 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeW2S-AlignTree: Weak-to-Strong Inference-Time Alignment for Large Language Models via Monte Carlo Tree Search
Nov 14, 2025



Large Language Models (LLMs) demonstrate impressive capabilities, yet their outputs often suffer from misalignment with human preferences due to the inadequacy of weak supervision and a lack of fine-grained control. Training-time alignment methods like Reinforcement Learning from Human Feedback (RLHF) face prohibitive costs in expert supervision and inherent scalability limitations, offering limited dynamic control during inference. Consequently, there is an urgent need for scalable and adaptable alignment mechanisms. To address this, we propose W2S-AlignTree, a pioneering plug-and-play inference-time alignment framework that synergistically combines Monte Carlo Tree Search (MCTS) with the Weak-to-Strong Generalization paradigm for the first time. W2S-AlignTree formulates LLM alignment as an optimal heuristic search problem within a generative search tree. By leveraging weak model's real-time, step-level signals as alignment proxies and introducing an Entropy-Aware exploration mechanism, W2S-AlignTree enables fine-grained guidance during strong model's generation without modifying its parameters. The approach dynamically balances exploration and exploitation in high-dimensional generation search trees. Experiments across controlled sentiment generation, summarization, and instruction-following show that W2S-AlignTree consistently outperforms strong baselines. Notably, W2S-AlignTree raises the performance of Llama3-8B from 1.89 to 2.19, a relative improvement of 15.9 on the summarization task.
LLMEval-3: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Aug 07, 2025Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-3, a framework for dynamic evaluation of LLMs. LLMEval-3 is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. An 20-month longitudinal study of nearly 50 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-3 offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards.
Code2Logic: Game-Code-Driven Data Synthesis for Enhancing VLMs General Reasoning
May 20, 2025Visual-language Chain-of-Thought (CoT) data resources are relatively scarce compared to text-only counterparts, limiting the improvement of reasoning capabilities in Vision Language Models (VLMs). However, high-quality vision-language reasoning data is expensive and labor-intensive to annotate. To address this issue, we leverage a promising resource: game code, which naturally contains logical structures and state transition processes. Therefore, we propose Code2Logic, a novel game-code-driven approach for multimodal reasoning data synthesis. Our approach leverages Large Language Models (LLMs) to adapt game code, enabling automatic acquisition of reasoning processes and results through code execution. Using the Code2Logic approach, we developed the GameQA dataset to train and evaluate VLMs. GameQA is cost-effective and scalable to produce, challenging for state-of-the-art models, and diverse with 30 games and 158 tasks. Surprisingly, despite training solely on game data, VLMs demonstrated out of domain generalization, specifically Qwen2.5-VL-7B improving performance by 2.33\% across 7 diverse vision-language benchmarks. Our code and dataset are available at https://github.com/tongjingqi/Code2Logic.
Route Sparse Autoencoder to Interpret Large Language Models
Mar 11, 2025Mechanistic interpretability of large language models (LLMs) aims to uncover the internal processes of information propagation and reasoning. Sparse autoencoders (SAEs) have demonstrated promise in this domain by extracting interpretable and monosemantic features. However, prior works primarily focus on feature extraction from a single layer, failing to effectively capture activations that span multiple layers. In this paper, we introduce Route Sparse Autoencoder (RouteSAE), a new framework that integrates a routing mechanism with a shared SAE to efficiently extract features from multiple layers. It dynamically assigns weights to activations from different layers, incurring minimal parameter overhead while achieving high interpretability and flexibility for targeted feature manipulation. We evaluate RouteSAE through extensive experiments on Llama-3.2-1B-Instruct. Specifically, under the same sparsity constraint of 64, RouteSAE extracts 22.5% more features than baseline SAEs while achieving a 22.3% higher interpretability score. These results underscore the potential of RouteSAE as a scalable and effective method for LLM interpretability, with applications in feature discovery and model intervention. Our codes are available at https://github.com/swei2001/RouteSAEs.
PFDial: A Structured Dialogue Instruction Fine-tuning Method Based on UML Flowcharts
Mar 09, 2025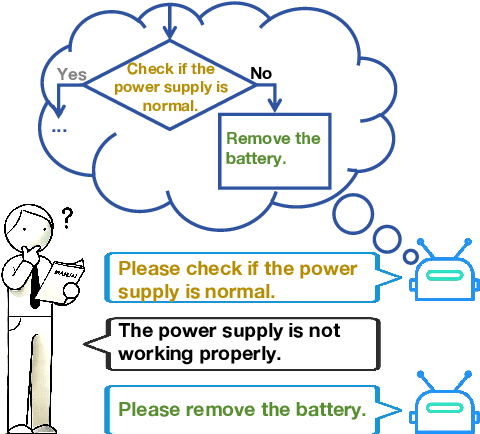
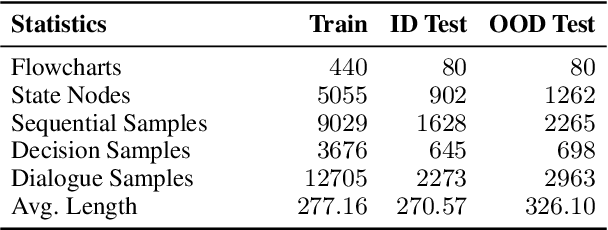
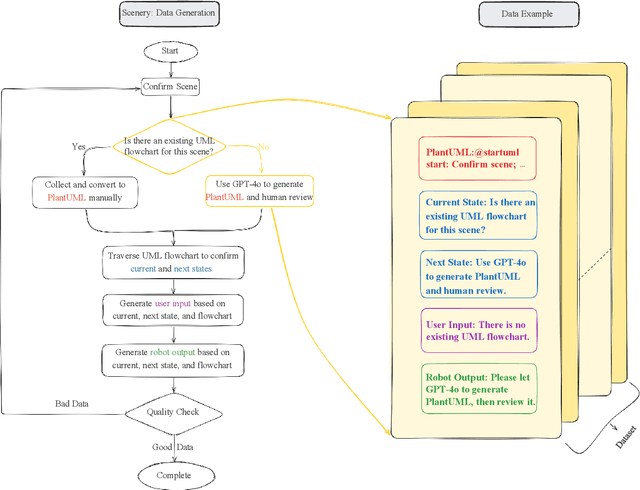
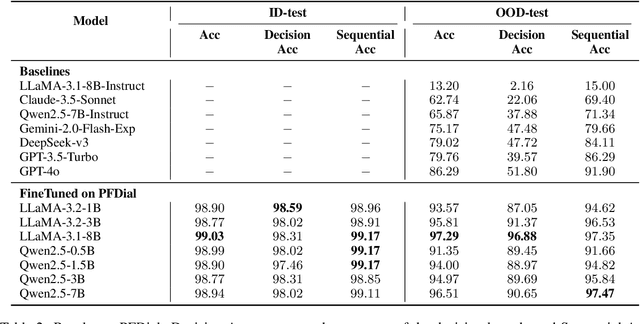
Process-driven dialogue systems, which operate under strict predefined process constraints, are essential in customer service and equipment maintenance scenarios. Although Large Language Models (LLMs) have shown remarkable progress in dialogue and reasoning, they still struggle to solve these strictly constrained dialogue tasks. To address this challenge, we construct Process Flow Dialogue (PFDial) dataset, which contains 12,705 high-quality Chinese dialogue instructions derived from 440 flowcharts containing 5,055 process nodes. Based on PlantUML specification, each UML flowchart is converted into atomic dialogue units i.e., structured five-tuples. Experimental results demonstrate that a 7B model trained with merely 800 samples, and a 0.5B model trained on total data both can surpass 90% accuracy. Additionally, the 8B model can surpass GPT-4o up to 43.88% with an average of 11.00%. We further evaluate models' performance on challenging backward transitions in process flows and conduct an in-depth analysis of various dataset formats to reveal their impact on model performance in handling decision and sequential branches. The data is released in https://github.com/KongLongGeFDU/PFDial.
AnyEdit: Edit Any Knowledge Encoded in Language Models
Feb 08, 2025



Large language models (LLMs) often produce incorrect or outdated information, necessitating efficient and precise knowledge updates. Current model editing methods, however, struggle with long-form knowledge in diverse formats, such as poetry, code snippets, and mathematical derivations. These limitations arise from their reliance on editing a single token's hidden state, a limitation we term "efficacy barrier". To solve this, we propose AnyEdit, a new autoregressive editing paradigm. It decomposes long-form knowledge into sequential chunks and iteratively edits the key token in each chunk, ensuring consistent and accurate outputs. Theoretically, we ground AnyEdit in the Chain Rule of Mutual Information, showing its ability to update any knowledge within LLMs. Empirically, it outperforms strong baselines by 21.5% on benchmarks including UnKEBench, AKEW, and our new EditEverything dataset for long-form diverse-formatted knowledge. Additionally, AnyEdit serves as a plug-and-play framework, enabling current editing methods to update knowledge with arbitrary length and format, significantly advancing the scope and practicality of LLM knowledge editing.
Predicting Large Language Model Capabilities on Closed-Book QA Tasks Using Only Information Available Prior to Training
Feb 06, 2025The GPT-4 technical report from OpenAI suggests that model performance on specific tasks can be predicted prior to training, though methodologies remain unspecified. This approach is crucial for optimizing resource allocation and ensuring data alignment with target tasks. To achieve this vision, we focus on predicting performance on Closed-book Question Answering (CBQA) tasks, which are closely tied to pre-training data and knowledge retention. We address three major challenges: 1) mastering the entire pre-training process, especially data construction; 2) evaluating a model's knowledge retention; and 3) predicting task-specific knowledge retention using only information available prior to training. To tackle these challenges, we pre-train three large language models (i.e., 1.6B, 7B, and 13B) using 560k dollars and 520k GPU hours. We analyze the pre-training data with knowledge triples and assess knowledge retention using established methods. Additionally, we introduce the SMI metric, an information-theoretic measure that quantifies the relationship between pre-training data, model size, and task-specific knowledge retention. Our experiments reveal a strong linear correlation ($\text{R}^2 > 0.84$) between the SMI metric and the model's accuracy on CBQA tasks across models of varying sizes (i.e., 1.1B, 1.6B, 7B, and 13B). The dataset, model, and code are available at https://github.com/yuhui1038/SMI.
EigenSR: Eigenimage-Bridged Pre-Trained RGB Learners for Single Hyperspectral Image Super-Resolution
Sep 06, 2024



Single hyperspectral image super-resolution (single-HSI-SR) aims to improve the resolution of a single input low-resolution HSI. Due to the bottleneck of data scarcity, the development of single-HSI-SR lags far behind that of RGB natural images. In recent years, research on RGB SR has shown that models pre-trained on large-scale benchmark datasets can greatly improve performance on unseen data, which may stand as a remedy for HSI. But how can we transfer the pre-trained RGB model to HSI, to overcome the data-scarcity bottleneck? Because of the significant difference in the channels between the pre-trained RGB model and the HSI, the model cannot focus on the correlation along the spectral dimension, thus limiting its ability to utilize on HSI. Inspired by the HSI spatial-spectral decoupling, we propose a new framework that first fine-tunes the pre-trained model with the spatial components (known as eigenimages), and then infers on unseen HSI using an iterative spectral regularization (ISR) to maintain the spectral correlation. The advantages of our method lie in: 1) we effectively inject the spatial texture processing capabilities of the pre-trained RGB model into HSI while keeping spectral fidelity, 2) learning in the spectral-decorrelated domain can improve the generalizability to spectral-agnostic data, and 3) our inference in the eigenimage domain naturally exploits the spectral low-rank property of HSI, thereby reducing the complexity. This work bridges the gap between pre-trained RGB models and HSI via eigenimages, addressing the issue of limited HSI training data, hence the name EigenSR. Extensive experiments show that EigenSR outperforms the state-of-the-art (SOTA) methods in both spatial and spectral metrics. Our code will be released.
Modeling Techniques for Machine Learning Fairness: A Survey
Nov 04, 2021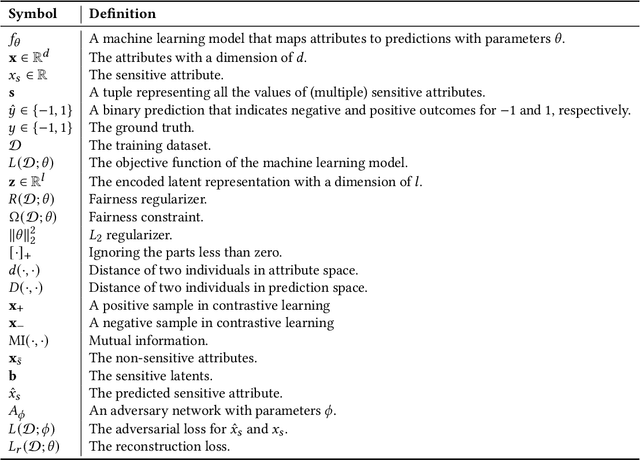
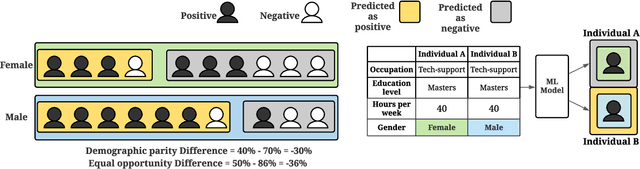
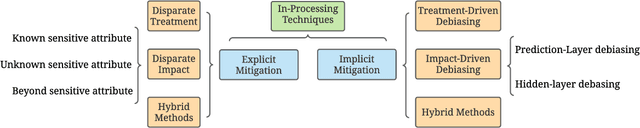
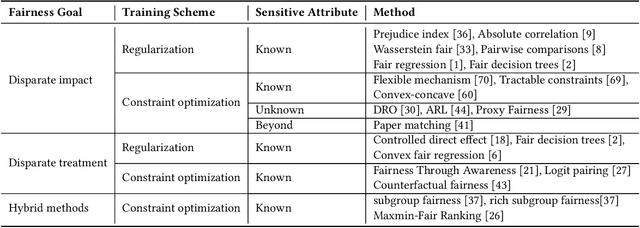
Machine learning models are becoming pervasive in high-stakes applications. Despite their clear benefits in terms of performance, the models could show bias against minority groups and result in fairness issues in a decision-making process, leading to severe negative impacts on the individuals and the society. In recent years, various techniques have been developed to mitigate the bias for machine learning models. Among them, in-processing methods have drawn increasing attention from the community, where fairness is directly taken into consideration during model design to induce intrinsically fair models and fundamentally mitigate fairness issues in outputs and representations. In this survey, we review the current progress of in-processing bias mitigation techniques. Based on where the fairness is achieved in the model, we categorize them into explicit and implicit methods, where the former directly incorporates fairness metrics in training objectives, and the latter focuses on refining latent representation learning. Finally, we conclude the survey with a discussion of the research challenges in this community to motivate future exploration.
Meta-AAD: Active Anomaly Detection with Deep Reinforcement Learning
Sep 16, 2020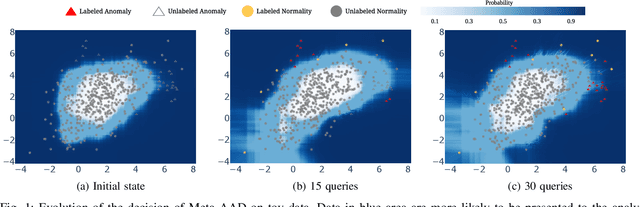
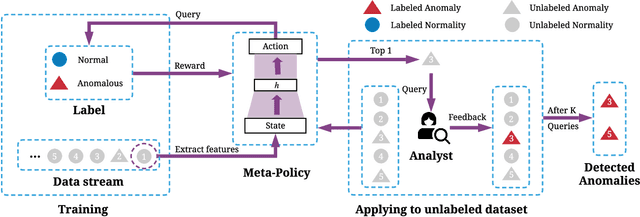
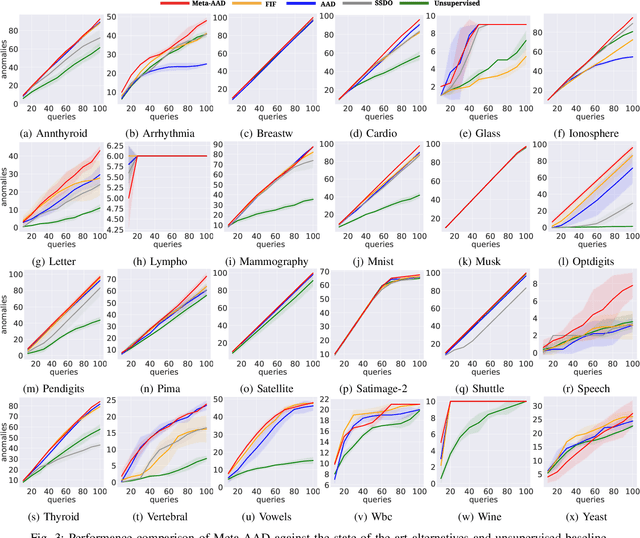
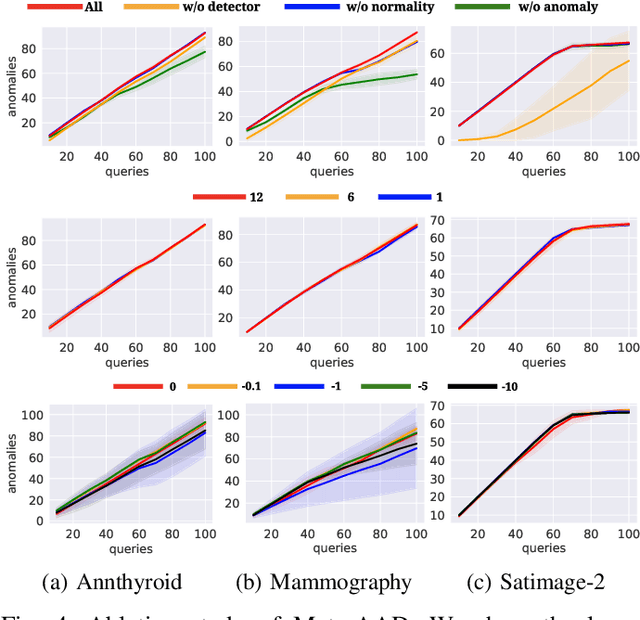
High false-positive rate is a long-standing challenge for anomaly detection algorithms, especially in high-stake applications. To identify the true anomalies, in practice, analysts or domain experts will be employed to investigate the top instances one by one in a ranked list of anomalies identified by an anomaly detection system. This verification procedure generates informative labels that can be leveraged to re-rank the anomalies so as to help the analyst to discover more true anomalies given a time budget. Some re-ranking strategies have been proposed to approximate the above sequential decision process. Specifically, existing strategies have been focused on making the top instances more likely to be anomalous based on the feedback. Then they greedily select the top-1 instance for query. However, these greedy strategies could be sub-optimal since some low-ranked instances could be more helpful in the long-term. In this work, we propose Active Anomaly Detection with Meta-Policy (Meta-AAD), a novel framework that learns a meta-policy for query selection. Specifically, Meta-AAD leverages deep reinforcement learning to train the meta-policy to select the most proper instance to explicitly optimize the number of discovered anomalies throughout the querying process. Meta-AAD is easy to deploy since a trained meta-policy can be directly applied to any new datasets without further tuning. Extensive experiments on 24 benchmark datasets demonstrate that Meta-AAD significantly outperforms the state-of-the-art re-ranking strategies and the unsupervised baseline. The empirical analysis shows that the trained meta-policy is transferable and inherently achieves a balance between long-term and short-term rewards.