 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Touch, Vision, and Language Dataset for Multimodal Alignment
Feb 20, 2024Touch is an important sensing modality for humans, but it has not yet been incorporated into a multimodal generative language model. This is partially due to the difficulty of obtaining natural language labels for tactile data and the complexity of aligning tactile readings with both visual observations and language descriptions. As a step towards bridging that gap, this work introduces a new dataset of 44K in-the-wild vision-touch pairs, with English language labels annotated by humans (10%) and textual pseudo-labels from GPT-4V (90%). We use this dataset to train a vision-language-aligned tactile encoder for open-vocabulary classification and a touch-vision-language (TVL) model for text generation using the trained encoder. Results suggest that by incorporating touch, the TVL model improves (+29% classification accuracy) touch-vision-language alignment over existing models trained on any pair of those modalities. Although only a small fraction of the dataset is human-labeled, the TVL model demonstrates improved visual-tactile understanding over GPT-4V (+12%) and open-source vision-language models (+32%) on a new touch-vision understanding benchmark. Code and data: https://tactile-vlm.github.io.
Neural feels with neural fields: Visuo-tactile perception for in-hand manipulation
Dec 20, 2023To achieve human-level dexterity, robots must infer spatial awareness from multimodal sensing to reason over contact interactions. During in-hand manipulation of novel objects, such spatial awareness involves estimating the object's pose and shape. The status quo for in-hand perception primarily employs vision, and restricts to tracking a priori known objects. Moreover, visual occlusion of objects in-hand is imminent during manipulation, preventing current systems to push beyond tasks without occlusion. We combine vision and touch sensing on a multi-fingered hand to estimate an object's pose and shape during in-hand manipulation. Our method, NeuralFeels, encodes object geometry by learning a neural field online and jointly tracks it by optimizing a pose graph problem. We study multimodal in-hand perception in simulation and the real-world, interacting with different objects via a proprioception-driven policy. Our experiments show final reconstruction F-scores of $81$% and average pose drifts of $4.7\,\text{mm}$, further reduced to $2.3\,\text{mm}$ with known CAD models. Additionally, we observe that under heavy visual occlusion we can achieve up to $94$% improvements in tracking compared to vision-only methods. Our results demonstrate that touch, at the very least, refines and, at the very best, disambiguates visual estimates during in-hand manipulation. We release our evaluation dataset of 70 experiments, FeelSight, as a step towards benchmarking in this domain. Our neural representation driven by multimodal sensing can serve as a perception backbone towards advancing robot dexterity. Videos can be found on our project website https://suddhu.github.io/neural-feels/
TaskMet: Task-Driven Metric Learning for Model Learning
Dec 08, 2023



Deep learning models are often deployed in downstream tasks that the training procedure may not be aware of. For example, models solely trained to achieve accurate predictions may struggle to perform well on downstream tasks because seemingly small prediction errors may incur drastic task errors. The standard end-to-end learning approach is to make the task loss differentiable or to introduce a differentiable surrogate that the model can be trained on. In these settings, the task loss needs to be carefully balanced with the prediction loss because they may have conflicting objectives. We propose take the task loss signal one level deeper than the parameters of the model and use it to learn the parameters of the loss function the model is trained on, which can be done by learning a metric in the prediction space. This approach does not alter the optimal prediction model itself, but rather changes the model learning to emphasize the information important for the downstream task. This enables us to achieve the best of both worlds: a prediction model trained in the original prediction space while also being valuable for the desired downstream task. We validate our approach through experiments conducted in two main settings: 1) decision-focused model learning scenarios involving portfolio optimization and budget allocation, and 2) reinforcement learning in noisy environments with distracting states. The source code to reproduce our experiments is available at https://github.com/facebookresearch/taskmet
Perceiving Extrinsic Contacts from Touch Improves Learning Insertion Policies
Sep 28, 2023



Robotic manipulation tasks such as object insertion typically involve interactions between object and environment, namely extrinsic contacts. Prior work on Neural Contact Fields (NCF) use intrinsic tactile sensing between gripper and object to estimate extrinsic contacts in simulation. However, its effectiveness and utility in real-world tasks remains unknown. In this work, we improve NCF to enable sim-to-real transfer and use it to train policies for mug-in-cupholder and bowl-in-dishrack insertion tasks. We find our model NCF-v2, is capable of estimating extrinsic contacts in the real-world. Furthermore, our insertion policy with NCF-v2 outperforms policies without it, achieving 33% higher success and 1.36x faster execution on mug-in-cupholder, and 13% higher success and 1.27x faster execution on bowl-in-dishrack.
Decentralization and Acceleration Enables Large-Scale Bundle Adjustment
May 15, 2023



Scaling to arbitrarily large bundle adjustment problems requires data and compute to be distributed across multiple devices. Centralized methods in prior works are only able to solve small or medium size problems due to overhead in computation and communication. In this paper, we present a fully decentralized method that alleviates computation and communication bottlenecks to solve arbitrarily large bundle adjustment problems. We achieve this by reformulating the reprojection error and deriving a novel surrogate function that decouples optimization variables from different devices. This function makes it possible to use majorization minimization techniques and reduces bundle adjustment to independent optimization subproblems that can be solved in parallel. We further apply Nesterov's acceleration and adaptive restart to improve convergence while maintaining its theoretical guarantees. Despite limited peer-to-peer communication, our method has provable convergence to first-order critical points under mild conditions. On extensive benchmarks with public datasets, our method converges much faster than decentralized baselines with similar memory usage and communication load. Compared to centralized baselines using a single device, our method, while being decentralized, yields more accurate solutions with significant speedups of up to 953.7x over Ceres and 174.6x over DeepLM. Code: https://github.com/facebookresearch/DABA.
USA-Net: Unified Semantic and Affordance Representations for Robot Memory
Apr 25, 2023



In order for robots to follow open-ended instructions like "go open the brown cabinet over the sink", they require an understanding of both the scene geometry and the semantics of their environment. Robotic systems often handle these through separate pipelines, sometimes using very different representation spaces, which can be suboptimal when the two objectives conflict. In this work, we present USA-Net, a simple method for constructing a world representation that encodes both the semantics and spatial affordances of a scene in a differentiable map. This allows us to build a gradient-based planner which can navigate to locations in the scene specified using open-ended vocabulary. We use this planner to consistently generate trajectories which are both shorter 5-10% shorter and 10-30% closer to our goal query in CLIP embedding space than paths from comparable grid-based planners which don't leverage gradient information. To our knowledge, this is the first end-to-end differentiable planner optimizes for both semantics and affordance in a single implicit map. Code and visuals are available at our website: https://usa.bolte.cc/
Learning to Read Braille: Bridging the Tactile Reality Gap with Diffusion Models
Apr 03, 2023Simulating vision-based tactile sensors enables learning models for contact-rich tasks when collecting real world data at scale can be prohibitive. However, modeling the optical response of the gel deformation as well as incorporating the dynamics of the contact makes sim2real challenging. Prior works have explored data augmentation, fine-tuning, or learning generative models to reduce the sim2real gap. In this work, we present the first method to leverage probabilistic diffusion models for capturing complex illumination changes from gel deformations. Our tactile diffusion model is able to generate realistic tactile images from simulated contact depth bridging the reality gap for vision-based tactile sensing. On real braille reading task with a DIGIT sensor, a classifier trained with our diffusion model achieves 75.74% accuracy outperforming classifiers trained with simulation and other approaches. Project page: https://github.com/carolinahiguera/Tactile-Diffusion
Neural Grasp Distance Fields for Robot Manipulation
Nov 04, 2022We formulate grasp learning as a neural field and present Neural Grasp Distance Fields (NGDF). Here, the input is a 6D pose of a robot end effector and output is a distance to a continuous manifold of valid grasps for an object. In contrast to current approaches that predict a set of discrete candidate grasps, the distance-based NGDF representation is easily interpreted as a cost, and minimizing this cost produces a successful grasp pose. This grasp distance cost can be incorporated directly into a trajectory optimizer for joint optimization with other costs such as trajectory smoothness and collision avoidance. During optimization, as the various costs are balanced and minimized, the grasp target is allowed to smoothly vary, as the learned grasp field is continuous. In simulation benchmarks with a Franka arm, we find that joint grasping and planning with NGDF outperforms baselines by 63% execution success while generalizing to unseen query poses and unseen object shapes. Project page: https://sites.google.com/view/neural-grasp-distance-fields.
MidasTouch: Monte-Carlo inference over distributions across sliding touch
Oct 25, 2022



We present MidasTouch, a tactile perception system for online global localization of a vision-based touch sensor sliding on an object surface. This framework takes in posed tactile images over time, and outputs an evolving distribution of sensor pose on the object's surface, without the need for visual priors. Our key insight is to estimate local surface geometry with tactile sensing, learn a compact representation for it, and disambiguate these signals over a long time horizon. The backbone of MidasTouch is a Monte-Carlo particle filter, with a measurement model based on a tactile code network learned from tactile simulation. This network, inspired by LIDAR place recognition, compactly summarizes local surface geometries. These generated codes are efficiently compared against a precomputed tactile codebook per-object, to update the pose distribution. We further release the YCB-Slide dataset of real-world and simulated forceful sliding interactions between a vision-based tactile sensor and standard YCB objects. While single-touch localization can be inherently ambiguous, we can quickly localize our sensor by traversing salient surface geometries. Project page: https://suddhu.github.io/midastouch-tactile/
Neural Contact Fields: Tracking Extrinsic Contact with Tactile Sensing
Oct 17, 2022

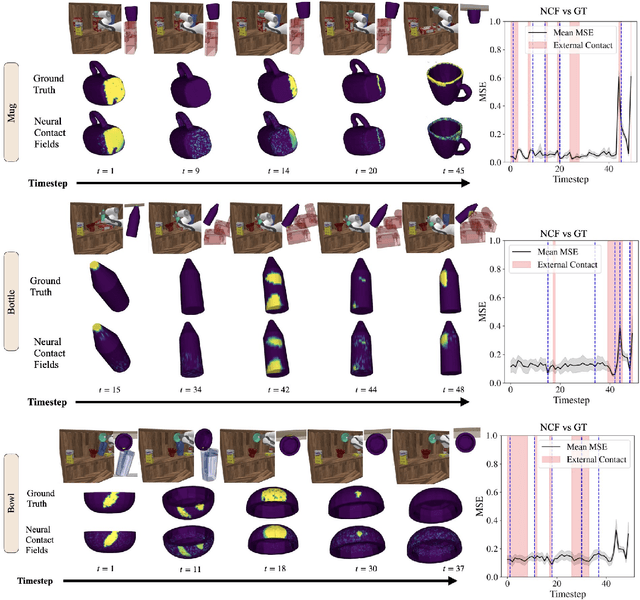
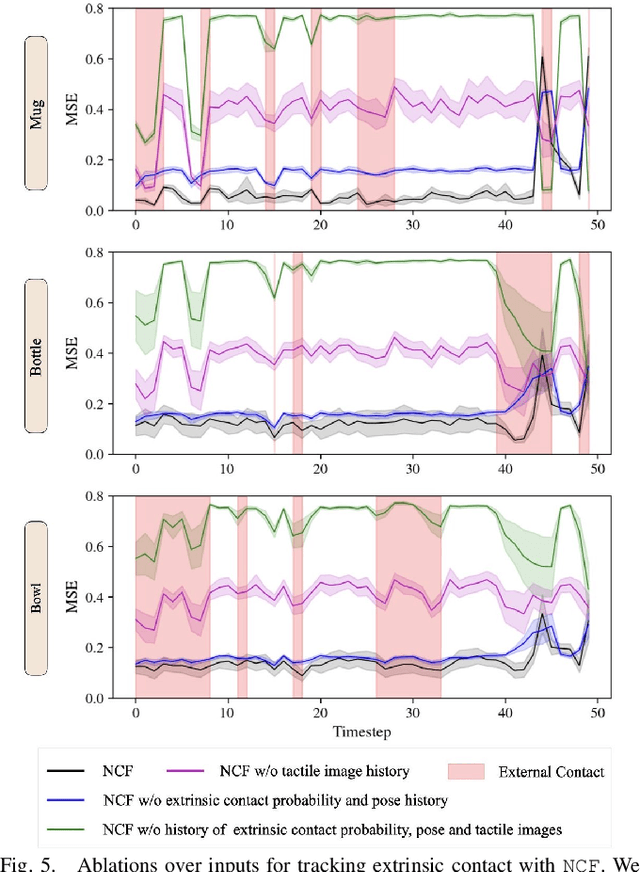
We present Neural Contact Fields, a method that brings together neural fields and tactile sensing to address the problem of tracking extrinsic contact between object and environment. Knowing where the external contact occurs is a first step towards methods that can actively control it in facilitating downstream manipulation tasks. Prior work for localizing environmental contacts typically assume a contact type (e.g. point or line), does not capture contact/no-contact transitions, and only works with basic geometric-shaped objects. Neural Contact Fields are the first method that can track arbitrary multi-modal extrinsic contacts without making any assumptions about the contact type. Our key insight is to estimate the probability of contact for any 3D point in the latent space of object shapes, given vision-based tactile inputs that sense the local motion resulting from the external contact. In experiments, we find that Neural Contact Fields are able to localize multiple contact patches without making any assumptions about the geometry of the contact, and capture contact/no-contact transitions for known categories of objects with unseen shapes in unseen environment configurations. In addition to Neural Contact Fields, we also release our YCB-Extrinsic-Contact dataset of simulated extrinsic contact interactions to enable further research in this area. Project repository: https://github.com/carolinahiguera/NCF