 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Knowledge-Enhanced Contextual Language Representations for Domain Natural Language Understanding
Nov 12, 2023Knowledge-Enhanced Pre-trained Language Models (KEPLMs) improve the performance of various downstream NLP tasks by injecting knowledge facts from large-scale Knowledge Graphs (KGs). However, existing methods for pre-training KEPLMs with relational triples are difficult to be adapted to close domains due to the lack of sufficient domain graph semantics. In this paper, we propose a Knowledge-enhanced lANGuAge Representation learning framework for various clOsed dOmains (KANGAROO) via capturing the implicit graph structure among the entities. Specifically, since the entity coverage rates of closed-domain KGs can be relatively low and may exhibit the global sparsity phenomenon for knowledge injection, we consider not only the shallow relational representations of triples but also the hyperbolic embeddings of deep hierarchical entity-class structures for effective knowledge fusion.Moreover, as two closed-domain entities under the same entity-class often have locally dense neighbor subgraphs counted by max point biconnected component, we further propose a data augmentation strategy based on contrastive learning over subgraphs to construct hard negative samples of higher quality. It makes the underlying KELPMs better distinguish the semantics of these neighboring entities to further complement the global semantic sparsity. In the experiments, we evaluate KANGAROO over various knowledge-aware and general NLP tasks in both full and few-shot learning settings, outperforming various KEPLM training paradigms performance in closed-domains significantly.
FashionLOGO: Prompting Multimodal Large Language Models for Fashion Logo Embeddings
Aug 17, 2023Logo embedding plays a crucial role in various e-commerce applications by facilitating image retrieval or recognition, such as intellectual property protection and product search. However, current methods treat logo embedding as a purely visual problem, which may limit their performance in real-world scenarios. A notable issue is that the textual knowledge embedded in logo images has not been adequately explored. Therefore, we propose a novel approach that leverages textual knowledge as an auxiliary to improve the robustness of logo embedding. The emerging Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in both visual and textual understanding and could become valuable visual assistants in understanding logo images. Inspired by this observation, our proposed method, FashionLOGO, aims to utilize MLLMs to enhance fashion logo embedding. We explore how MLLMs can improve logo embedding by prompting them to generate explicit textual knowledge through three types of prompts, including image OCR, brief captions, and detailed descriptions prompts, in a zero-shot setting. We adopt a cross-attention transformer to enable image embedding queries to learn supplementary knowledge from textual embeddings automatically. To reduce computational costs, we only use the image embedding model in the inference stage, similar to traditional inference pipelines. Our extensive experiments on three real-world datasets demonstrate that FashionLOGO learns generalized and robust logo embeddings, achieving state-of-the-art performance in all benchmark datasets. Furthermore, we conduct comprehensive ablation studies to demonstrate the performance improvements resulting from the introduction of MLLMs.
Valley: Video Assistant with Large Language model Enhanced abilitY
Jun 12, 2023Recently, several multi-modal models have been developed for joint image and language understanding, which have demonstrated impressive chat abilities by utilizing advanced large language models (LLMs). The process of developing such models is straightforward yet effective. It involves pre-training an adaptation module to align the semantics of the vision encoder and language model, followed by fine-tuning on the instruction-following data. However, despite the success of this pipeline in image and language understanding, its effectiveness in joint video and language understanding has not been widely explored. In this paper, we aim to develop a novel multi-modal foundation model capable of perceiving video, image, and language within a general framework. To achieve this goal, we introduce Valley: Video Assistant with Large Language model Enhanced ability. Specifically, our proposed Valley model is designed with a simple projection module that bridges video, image, and language modalities, and is further unified with a multi-lingual LLM. We also collect multi-source vision-text pairs and adopt a spatio-temporal pooling strategy to obtain a unified vision encoding of video and image input for pre-training. Furthermore, we generate multi-task instruction-following video data, including multi-shot captions, long video descriptions, action recognition, causal relationship inference, etc. To obtain the instruction-following data, we design diverse rounds of task-oriented conversations between humans and videos, facilitated by ChatGPT. Qualitative examples demonstrate that our proposed model has the potential to function as a highly effective multilingual video assistant that can make complex video understanding scenarios easy. Code, data, and models will be available at https://github.com/RupertLuo/Valley.
Meta-Learning Siamese Network for Few-Shot Text Classification
Feb 05, 2023



Few-shot learning has been used to tackle the problem of label scarcity in text classification, of which meta-learning based methods have shown to be effective, such as the prototypical networks (PROTO). Despite the success of PROTO, there still exist three main problems: (1) ignore the randomness of the sampled support sets when computing prototype vectors; (2) disregard the importance of labeled samples; (3) construct meta-tasks in a purely random manner. In this paper, we propose a Meta-Learning Siamese Network, namely, Meta-SN, to address these issues. Specifically, instead of computing prototype vectors from the sampled support sets, Meta-SN utilizes external knowledge (e.g. class names and descriptive texts) for class labels, which is encoded as the low-dimensional embeddings of prototype vectors. In addition, Meta-SN presents a novel sampling strategy for constructing meta-tasks, which gives higher sampling probabilities to hard-to-classify samples. Extensive experiments are conducted on six benchmark datasets to show the clear superiority of Meta-SN over other state-of-the-art models. For reproducibility, all the datasets and codes are provided at https://github.com/hccngu/Meta-SN.
SpanProto: A Two-stage Span-based Prototypical Network for Few-shot Named Entity Recognition
Oct 17, 2022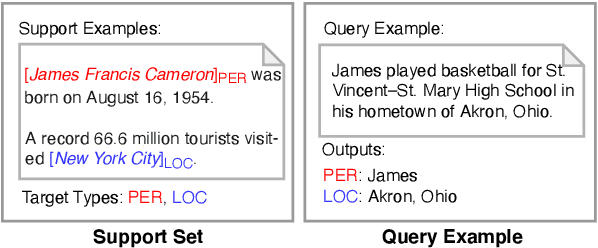
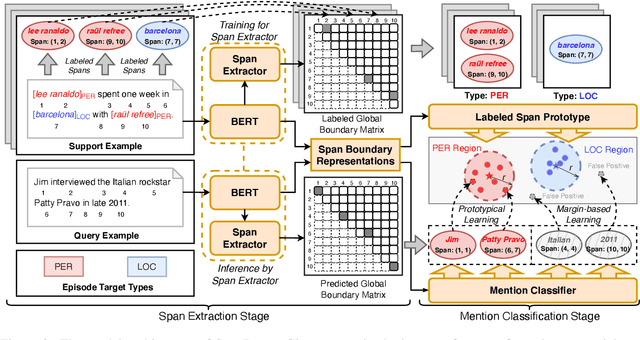
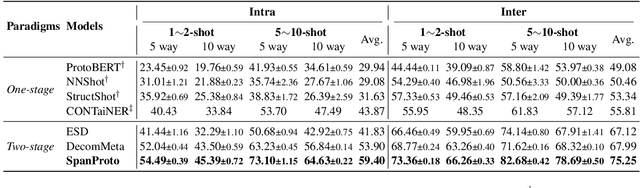
Few-shot Named Entity Recognition (NER) aims to identify named entities with very little annotated data. Previous methods solve this problem based on token-wise classification, which ignores the information of entity boundaries, and inevitably the performance is affected by the massive non-entity tokens. To this end, we propose a seminal span-based prototypical network (SpanProto) that tackles few-shot NER via a two-stage approach, including span extraction and mention classification. In the span extraction stage, we transform the sequential tags into a global boundary matrix, enabling the model to focus on the explicit boundary information. For mention classification, we leverage prototypical learning to capture the semantic representations for each labeled span and make the model better adapt to novel-class entities. To further improve the model performance, we split out the false positives generated by the span extractor but not labeled in the current episode set, and then present a margin-based loss to separate them from each prototype region. Experiments over multiple benchmarks demonstrate that our model outperforms strong baselines by a large margin.
Knowledge Prompting in Pre-trained Language Model for Natural Language Understanding
Oct 16, 2022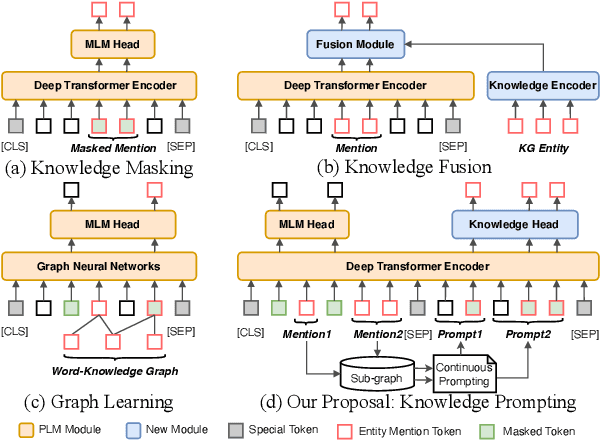
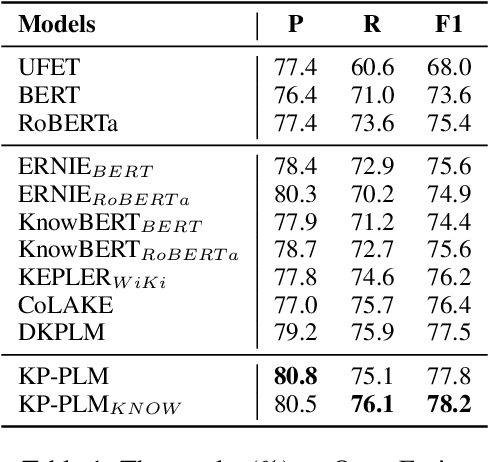
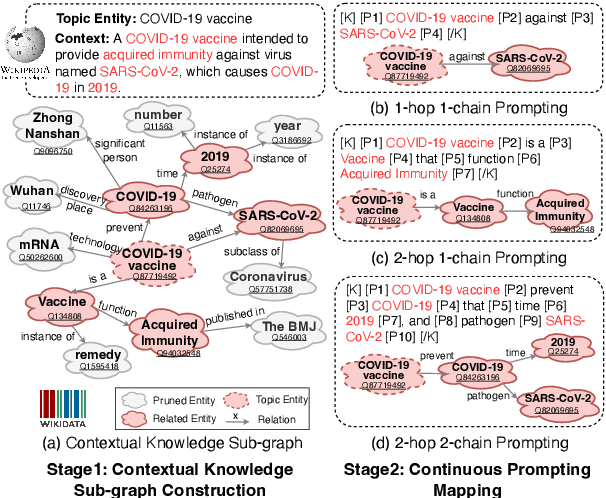
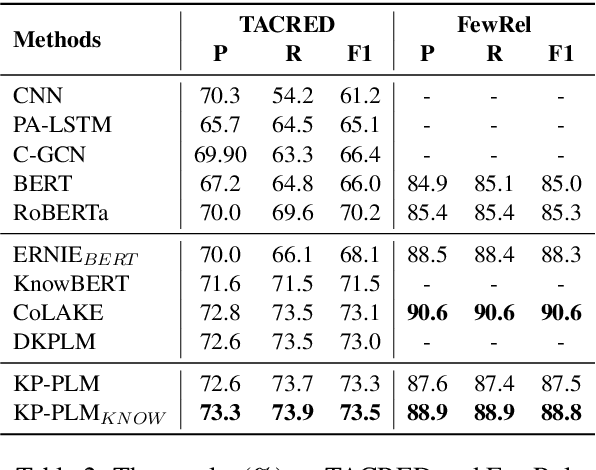
Knowledge-enhanced Pre-trained Language Model (PLM) has recently received significant attention, which aims to incorporate factual knowledge into PLMs. However, most existing methods modify the internal structures of fixed types of PLMs by stacking complicated modules, and introduce redundant and irrelevant factual knowledge from knowledge bases (KBs). In this paper, to address these problems, we introduce a seminal knowledge prompting paradigm and further propose a knowledge-prompting-based PLM framework KP-PLM. This framework can be flexibly combined with existing mainstream PLMs. Specifically, we first construct a knowledge sub-graph from KBs for each context. Then we design multiple continuous prompts rules and transform the knowledge sub-graph into natural language prompts. To further leverage the factual knowledge from these prompts, we propose two novel knowledge-aware self-supervised tasks including prompt relevance inspection and masked prompt modeling. Extensive experiments on multiple natural language understanding (NLU) tasks show the superiority of KP-PLM over other state-of-the-art methods in both full-resource and low-resource settings.
Towards Unified Prompt Tuning for Few-shot Text Classification
May 11, 2022
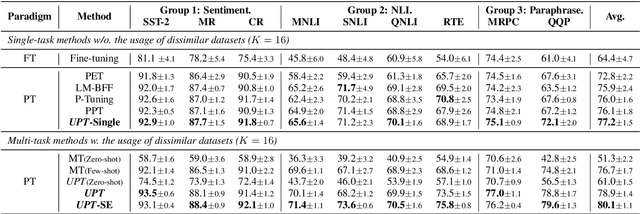
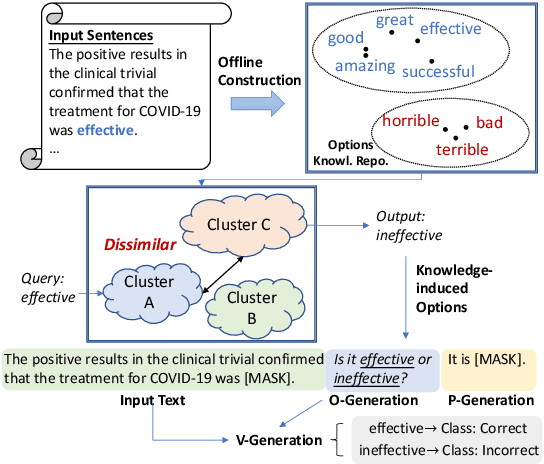
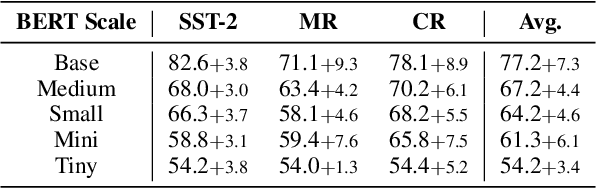
Prompt-based fine-tuning has boosted the performance of Pre-trained Language Models (PLMs) on few-shot text classification by employing task-specific prompts. Yet, PLMs are unfamiliar with prompt-style expressions during pre-training, which limits the few-shot learning performance on downstream tasks. It would be desirable if the models can acquire some prompting knowledge before adaptation to specific NLP tasks. We present the Unified Prompt Tuning (UPT) framework, leading to better few-shot text classification for BERT-style models by explicitly capturing prompting semantics from non-target NLP datasets. In UPT, a novel paradigm Prompt-Options-Verbalizer is proposed for joint prompt learning across different NLP tasks, forcing PLMs to capture task-invariant prompting knowledge. We further design a self-supervised task named Knowledge-enhanced Selective Masked Language Modeling to improve the PLM's generalization abilities for accurate adaptation to previously unseen tasks. After multi-task learning across multiple tasks, the PLM can be better prompt-tuned towards any dissimilar target tasks in low-resourced settings. Experiments over a variety of NLP tasks show that UPT consistently outperforms state-of-the-arts for prompt-based fine-tuning.
KECP: Knowledge Enhanced Contrastive Prompting for Few-shot Extractive Question Answering
May 06, 2022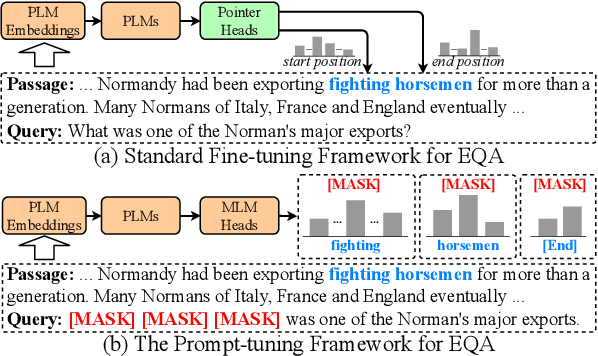
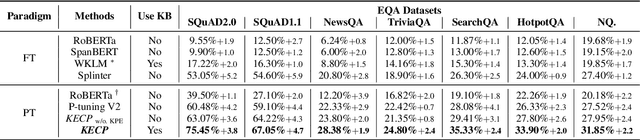
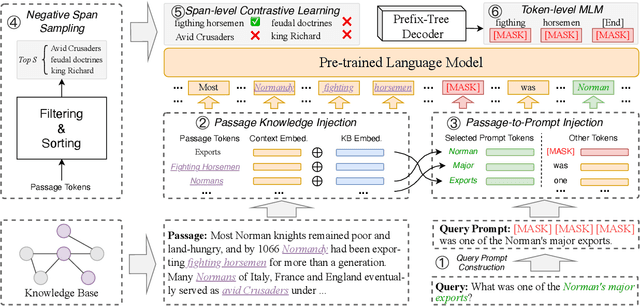
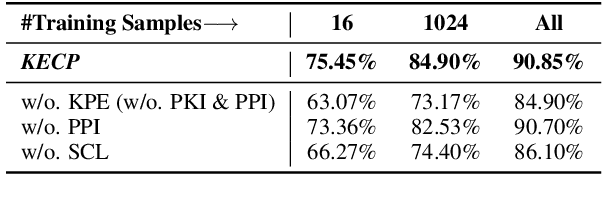
Extractive Question Answering (EQA) is one of the most important tasks in Machine Reading Comprehension (MRC), which can be solved by fine-tuning the span selecting heads of Pre-trained Language Models (PLMs). However, most existing approaches for MRC may perform poorly in the few-shot learning scenario. To solve this issue, we propose a novel framework named Knowledge Enhanced Contrastive Prompt-tuning (KECP). Instead of adding pointer heads to PLMs, we introduce a seminal paradigm for EQA that transform the task into a non-autoregressive Masked Language Modeling (MLM) generation problem. Simultaneously, rich semantics from the external knowledge base (KB) and the passage context are support for enhancing the representations of the query. In addition, to boost the performance of PLMs, we jointly train the model by the MLM and contrastive learning objectives. Experiments on multiple benchmarks demonstrate that our method consistently outperforms state-of-the-art approaches in few-shot settings by a large margin.
EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing
Apr 30, 2022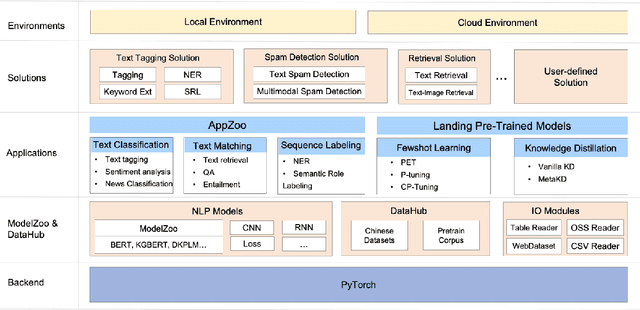
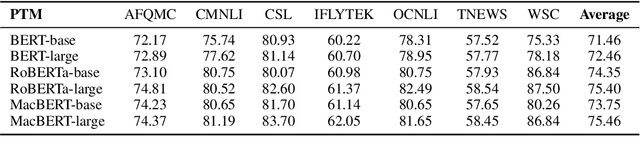
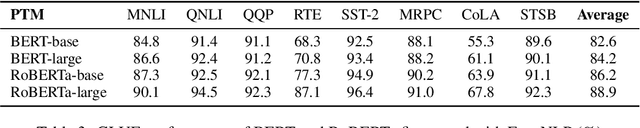
The success of Pre-Trained Models (PTMs) has reshaped the development of Natural Language Processing (NLP). Yet, it is not easy to obtain high-performing models and deploy them online for industrial practitioners. To bridge this gap, EasyNLP is designed to make it easy to build NLP applications, which supports a comprehensive suite of NLP algorithms. It further features knowledge-enhanced pre-training, knowledge distillation and few-shot learning functionalities for large-scale PTMs, and provides a unified framework of model training, inference and deployment for real-world applications. Currently, EasyNLP has powered over ten business units within Alibaba Group and is seamlessly integrated to the Platform of AI (PAI) products on Alibaba Cloud. The source code of our EasyNLP toolkit is released at GitHub (https://github.com/alibaba/EasyNLP).
Multi-level Cross-view Contrastive Learning for Knowledge-aware Recommender System
Apr 19, 2022



Knowledge graph (KG) plays an increasingly important role in recommender systems. Recently, graph neural networks (GNNs) based model has gradually become the theme of knowledge-aware recommendation (KGR). However, there is a natural deficiency for GNN-based KGR models, that is, the sparse supervised signal problem, which may make their actual performance drop to some extent. Inspired by the recent success of contrastive learning in mining supervised signals from data itself, in this paper, we focus on exploring the contrastive learning in KG-aware recommendation and propose a novel multi-level cross-view contrastive learning mechanism, named MCCLK. Different from traditional contrastive learning methods which generate two graph views by uniform data augmentation schemes such as corruption or dropping, we comprehensively consider three different graph views for KG-aware recommendation, including global-level structural view, local-level collaborative and semantic views. Specifically, we consider the user-item graph as a collaborative view, the item-entity graph as a semantic view, and the user-item-entity graph as a structural view. MCCLK hence performs contrastive learning across three views on both local and global levels, mining comprehensive graph feature and structure information in a self-supervised manner. Besides, in semantic view, a k-Nearest-Neighbor (kNN) item-item semantic graph construction module is proposed, to capture the important item-item semantic relation which is usually ignored by previous work. Extensive experiments conducted on three benchmark datasets show the superior performance of our proposed method over the state-of-the-arts. The implementations are available at: https://github.com/CCIIPLab/MCCLK.