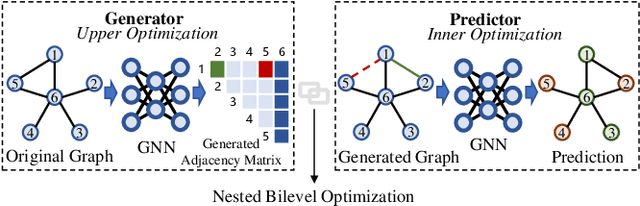
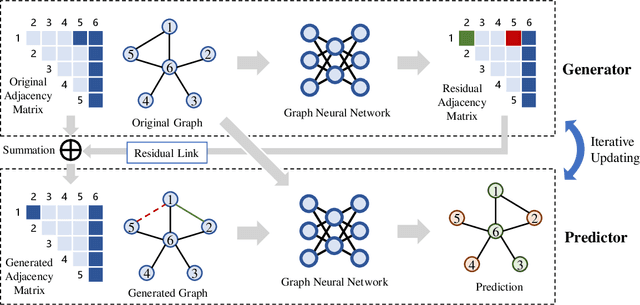
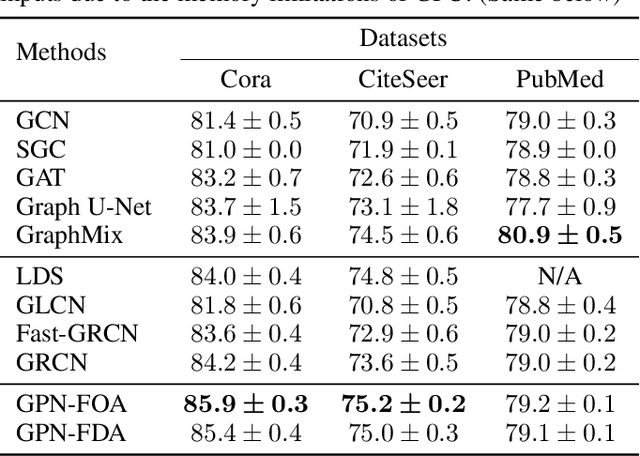
Graph neural networks (GNNs) have been applied into a variety of graph tasks. Most existing work of GNNs is based on the assumption that the given graph data is optimal, while it is inevitable that there exists missing or incomplete edges in the graph data for training, leading to degraded performance. In this paper, we propose Generative Predictive Network (GPN), a GNN-based joint learning framework that simultaneously learns the graph structure and the downstream task. Specifically, we develop a bilevel optimization framework for this joint learning task, in which the upper optimization (generator) and the lower optimization (predictor) are both instantiated with GNNs. To the best of our knowledge, our method is the first GNN-based bilevel optimization framework for resolving this task. Through extensive experiments, our method outperforms a wide range of baselines using benchmark datasets.
DRFLM: Distributionally Robust Federated Learning with Inter-client Noise via Local Mixup
Apr 16, 2022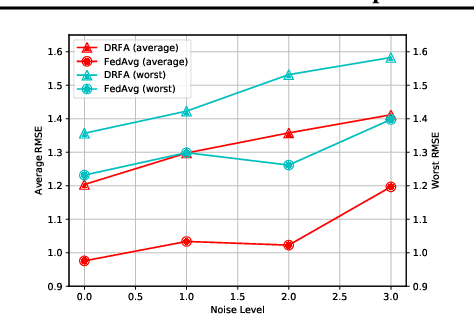
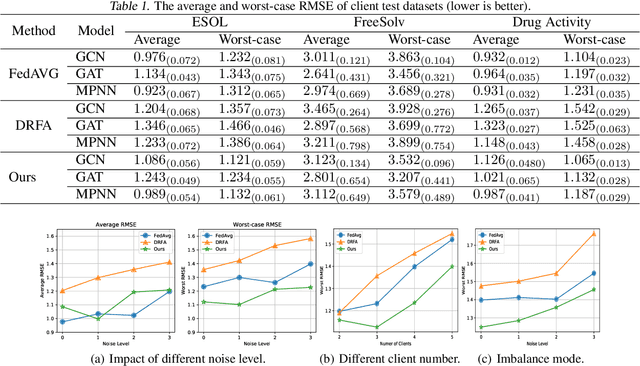
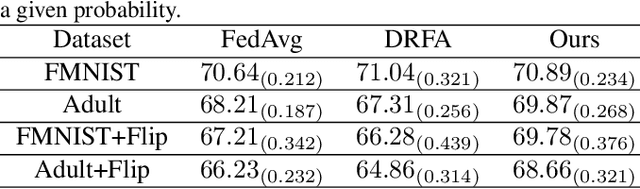
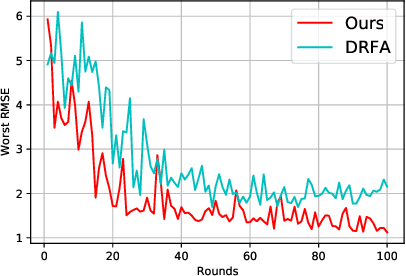
Recently, federated learning has emerged as a promising approach for training a global model using data from multiple organizations without leaking their raw data. Nevertheless, directly applying federated learning to real-world tasks faces two challenges: (1) heterogeneity in the data among different organizations; and (2) data noises inside individual organizations. In this paper, we propose a general framework to solve the above two challenges simultaneously. Specifically, we propose using distributionally robust optimization to mitigate the negative effects caused by data heterogeneity paradigm to sample clients based on a learnable distribution at each iteration. Additionally, we observe that this optimization paradigm is easily affected by data noises inside local clients, which has a significant performance degradation in terms of global model prediction accuracy. To solve this problem, we propose to incorporate mixup techniques into the local training process of federated learning. We further provide comprehensive theoretical analysis including robustness analysis, convergence analysis, and generalization ability. Furthermore, we conduct empirical studies across different drug discovery tasks, such as ADMET property prediction and drug-target affinity prediction.