 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIRL: A General Framework for Hierarchical Image Representation Learning
May 26, 2022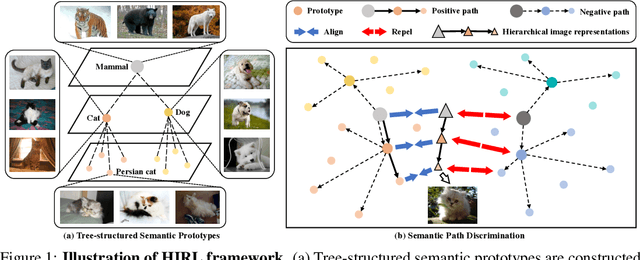
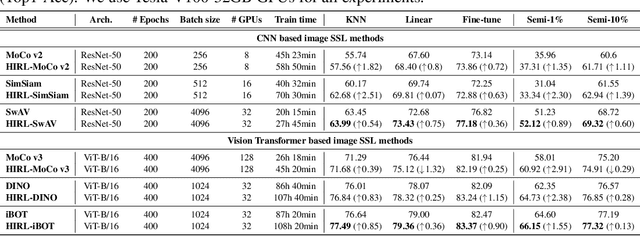


Learning self-supervised image representations has been broadly studied to boost various visual understanding tasks. Existing methods typically learn a single level of image semantics like pairwise semantic similarity or image clustering patterns. However, these methods can hardly capture multiple levels of semantic information that naturally exists in an image dataset, e.g., the semantic hierarchy of "Persian cat to cat to mammal" encoded in an image database for species. It is thus unknown whether an arbitrary image self-supervised learning (SSL) approach can benefit from learning such hierarchical semantics. To answer this question, we propose a general framework for Hierarchical Image Representation Learning (HIRL). This framework aims to learn multiple semantic representations for each image, and these representations are structured to encode image semantics from fine-grained to coarse-grained. Based on a probabilistic factorization, HIRL learns the most fine-grained semantics by an off-the-shelf image SSL approach and learns multiple coarse-grained semantics by a novel semantic path discrimination scheme. We adopt six representative image SSL methods as baselines and study how they perform under HIRL. By rigorous fair comparison, performance gain is observed on all the six methods for diverse downstream tasks, which, for the first time, verifies the general effectiveness of learning hierarchical image semantics. All source code and model weights are available at https://github.com/hirl-team/HIRL
Spotlights: Probing Shapes from Spherical Viewpoints
May 25, 2022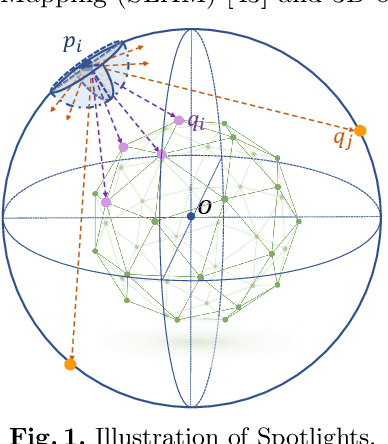
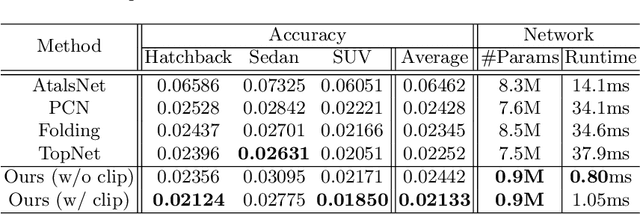
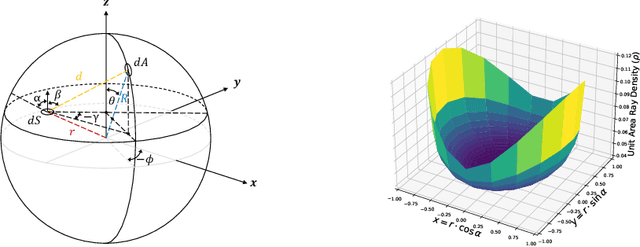
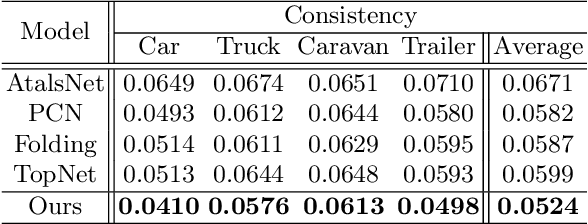
Recent years have witnessed the surge of learned representations that directly build upon point clouds. Though becoming increasingly expressive, most existing representations still struggle to generate ordered point sets. Inspired by spherical multi-view scanners, we propose a novel sampling model called Spotlights to represent a 3D shape as a compact 1D array of depth values. It simulates the configuration of cameras evenly distributed on a sphere, where each virtual camera casts light rays from its principal point through sample points on a small concentric spherical cap to probe for the possible intersections with the object surrounded by the sphere. The structured point cloud is hence given implicitly as a function of depths. We provide a detailed geometric analysis of this new sampling scheme and prove its effectiveness in the context of the point cloud completion task. Experimental results on both synthetic and real data demonstrate that our method achieves competitive accuracy and consistency while having a significantly reduced computational cost. Furthermore, we show superior performance on the downstream point cloud registration task over state-of-the-art completion methods.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
Protein Representation Learning by Geometric Structure Pretraining
Mar 14, 2022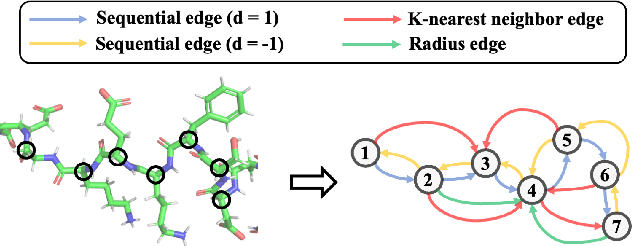
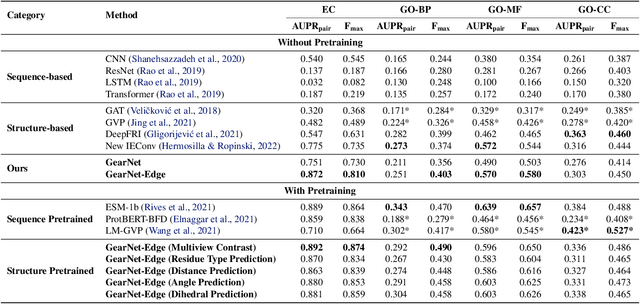
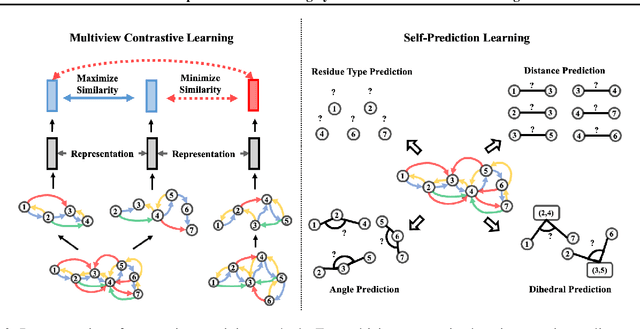
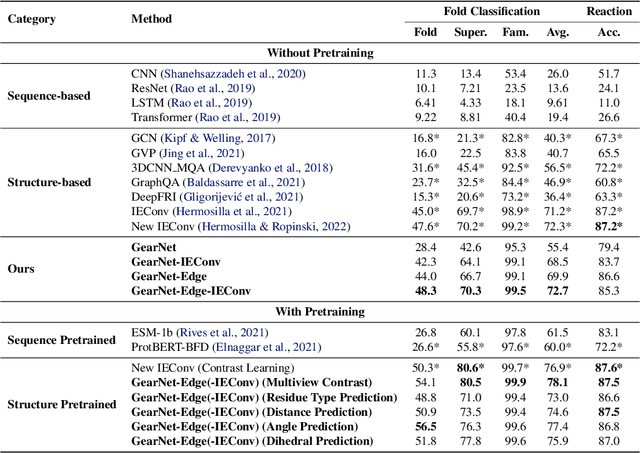
Learning effective protein representations is critical in a variety of tasks in biology such as predicting protein function or structure. Existing approaches usually pretrain protein language models on a large number of unlabeled amino acid sequences and then finetune the models with some labeled data in downstream tasks. Despite the effectiveness of sequence-based approaches, the power of pretraining on smaller numbers of known protein structures has not been explored for protein property prediction, though protein structures are known to be determinants of protein function. We first present a simple yet effective encoder to learn protein geometry features. We pretrain the protein graph encoder by leveraging multiview contrastive learning and different self-prediction tasks. Experimental results on both function prediction and fold classification tasks show that our proposed pretraining methods outperform or are on par with the state-of-the-art sequence-based methods using much less data. All codes and models will be published upon acceptance.
TorchDrug: A Powerful and Flexible Machine Learning Platform for Drug Discovery
Feb 16, 2022

Machine learning has huge potential to revolutionize the field of drug discovery and is attracting increasing attention in recent years. However, lacking domain knowledge (e.g., which tasks to work on), standard benchmarks and data preprocessing pipelines are the main obstacles for machine learning researchers to work in this domain. To facilitate the progress of machine learning for drug discovery, we develop TorchDrug, a powerful and flexible machine learning platform for drug discovery built on top of PyTorch. TorchDrug benchmarks a variety of important tasks in drug discovery, including molecular property prediction, pretrained molecular representations, de novo molecular design and optimization, retrosynthsis prediction, and biomedical knowledge graph reasoning. State-of-the-art techniques based on geometric deep learning (or graph machine learning), deep generative models, reinforcement learning and knowledge graph reasoning are implemented for these tasks. TorchDrug features a hierarchical interface that facilitates customization from both novices and experts in this domain. Tutorials, benchmark results and documentation are available at https://torchdrug.ai. Code is released under Apache License 2.0.
HCSC: Hierarchical Contrastive Selective Coding
Feb 01, 2022
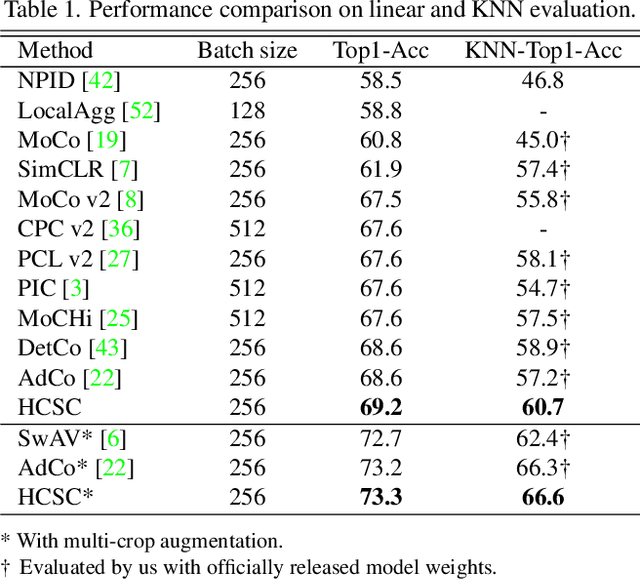
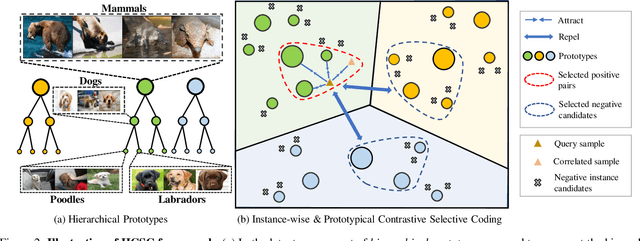
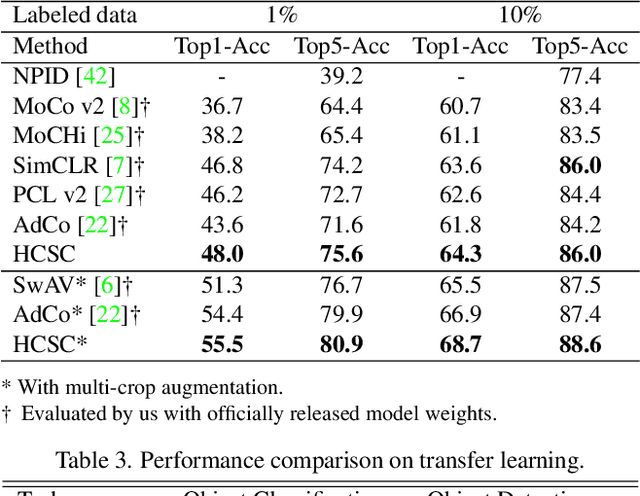
Hierarchical semantic structures naturally exist in an image dataset, in which several semantically relevant image clusters can be further integrated into a larger cluster with coarser-grained semantics. Capturing such structures with image representations can greatly benefit the semantic understanding on various downstream tasks. Existing contrastive representation learning methods lack such an important model capability. In addition, the negative pairs used in these methods are not guaranteed to be semantically distinct, which could further hamper the structural correctness of learned image representations. To tackle these limitations, we propose a novel contrastive learning framework called Hierarchical Contrastive Selective Coding (HCSC). In this framework, a set of hierarchical prototypes are constructed and also dynamically updated to represent the hierarchical semantic structures underlying the data in the latent space. To make image representations better fit such semantic structures, we employ and further improve conventional instance-wise and prototypical contrastive learning via an elaborate pair selection scheme. This scheme seeks to select more diverse positive pairs with similar semantics and more precise negative pairs with truly distinct semantics. On extensive downstream tasks, we verify the superior performance of HCSC over state-of-the-art contrastive methods, and the effectiveness of major model components is proved by plentiful analytical studies. Our source code and model weights are available at https://github.com/gyfastas/HCSC
Cross-category Video Highlight Detection via Set-based Learning
Aug 26, 2021
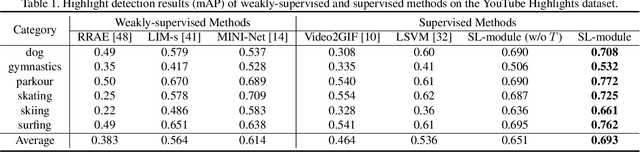
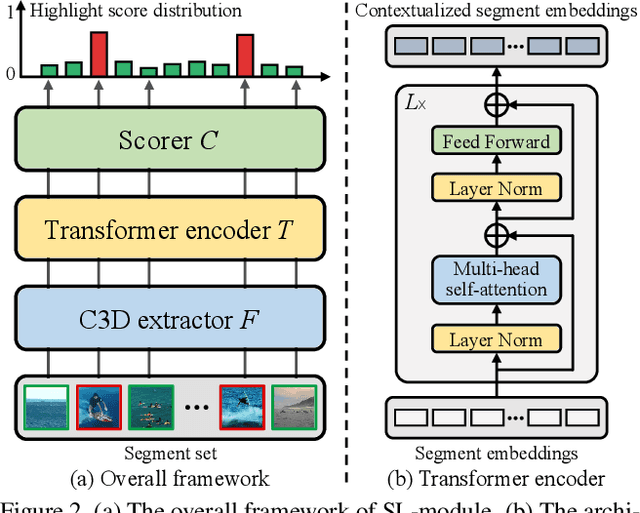
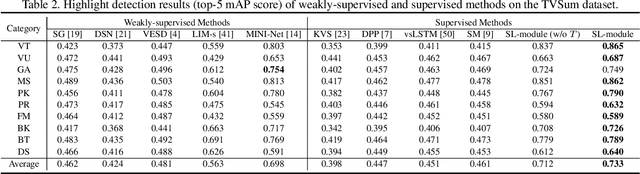
Autonomous highlight detection is crucial for enhancing the efficiency of video browsing on social media platforms. To attain this goal in a data-driven way, one may often face the situation where highlight annotations are not available on the target video category used in practice, while the supervision on another video category (named as source video category) is achievable. In such a situation, one can derive an effective highlight detector on target video category by transferring the highlight knowledge acquired from source video category to the target one. We call this problem cross-category video highlight detection, which has been rarely studied in previous works. For tackling such practical problem, we propose a Dual-Learner-based Video Highlight Detection (DL-VHD) framework. Under this framework, we first design a Set-based Learning module (SL-module) to improve the conventional pair-based learning by assessing the highlight extent of a video segment under a broader context. Based on such learning manner, we introduce two different learners to acquire the basic distinction of target category videos and the characteristics of highlight moments on source video category, respectively. These two types of highlight knowledge are further consolidated via knowledge distillation. Extensive experiments on three benchmark datasets demonstrate the superiority of the proposed SL-module, and the DL-VHD method outperforms five typical Unsupervised Domain Adaptation (UDA) algorithms on various cross-category highlight detection tasks. Our code is available at https://github.com/ChrisAllenMing/Cross_Category_Video_Highlight .
PIT: Position-Invariant Transform for Cross-FoV Domain Adaptation
Aug 16, 2021
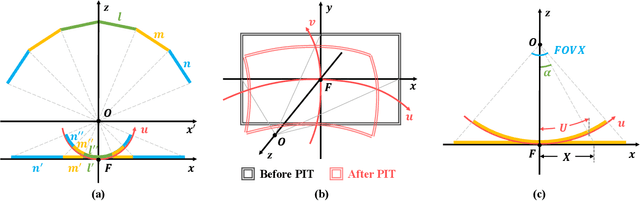
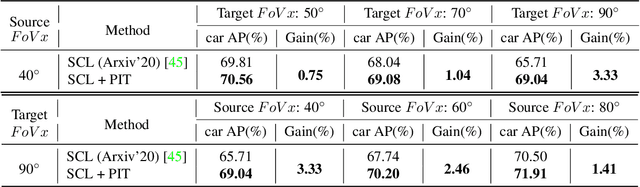
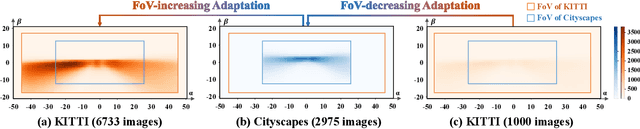
Cross-domain object detection and semantic segmentation have witnessed impressive progress recently. Existing approaches mainly consider the domain shift resulting from external environments including the changes of background, illumination or weather, while distinct camera intrinsic parameters appear commonly in different domains, and their influence for domain adaptation has been very rarely explored. In this paper, we observe that the Field of View (FoV) gap induces noticeable instance appearance differences between the source and target domains. We further discover that the FoV gap between two domains impairs domain adaptation performance under both the FoV-increasing (source FoV < target FoV) and FoV-decreasing cases. Motivated by the observations, we propose the \textbf{Position-Invariant Transform} (PIT) to better align images in different domains. We also introduce a reverse PIT for mapping the transformed/aligned images back to the original image space and design a loss re-weighting strategy to accelerate the training process. Our method can be easily plugged into existing cross-domain detection/segmentation frameworks while bringing about negligible computational overhead. Extensive experiments demonstrate that our method can soundly boost the performance on both cross-domain object detection and segmentation for state-of-the-art techniques. Our code is available at https://github.com/sheepooo/PIT-Position-Invariant-Transform.
Self-supervised Graph-level Representation Learning with Local and Global Structure
Jun 08, 2021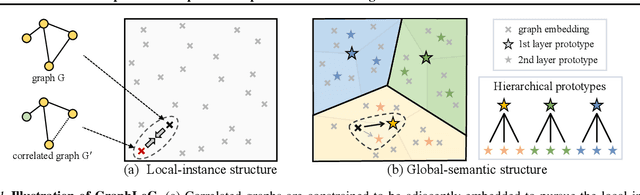
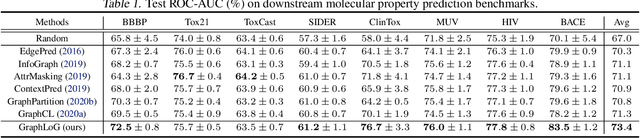
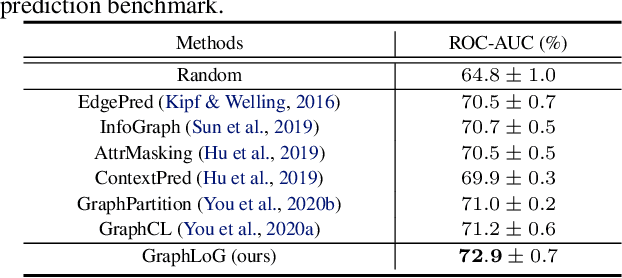

This paper studies unsupervised/self-supervised whole-graph representation learning, which is critical in many tasks such as molecule properties prediction in drug and material discovery. Existing methods mainly focus on preserving the local similarity structure between different graph instances but fail to discover the global semantic structure of the entire data set. In this paper, we propose a unified framework called Local-instance and Global-semantic Learning (GraphLoG) for self-supervised whole-graph representation learning. Specifically, besides preserving the local similarities, GraphLoG introduces the hierarchical prototypes to capture the global semantic clusters. An efficient online expectation-maximization (EM) algorithm is further developed for learning the model. We evaluate GraphLoG by pre-training it on massive unlabeled graphs followed by fine-tuning on downstream tasks. Extensive experiments on both chemical and biological benchmark data sets demonstrate the effectiveness of the proposed approach.
Graphical Modeling for Multi-Source Domain Adaptation
Apr 27, 2021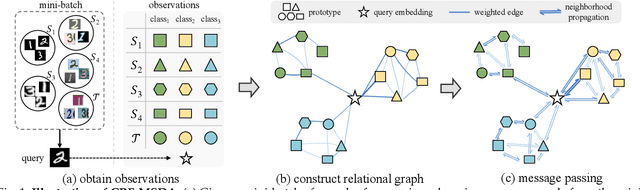

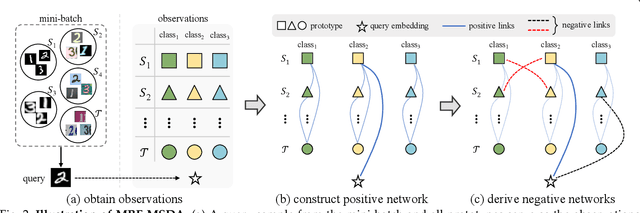
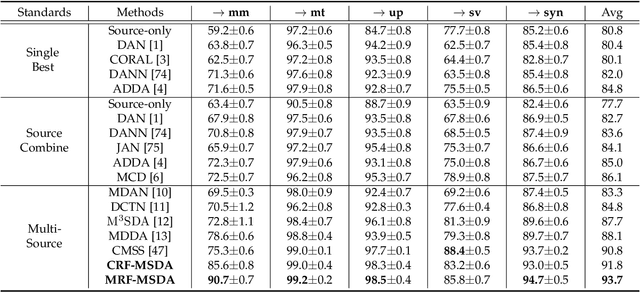
Multi-Source Domain Adaptation (MSDA) focuses on transferring the knowledge from multiple source domains to the target domain, which is a more practical and challenging problem compared to the conventional single-source domain adaptation. In this problem, it is essential to utilize the labeled source data and the unlabeled target data to approach the conditional distribution of semantic label on target domain, which requires the joint modeling across different domains and also an effective domain combination scheme. The graphical structure among different domains is useful to tackle these challenges, in which the interdependency among various instances/categories can be effectively modeled. In this work, we propose two types of graphical models,i.e. Conditional Random Field for MSDA (CRF-MSDA) and Markov Random Field for MSDA (MRF-MSDA), for cross-domain joint modeling and learnable domain combination. In a nutshell, given an observation set composed of a query sample and the semantic prototypes i.e. representative category embeddings) on various domains, the CRF-MSDA model seeks to learn the joint distribution of labels conditioned on the observations. We attain this goal by constructing a relational graph over all observations and conducting local message passing on it. By comparison, MRF-MSDA aims to model the joint distribution of observations over different Markov networks via an energy-based formulation, and it can naturally perform label prediction by summing the joint likelihoods over several specific networks. Compared to the CRF-MSDA counterpart, the MRF-MSDA model is more expressive and possesses lower computational cost. We evaluate these two models on four standard benchmark data sets of MSDA with distinct domain shift and data complexity, and both models achieve superior performance over existing methods on all benchmarks.