 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Unregistered Hyperspectral Image Super-Resolution via Unmixing-based Abundance Fusion Learning
Mar 09, 2026Unregistered hyperspectral image (HSI) super-resolution (SR) typically aims to enhance a low-resolution HSI using an unregistered high-resolution reference image. In this paper, we propose an unmixing-based fusion framework that decouples spatial-spectral information to simultaneously mitigate the impact of unregistered fusion and enhance the learnability of SR models. Specifically, we first utilize singular value decomposition for initial spectral unmixing, preserving the original endmembers while dedicating the subsequent network to enhancing the initial abundance map. To leverage the spatial texture of the unregistered reference, we introduce a coarse-to-fine deformable aggregation module, which first estimates a pixel-level flow and a similarity map using a coarse pyramid predictor. It further performs fine sub-pixel refinement to achieve deformable aggregation of the reference features. The aggregative features are then refined via a series of spatial-channel abundance cross-attention blocks. Furthermore, a spatial-channel modulated fusion module is presented to merge encoder-decoder features using dynamic gating weights, yielding a high-quality, high-resolution HSI. Experimental results on simulated and real datasets confirm that our proposed method achieves state-of-the-art super-resolution performance. The code will be available at https://github.com/yingkai-zhang/UAFL.
SNNSIR: A Simple Spiking Neural Network for Stereo Image Restoration
Aug 17, 2025Spiking Neural Networks (SNNs), characterized by discrete binary activations, offer high computational efficiency and low energy consumption, making them well-suited for computation-intensive tasks such as stereo image restoration. In this work, we propose SNNSIR, a simple yet effective Spiking Neural Network for Stereo Image Restoration, specifically designed under the spike-driven paradigm where neurons transmit information through sparse, event-based binary spikes. In contrast to existing hybrid SNN-ANN models that still rely on operations such as floating-point matrix division or exponentiation, which are incompatible with the binary and event-driven nature of SNNs, our proposed SNNSIR adopts a fully spike-driven architecture to achieve low-power and hardware-friendly computation. To address the expressiveness limitations of binary spiking neurons, we first introduce a lightweight Spike Residual Basic Block (SRBB) to enhance information flow via spike-compatible residual learning. Building on this, the Spike Stereo Convolutional Modulation (SSCM) module introduces simplified nonlinearity through element-wise multiplication and highlights noise-sensitive regions via cross-view-aware modulation. Complementing this, the Spike Stereo Cross-Attention (SSCA) module further improves stereo correspondence by enabling efficient bidirectional feature interaction across views within a spike-compatible framework. Extensive experiments on diverse stereo image restoration tasks, including rain streak removal, raindrop removal, low-light enhancement, and super-resolution demonstrate that our model achieves competitive restoration performance while significantly reducing computational overhead. These results highlight the potential for real-time, low-power stereo vision applications. The code will be available after the article is accepted.
MAFE R-CNN: Selecting More Samples to Learn Category-aware Features for Small Object Detection
May 22, 2025Small object detection in intricate environments has consistently represented a major challenge in the field of object detection. In this paper, we identify that this difficulty stems from the detectors' inability to effectively learn discriminative features for objects of small size, compounded by the complexity of selecting high-quality small object samples during training, which motivates the proposal of the Multi-Clue Assignment and Feature Enhancement R-CNN.Specifically, MAFE R-CNN integrates two pivotal components.The first is the Multi-Clue Sample Selection (MCSS) strategy, in which the Intersection over Union (IoU) distance, predicted category confidence, and ground truth region sizes are leveraged as informative clues in the sample selection process. This methodology facilitates the selection of diverse positive samples and ensures a balanced distribution of object sizes during training, thereby promoting effective model learning.The second is the Category-aware Feature Enhancement Mechanism (CFEM), where we propose a simple yet effective category-aware memory module to explore the relationships among object features. Subsequently, we enhance the object feature representation by facilitating the interaction between category-aware features and candidate box features.Comprehensive experiments conducted on the large-scale small object dataset SODA validate the effectiveness of the proposed method. The code will be made publicly available.
SSLFusion: Scale & Space Aligned Latent Fusion Model for Multimodal 3D Object Detection
Apr 07, 2025



Multimodal 3D object detection based on deep neural networks has indeed made significant progress. However, it still faces challenges due to the misalignment of scale and spatial information between features extracted from 2D images and those derived from 3D point clouds. Existing methods usually aggregate multimodal features at a single stage. However, leveraging multi-stage cross-modal features is crucial for detecting objects of various scales. Therefore, these methods often struggle to integrate features across different scales and modalities effectively, thereby restricting the accuracy of detection. Additionally, the time-consuming Query-Key-Value-based (QKV-based) cross-attention operations often utilized in existing methods aid in reasoning the location and existence of objects by capturing non-local contexts. However, this approach tends to increase computational complexity. To address these challenges, we present SSLFusion, a novel Scale & Space Aligned Latent Fusion Model, consisting of a scale-aligned fusion strategy (SAF), a 3D-to-2D space alignment module (SAM), and a latent cross-modal fusion module (LFM). SAF mitigates scale misalignment between modalities by aggregating features from both images and point clouds across multiple levels. SAM is designed to reduce the inter-modal gap between features from images and point clouds by incorporating 3D coordinate information into 2D image features. Additionally, LFM captures cross-modal non-local contexts in the latent space without utilizing the QKV-based attention operations, thus mitigating computational complexity. Experiments on the KITTI and DENSE datasets demonstrate that our SSLFusion outperforms state-of-the-art methods. Our approach obtains an absolute gain of 2.15% in 3D AP, compared with the state-of-art method GraphAlign on the moderate level of the KITTI test set.
Progressive Fine-to-Coarse Reconstruction for Accurate Low-Bit Post-Training Quantization in Vision Transformers
Dec 19, 2024



Due to its efficiency, Post-Training Quantization (PTQ) has been widely adopted for compressing Vision Transformers (ViTs). However, when quantized into low-bit representations, there is often a significant performance drop compared to their full-precision counterparts. To address this issue, reconstruction methods have been incorporated into the PTQ framework to improve performance in low-bit quantization settings. Nevertheless, existing related methods predefine the reconstruction granularity and seldom explore the progressive relationships between different reconstruction granularities, which leads to sub-optimal quantization results in ViTs. To this end, in this paper, we propose a Progressive Fine-to-Coarse Reconstruction (PFCR) method for accurate PTQ, which significantly improves the performance of low-bit quantized vision transformers. Specifically, we define multi-head self-attention and multi-layer perceptron modules along with their shortcuts as the finest reconstruction units. After reconstructing these two fine-grained units, we combine them to form coarser blocks and reconstruct them at a coarser granularity level. We iteratively perform this combination and reconstruction process, achieving progressive fine-to-coarse reconstruction. Additionally, we introduce a Progressive Optimization Strategy (POS) for PFCR to alleviate the difficulty of training, thereby further enhancing model performance. Experimental results on the ImageNet dataset demonstrate that our proposed method achieves the best Top-1 accuracy among state-of-the-art methods, particularly attaining 75.61% for 3-bit quantized ViT-B in PTQ. Besides, quantization results on the COCO dataset reveal the effectiveness and generalization of our proposed method on other computer vision tasks like object detection and instance segmentation.
EigenSR: Eigenimage-Bridged Pre-Trained RGB Learners for Single Hyperspectral Image Super-Resolution
Sep 06, 2024



Single hyperspectral image super-resolution (single-HSI-SR) aims to improve the resolution of a single input low-resolution HSI. Due to the bottleneck of data scarcity, the development of single-HSI-SR lags far behind that of RGB natural images. In recent years, research on RGB SR has shown that models pre-trained on large-scale benchmark datasets can greatly improve performance on unseen data, which may stand as a remedy for HSI. But how can we transfer the pre-trained RGB model to HSI, to overcome the data-scarcity bottleneck? Because of the significant difference in the channels between the pre-trained RGB model and the HSI, the model cannot focus on the correlation along the spectral dimension, thus limiting its ability to utilize on HSI. Inspired by the HSI spatial-spectral decoupling, we propose a new framework that first fine-tunes the pre-trained model with the spatial components (known as eigenimages), and then infers on unseen HSI using an iterative spectral regularization (ISR) to maintain the spectral correlation. The advantages of our method lie in: 1) we effectively inject the spatial texture processing capabilities of the pre-trained RGB model into HSI while keeping spectral fidelity, 2) learning in the spectral-decorrelated domain can improve the generalizability to spectral-agnostic data, and 3) our inference in the eigenimage domain naturally exploits the spectral low-rank property of HSI, thereby reducing the complexity. This work bridges the gap between pre-trained RGB models and HSI via eigenimages, addressing the issue of limited HSI training data, hence the name EigenSR. Extensive experiments show that EigenSR outperforms the state-of-the-art (SOTA) methods in both spatial and spectral metrics. Our code will be released.
VFMM3D: Releasing the Potential of Image by Vision Foundation Model for Monocular 3D Object Detection
Apr 15, 2024



Due to its cost-effectiveness and widespread availability, monocular 3D object detection, which relies solely on a single camera during inference, holds significant importance across various applications, including autonomous driving and robotics. Nevertheless, directly predicting the coordinates of objects in 3D space from monocular images poses challenges. Therefore, an effective solution involves transforming monocular images into LiDAR-like representations and employing a LiDAR-based 3D object detector to predict the 3D coordinates of objects. The key step in this method is accurately converting the monocular image into a reliable point cloud form. In this paper, we present VFMM3D, an innovative approach that leverages the capabilities of Vision Foundation Models (VFMs) to accurately transform single-view images into LiDAR point cloud representations. VFMM3D utilizes the Segment Anything Model (SAM) and Depth Anything Model (DAM) to generate high-quality pseudo-LiDAR data enriched with rich foreground information. Specifically, the Depth Anything Model (DAM) is employed to generate dense depth maps. Subsequently, the Segment Anything Model (SAM) is utilized to differentiate foreground and background regions by predicting instance masks. These predicted instance masks and depth maps are then combined and projected into 3D space to generate pseudo-LiDAR points. Finally, any object detectors based on point clouds can be utilized to predict the 3D coordinates of objects. Comprehensive experiments are conducted on the challenging 3D object detection dataset KITTI. Our VFMM3D establishes a new state-of-the-art performance. Additionally, experimental results demonstrate the generality of VFMM3D, showcasing its seamless integration into various LiDAR-based 3D object detectors.
TencentLLMEval: A Hierarchical Evaluation of Real-World Capabilities for Human-Aligned LLMs
Nov 09, 2023



Large language models (LLMs) have shown impressive capabilities across various natural language tasks. However, evaluating their alignment with human preferences remains a challenge. To this end, we propose a comprehensive human evaluation framework to assess LLMs' proficiency in following instructions on diverse real-world tasks. We construct a hierarchical task tree encompassing 7 major areas covering over 200 categories and over 800 tasks, which covers diverse capabilities such as question answering, reasoning, multiturn dialogue, and text generation, to evaluate LLMs in a comprehensive and in-depth manner. We also design detailed evaluation standards and processes to facilitate consistent, unbiased judgments from human evaluators. A test set of over 3,000 instances is released, spanning different difficulty levels and knowledge domains. Our work provides a standardized methodology to evaluate human alignment in LLMs for both English and Chinese. We also analyze the feasibility of automating parts of evaluation with a strong LLM (GPT-4). Our framework supports a thorough assessment of LLMs as they are integrated into real-world applications. We have made publicly available the task tree, TencentLLMEval dataset, and evaluation methodology which have been demonstrated as effective in assessing the performance of Tencent Hunyuan LLMs. By doing so, we aim to facilitate the benchmarking of advances in the development of safe and human-aligned LLMs.
EGFN: Efficient Geometry Feature Network for Fast Stereo 3D Object Detection
Nov 28, 2021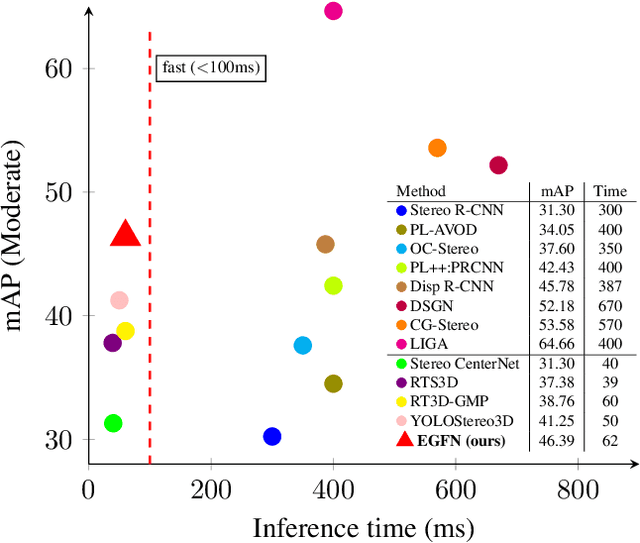
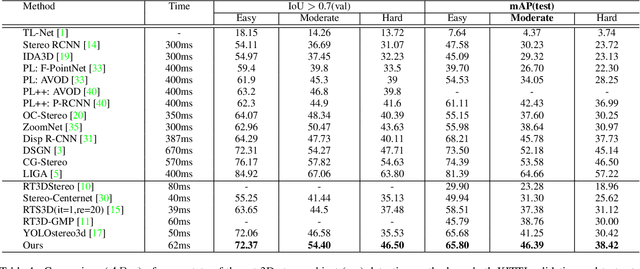
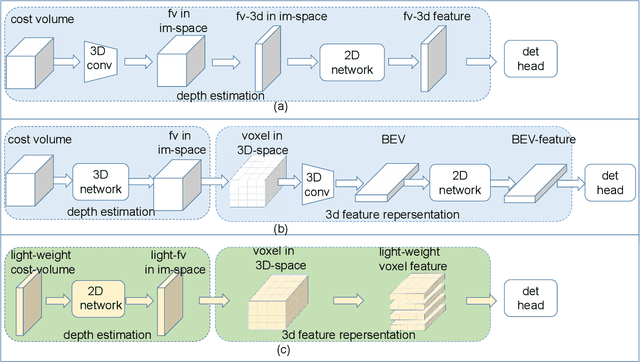
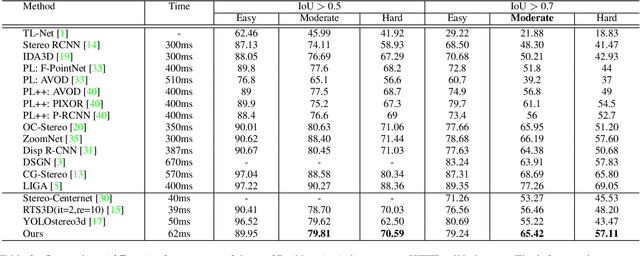
Fast stereo based 3D object detectors have made great progress in the sense of inference time recently. However, they lag far behind high-precision oriented methods in accuracy. We argue that the main reason is the missing or poor 3D geometry feature representation in fast stereo based methods. To solve this problem, we propose an efficient geometry feature generation network (EGFN). The key of our EGFN is an efficient and effective 3D geometry feature representation (EGFR) module. In the EGFR module, light-weight cost volume features are firstly generated, then are efficiently converted into 3D space, and finally multi-scale features enhancement in in both image and 3D spaces is conducted to obtain the 3D geometry features: enhanced light-weight voxel features. In addition, we introduce a novel multi-scale knowledge distillation strategy to guide multi-scale 3D geometry features learning. Experimental results on the public KITTI test set shows that the proposed EGFN outperforms YOLOStsereo3D, the advanced fast method, by 5.16\% on mAP$_{3d}$ at the cost of merely additional 12 ms and hence achieves a better trade-off between accuracy and efficiency for stereo 3D object detection. Our code will be publicly available.
A Hierarchical Location Normalization System for Text
Jan 21, 2020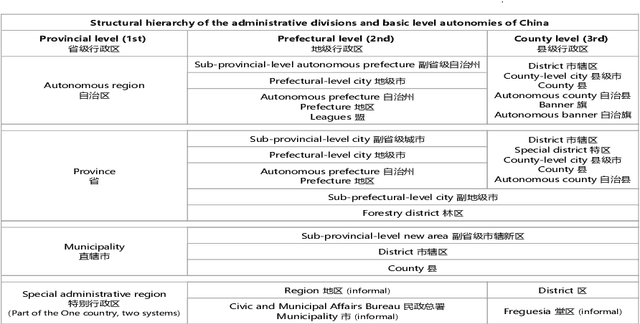
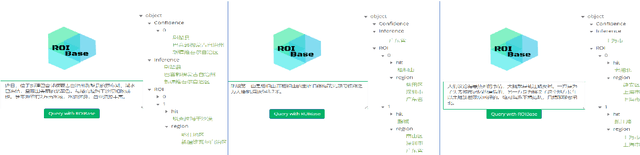
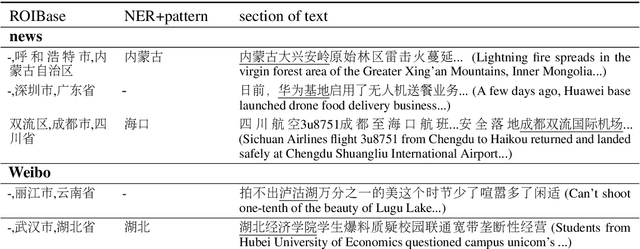
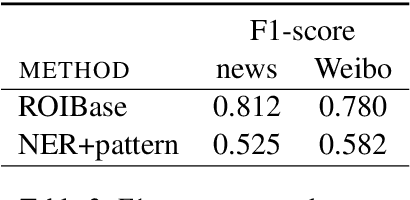
It's natural these days for people to know the local events from massive documents. Many texts contain location information, such as city name or road name, which is always incomplete or latent. It's significant to extract the administrative area of the text and organize the hierarchy of area, called location normalization. Existing detecting location systems either exclude hierarchical normalization or present only a few specific regions. We propose a system named ROIBase that normalizes the text by the Chinese hierarchical administrative divisions. ROIBase adopts a co-occurrence constraint as the basic framework to score the hit of the administrative area, achieves the inference by special embeddings, and expands the recall by the ROI (region of interest). It has high efficiency and interpretability because it mainly establishes on the definite knowledge and has less complex logic than the supervised models. We demonstrate that ROIBase achieves better performance against feasible solutions and is useful as a strong support system for location normalization.