 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVT: Transferable Vision Transformer for Unsupervised Domain Adaptation
Aug 12, 2021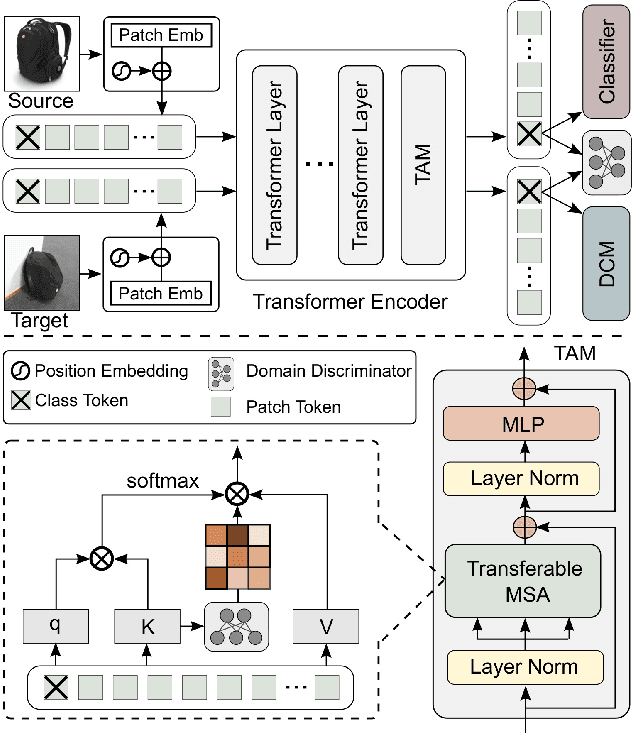
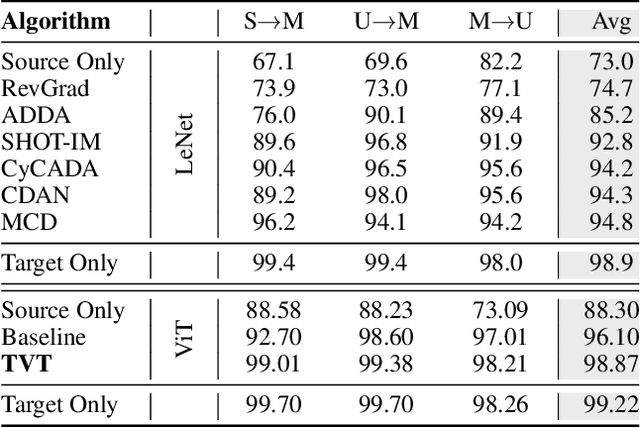
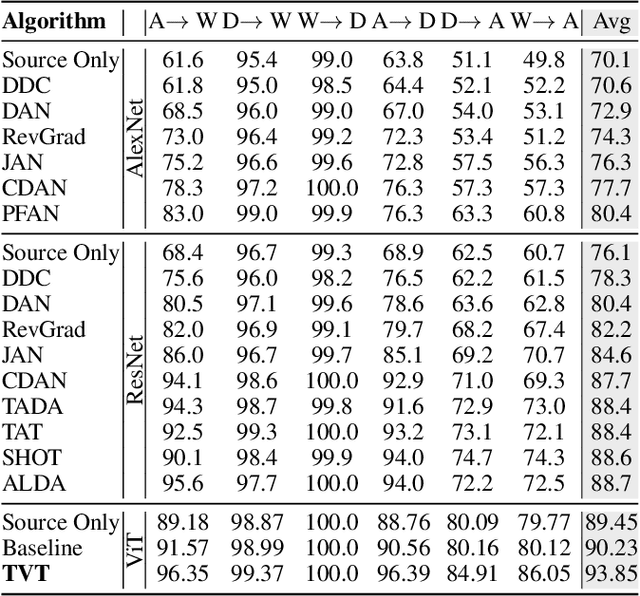

Unsupervised domain adaptation (UDA) aims to transfer the knowledge learnt from a labeled source domain to an unlabeled target domain. Previous work is mainly built upon convolutional neural networks (CNNs) to learn domain-invariant representations. With the recent exponential increase in applying Vision Transformer (ViT) to vision tasks, the capability of ViT in adapting cross-domain knowledge, however, remains unexplored in the literature. To fill this gap, this paper first comprehensively investigates the transferability of ViT on a variety of domain adaptation tasks. Surprisingly, ViT demonstrates superior transferability over its CNNs-based counterparts with a large margin, while the performance can be further improved by incorporating adversarial adaptation. Notwithstanding, directly using CNNs-based adaptation strategies fails to take the advantage of ViT's intrinsic merits (e.g., attention mechanism and sequential image representation) which play an important role in knowledge transfer. To remedy this, we propose an unified framework, namely Transferable Vision Transformer (TVT), to fully exploit the transferability of ViT for domain adaptation. Specifically, we delicately devise a novel and effective unit, which we term Transferability Adaption Module (TAM). By injecting learned transferabilities into attention blocks, TAM compels ViT focus on both transferable and discriminative features. Besides, we leverage discriminative clustering to enhance feature diversity and separation which are undermined during adversarial domain alignment. To verify its versatility, we perform extensive studies of TVT on four benchmarks and the experimental results demonstrate that TVT attains significant improvements compared to existing state-of-the-art UDA methods.
Learning by Planning: Language-Guided Global Image Editing
Jun 24, 2021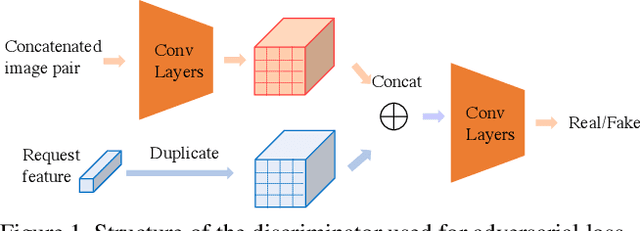
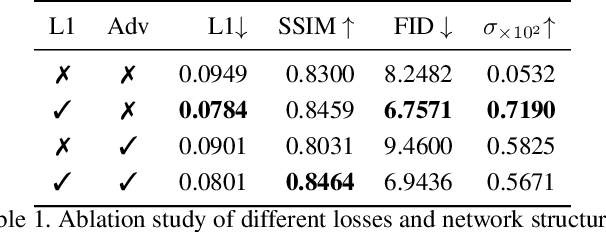
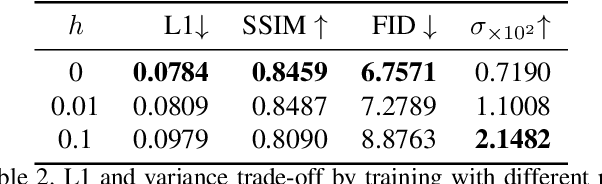

Recently, language-guided global image editing draws increasing attention with growing application potentials. However, previous GAN-based methods are not only confined to domain-specific, low-resolution data but also lacking in interpretability. To overcome the collective difficulties, we develop a text-to-operation model to map the vague editing language request into a series of editing operations, e.g., change contrast, brightness, and saturation. Each operation is interpretable and differentiable. Furthermore, the only supervision in the task is the target image, which is insufficient for a stable training of sequential decisions. Hence, we propose a novel operation planning algorithm to generate possible editing sequences from the target image as pseudo ground truth. Comparison experiments on the newly collected MA5k-Req dataset and GIER dataset show the advantages of our methods. Code is available at https://jshi31.github.io/T2ONet.
Learngene: From Open-World to Your Learning Task
Jun 12, 2021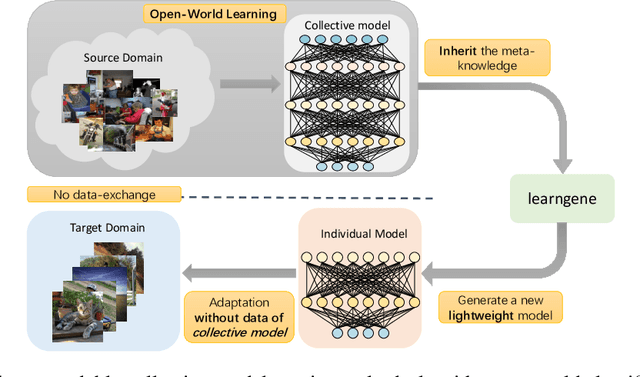

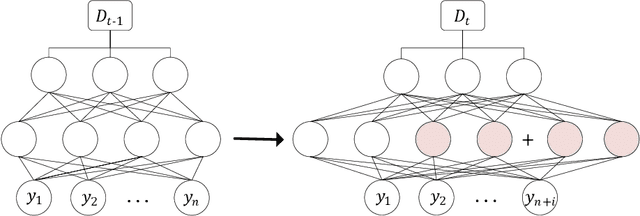
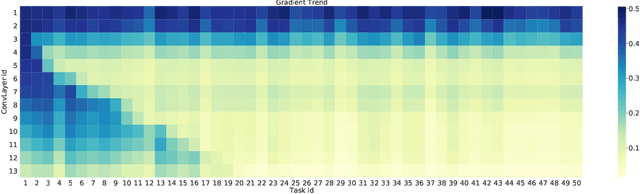
Although deep learning has made significant progress on fixed large-scale datasets, it typically encounters challenges regarding improperly detecting new/unseen classes in the open-world classification, over-parametrized, and overfitting small samples. In contrast, biological systems can overcome the above difficulties very well. Individuals inherit an innate gene from collective creatures that have evolved over hundreds of millions of years, and can learn new skills through a few examples. Inspired by this, we propose a practical collective-individual paradigm where open-world tasks are trained in sequence using an evolution (expandable) network. To be specific, we innovatively introduce learngene that inherits the meta-knowledge from the collective model and reconstructs a new lightweight individual model for the target task, to realize the collective-individual paradigm. Particularly, we present a novel criterion that can discover the learngene in the collective model, according to the gradient information. Finally, the individual model is trained only with a few samples in the absence of the source data. We demonstrate the effectiveness of our approach in an extensive empirical study and theoretical analysis.
Semantic Layout Manipulation with High-Resolution Sparse Attention
Dec 14, 2020
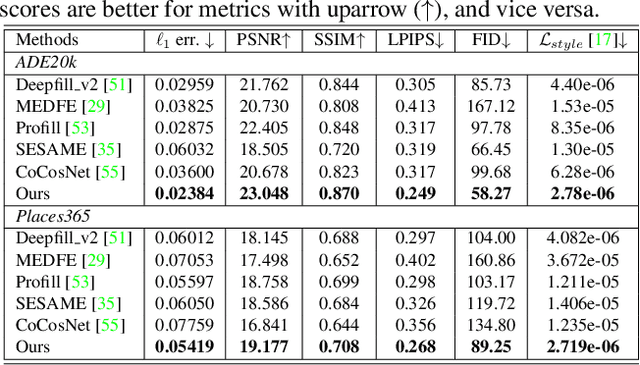
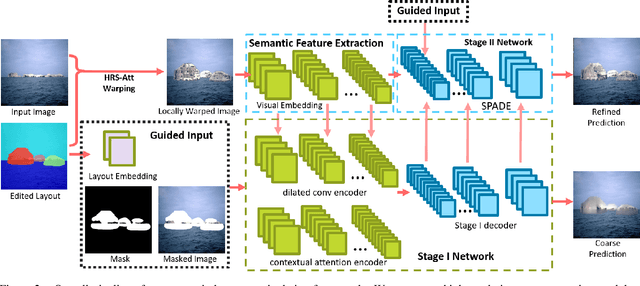
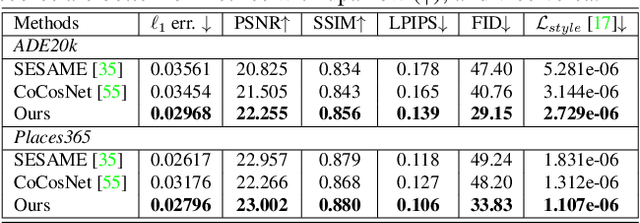
We tackle the problem of semantic image layout manipulation, which aims to manipulate an input image by editing its semantic label map. A core problem of this task is how to transfer visual details from the input images to the new semantic layout while making the resulting image visually realistic. Recent work on learning cross-domain correspondence has shown promising results for global layout transfer with dense attention-based warping. However, this method tends to lose texture details due to the lack of smoothness and resolution in the correspondence and warped images. To adapt this paradigm for the layout manipulation task, we propose a high-resolution sparse attention module that effectively transfers visual details to new layouts at a resolution up to 512x512. To further improve visual quality, we introduce a novel generator architecture consisting of a semantic encoder and a two-stage decoder for coarse-to-fine synthesis. Experiments on the ADE20k and Places365 datasets demonstrate that our proposed approach achieves substantial improvements over the existing inpainting and layout manipulation methods.
Mask Guided Matting via Progressive Refinement Network
Dec 12, 2020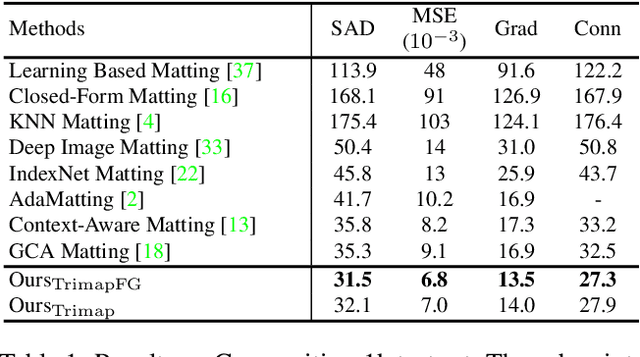
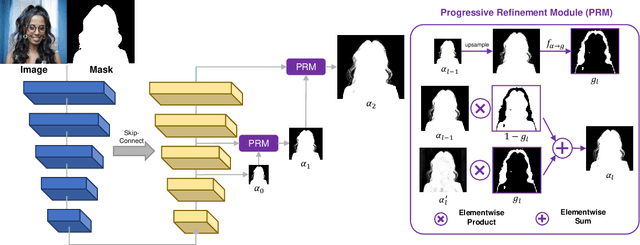
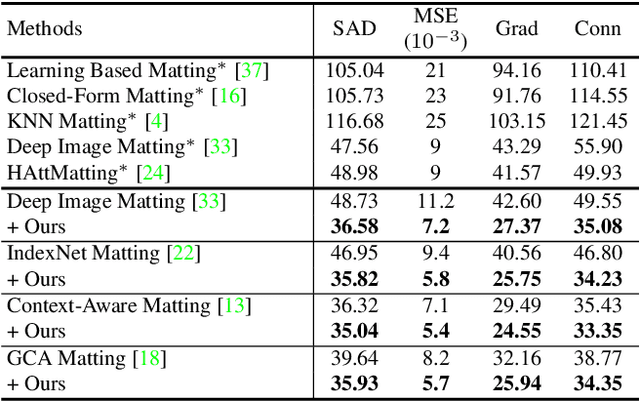

We propose Mask Guided (MG) Matting, a robust matting framework that takes a general coarse mask as guidance. MG Matting leverages a network (PRN) design which encourages the matting model to provide self-guidance to progressively refine the uncertain regions through the decoding process. A series of guidance mask perturbation operations are also introduced in the training to further enhance its robustness to external guidance. We show that PRN can generalize to unseen types of guidance masks such as trimap and low-quality alpha matte, making it suitable for various application pipelines. In addition, we revisit the foreground color prediction problem for matting and propose a surprisingly simple improvement to address the dataset issue. Evaluation on real and synthetic benchmarks shows that MG Matting achieves state-of-the-art performance using various types of guidance inputs. Code and models will be available at https://github.com/yucornetto/MGMatting
Delving into the Cyclic Mechanism in Semi-supervised Video Object Segmentation
Oct 23, 2020
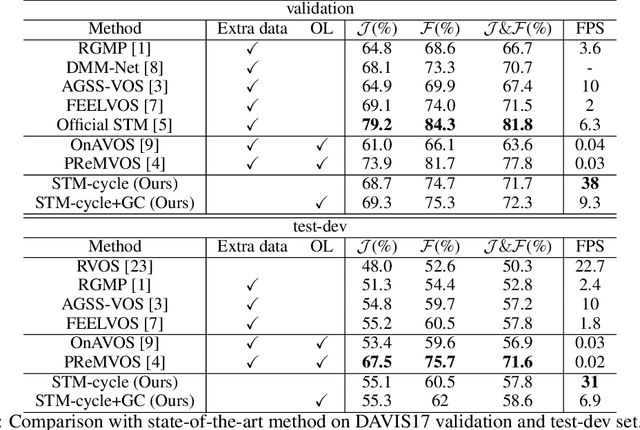
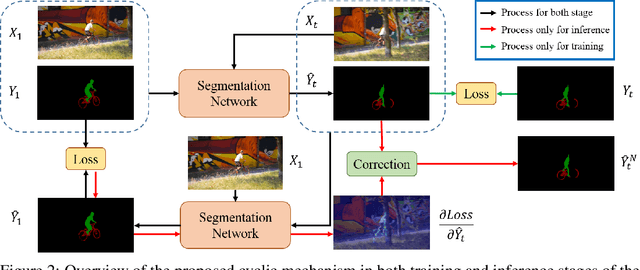
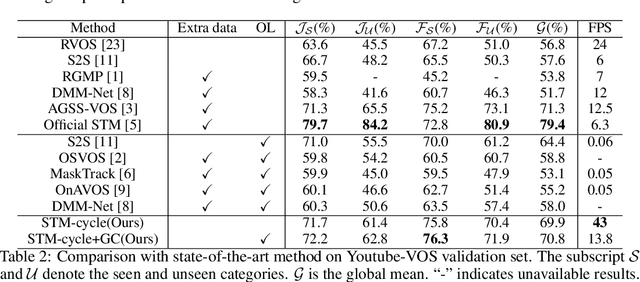
In this paper, we address several inadequacies of current video object segmentation pipelines. Firstly, a cyclic mechanism is incorporated to the standard semi-supervised process to produce more robust representations. By relying on the accurate reference mask in the starting frame, we show that the error propagation problem can be mitigated. Next, we introduce a simple gradient correction module, which extends the offline pipeline to an online method while maintaining the efficiency of the former. Finally we develop cycle effective receptive field (cycle-ERF) based on gradient correction to provide a new perspective into analyzing object-specific regions of interests. We conduct comprehensive experiments on challenging benchmarks of DAVIS17 and Youtube-VOS, demonstrating that the cyclic mechanism is beneficial to segmentation quality.
A Benchmark and Baseline for Language-Driven Image Editing
Oct 05, 2020

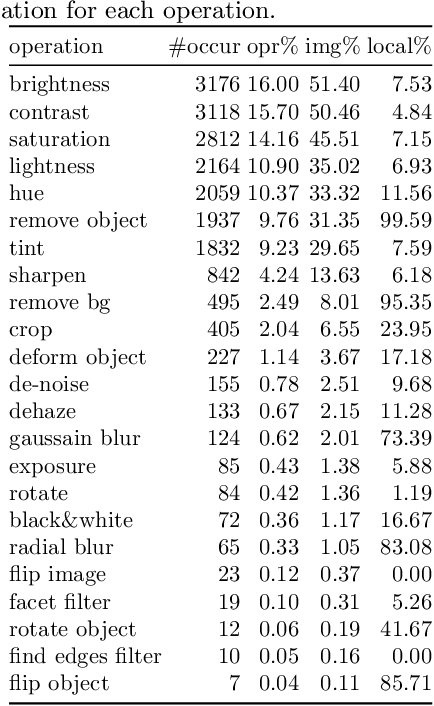
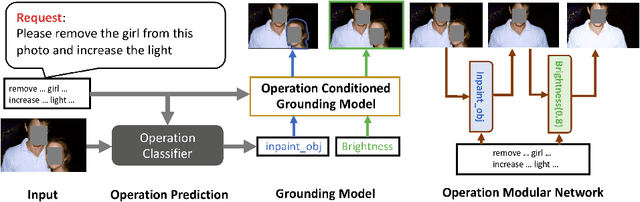
Language-driven image editing can significantly save the laborious image editing work and be friendly to the photography novice. However, most similar work can only deal with a specific image domain or can only do global retouching. To solve this new task, we first present a new language-driven image editing dataset that supports both local and global editing with editing operation and mask annotations. Besides, we also propose a baseline method that fully utilizes the annotation to solve this problem. Our new method treats each editing operation as a sub-module and can automatically predict operation parameters. Not only performing well on challenging user data, but such an approach is also highly interpretable. We believe our work, including both the benchmark and the baseline, will advance the image editing area towards a more general and free-form level.
Compact Learning for Multi-Label Classification
Sep 18, 2020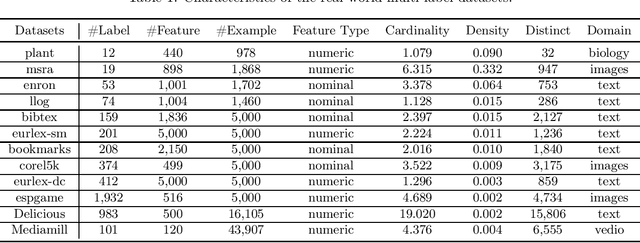
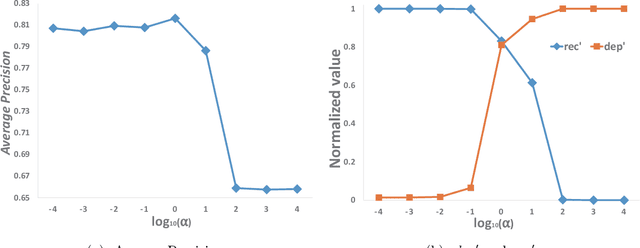
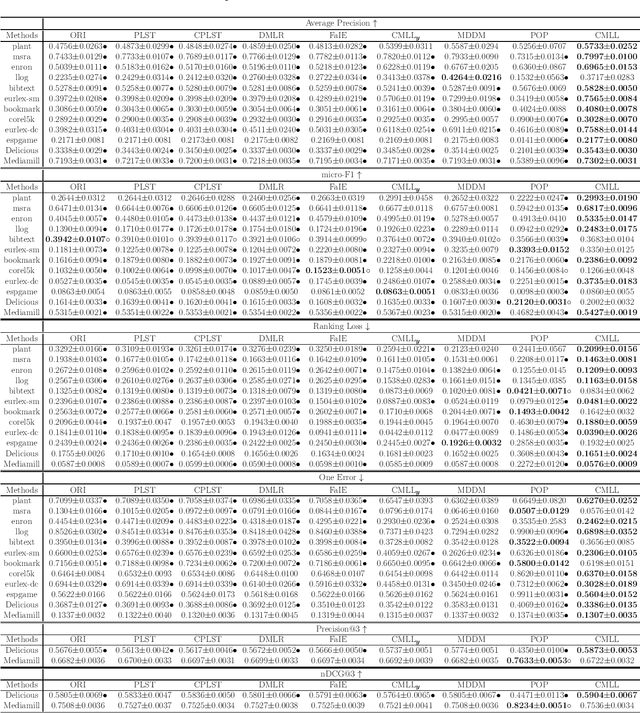
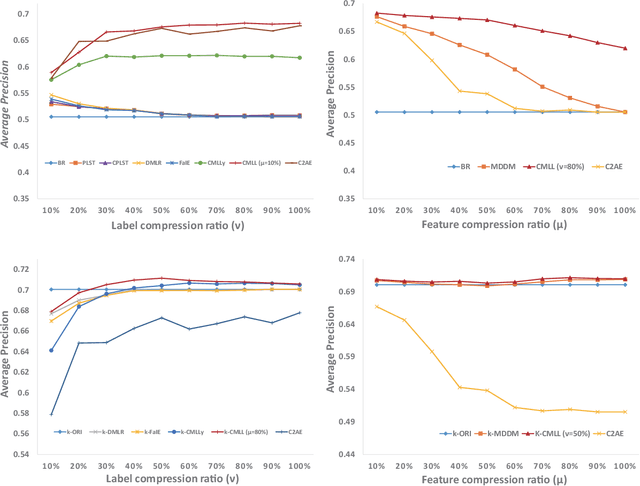
Multi-label classification (MLC) studies the problem where each instance is associated with multiple relevant labels, which leads to the exponential growth of output space. MLC encourages a popular framework named label compression (LC) for capturing label dependency with dimension reduction. Nevertheless, most existing LC methods failed to consider the influence of the feature space or misguided by original problematic features, so that may result in performance degeneration. In this paper, we present a compact learning (CL) framework to embed the features and labels simultaneously and with mutual guidance. The proposal is a versatile concept, hence the embedding way is arbitrary and independent of the subsequent learning process. Following its spirit, a simple yet effective implementation called compact multi-label learning (CMLL) is proposed to learn a compact low-dimensional representation for both spaces. CMLL maximizes the dependence between the embedded spaces of the labels and features, and minimizes the loss of label space recovery concurrently. Theoretically, we provide a general analysis for different embedding methods. Practically, we conduct extensive experiments to validate the effectiveness of the proposed method.
High-Resolution Deep Image Matting
Sep 14, 2020
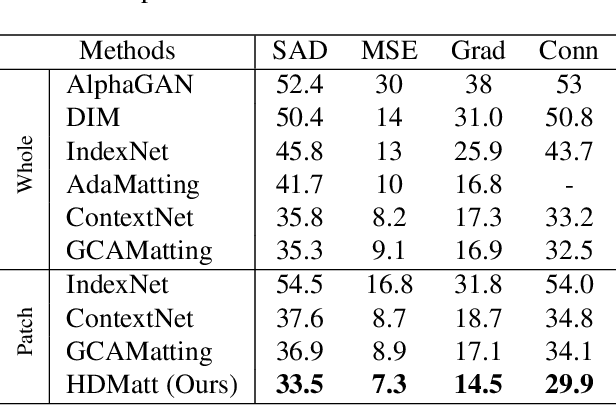
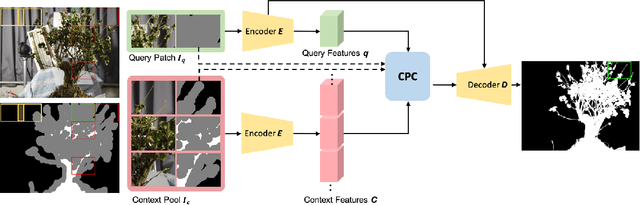
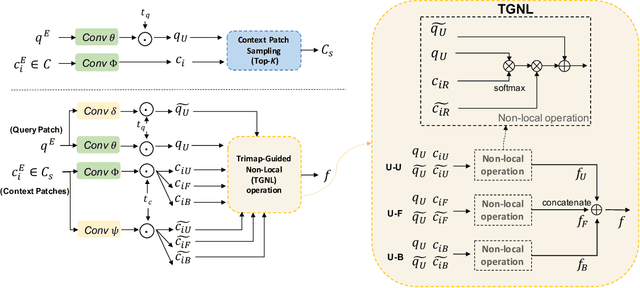
Image matting is a key technique for image and video editing and composition. Conventionally, deep learning approaches take the whole input image and an associated trimap to infer the alpha matte using convolutional neural networks. Such approaches set state-of-the-arts in image matting; however, they may fail in real-world matting applications due to hardware limitations, since real-world input images for matting are mostly of very high resolution. In this paper, we propose HDMatt, a first deep learning based image matting approach for high-resolution inputs. More concretely, HDMatt runs matting in a patch-based crop-and-stitch manner for high-resolution inputs with a novel module design to address the contextual dependency and consistency issues between different patches. Compared with vanilla patch-based inference which computes each patch independently, we explicitly model the cross-patch contextual dependency with a newly-proposed Cross-Patch Contextual module (CPC) guided by the given trimap. Extensive experiments demonstrate the effectiveness of the proposed method and its necessity for high-resolution inputs. Our HDMatt approach also sets new state-of-the-art performance on Adobe Image Matting and AlphaMatting benchmarks and produce impressive visual results on more real-world high-resolution images.
Finding Action Tubes with a Sparse-to-Dense Framework
Aug 30, 2020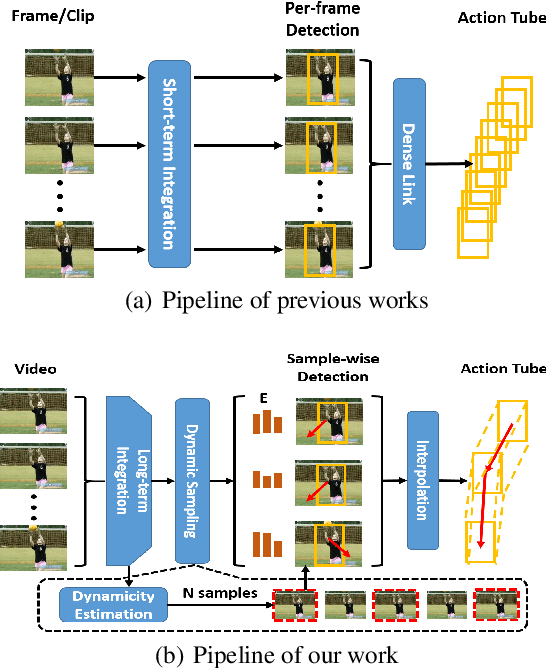

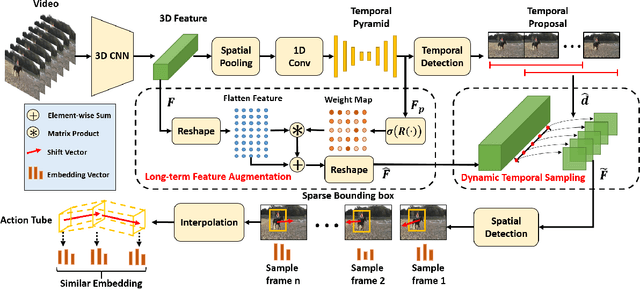
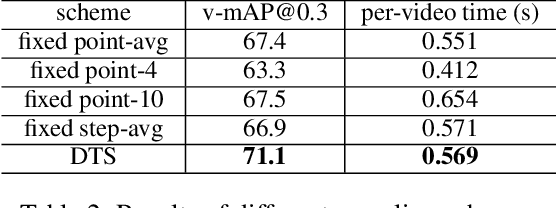
The task of spatial-temporal action detection has attracted increasing attention among researchers. Existing dominant methods solve this problem by relying on short-term information and dense serial-wise detection on each individual frames or clips. Despite their effectiveness, these methods showed inadequate use of long-term information and are prone to inefficiency. In this paper, we propose for the first time, an efficient framework that generates action tube proposals from video streams with a single forward pass in a sparse-to-dense manner. There are two key characteristics in this framework: (1) Both long-term and short-term sampled information are explicitly utilized in our spatiotemporal network, (2) A new dynamic feature sampling module (DTS) is designed to effectively approximate the tube output while keeping the system tractable. We evaluate the efficacy of our model on the UCF101-24, JHMDB-21 and UCFSports benchmark datasets, achieving promising results that are competitive to state-of-the-art methods. The proposed sparse-to-dense strategy rendered our framework about 7.6 times more efficient than the nearest competitor.