 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSFix3D: Diffusion-Guided Repair of Novel Views in Gaussian Splatting
Aug 20, 2025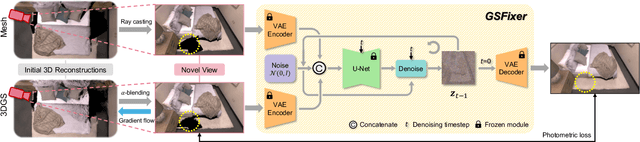
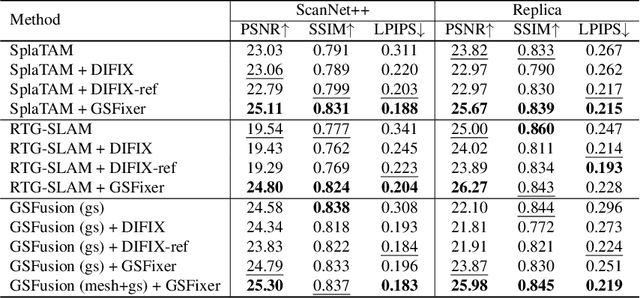
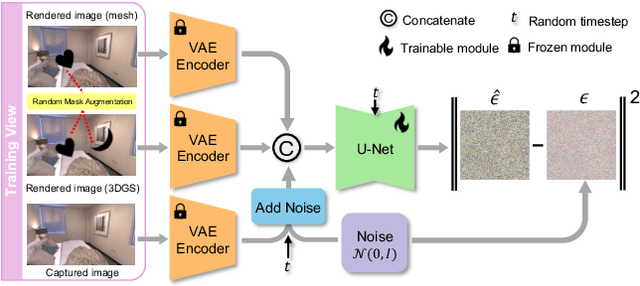

Recent developments in 3D Gaussian Splatting have significantly enhanced novel view synthesis, yet generating high-quality renderings from extreme novel viewpoints or partially observed regions remains challenging. Meanwhile, diffusion models exhibit strong generative capabilities, but their reliance on text prompts and lack of awareness of specific scene information hinder accurate 3D reconstruction tasks. To address these limitations, we introduce GSFix3D, a novel framework that improves the visual fidelity in under-constrained regions by distilling prior knowledge from diffusion models into 3D representations, while preserving consistency with observed scene details. At its core is GSFixer, a latent diffusion model obtained via our customized fine-tuning protocol that can leverage both mesh and 3D Gaussians to adapt pretrained generative models to a variety of environments and artifact types from different reconstruction methods, enabling robust novel view repair for unseen camera poses. Moreover, we propose a random mask augmentation strategy that empowers GSFixer to plausibly inpaint missing regions. Experiments on challenging benchmarks demonstrate that our GSFix3D and GSFixer achieve state-of-the-art performance, requiring only minimal scene-specific fine-tuning on captured data. Real-world test further confirms its resilience to potential pose errors. Our code and data will be made publicly available. Project page: https://gsfix3d.github.io.
Improving the Stability of GNN Force Field Models by Reducing Feature Correlation
Feb 18, 2025



Recently, Graph Neural Network based Force Field (GNNFF) models are widely used in Molecular Dynamics (MD) simulation, which is one of the most cost-effective means in semiconductor material research. However, even such models provide high accuracy in energy and force Mean Absolute Error (MAE) over trained (in-distribution) datasets, they often become unstable during long-time MD simulation when used for out-of-distribution datasets. In this paper, we propose a feature correlation based method for GNNFF models to enhance the stability of MD simulation. We reveal the negative relationship between feature correlation and the stability of GNNFF models, and design a loss function with a dynamic loss coefficient scheduler to reduce edge feature correlation that can be applied in general GNNFF training. We also propose an empirical metric to evaluate the stability in MD simulation. Experiments show our method can significantly improve stability for GNNFF models especially in out-of-distribution data with less than 3% computational overhead. For example, we can ensure the stable MD simulation time from 0.03ps to 10ps for Allegro model.
GSFusion: Online RGB-D Mapping Where Gaussian Splatting Meets TSDF Fusion
Aug 26, 2024Traditional volumetric fusion algorithms preserve the spatial structure of 3D scenes, which is beneficial for many tasks in computer vision and robotics. However, they often lack realism in terms of visualization. Emerging 3D Gaussian splatting bridges this gap, but existing Gaussian-based reconstruction methods often suffer from artifacts and inconsistencies with the underlying 3D structure, and struggle with real-time optimization, unable to provide users with immediate feedback in high quality. One of the bottlenecks arises from the massive amount of Gaussian parameters that need to be updated during optimization. Instead of using 3D Gaussian as a standalone map representation, we incorporate it into a volumetric mapping system to take advantage of geometric information and propose to use a quadtree data structure on images to drastically reduce the number of splats initialized. In this way, we simultaneously generate a compact 3D Gaussian map with fewer artifacts and a volumetric map on the fly. Our method, GSFusion, significantly enhances computational efficiency without sacrificing rendering quality, as demonstrated on both synthetic and real datasets. Code will be available at https://github.com/goldoak/GSFusion.
AP$n$P: A Less-constrained P$n$P Solver for Pose Estimation with Unknown Anisotropic Scaling or Focal Lengths
Oct 18, 2023Perspective-$n$-Point (P$n$P) stands as a fundamental algorithm for pose estimation in various applications. In this paper, we present a new approach to the P$n$P problem with relaxed constraints, eliminating the need for precise 3D coordinates or complete calibration data. We refer to it as AP$n$P due to its ability to handle unknown anisotropic scaling factors of 3D coordinates or alternatively two distinct focal lengths in addition to the conventional rigid pose. Through algebraic manipulations and a novel parametrization, both cases are brought into similar forms that distinguish themselves primarily by the order of a rotation and an anisotropic scaling operation. AP$n$P furthermore brings down both cases to an identical polynomial problem, which is solved using the Gr\"obner basis approach. Experimental results on both simulated and real datasets demonstrate the effectiveness of AP$n$P, providing a more flexible and practical solution to several pose estimation tasks. Code: https://github.com/goldoak/APnP.
RGB-based Category-level Object Pose Estimation via Decoupled Metric Scale Recovery
Sep 19, 2023While showing promising results, recent RGB-D camera-based category-level object pose estimation methods have restricted applications due to the heavy reliance on depth sensors. RGB-only methods provide an alternative to this problem yet suffer from inherent scale ambiguity stemming from monocular observations. In this paper, we propose a novel pipeline that decouples the 6D pose and size estimation to mitigate the influence of imperfect scales on rigid transformations. Specifically, we leverage a pre-trained monocular estimator to extract local geometric information, mainly facilitating the search for inlier 2D-3D correspondence. Meanwhile, a separate branch is designed to directly recover the metric scale of the object based on category-level statistics. Finally, we advocate using the RANSAC-P$n$P algorithm to robustly solve for 6D object pose. Extensive experiments have been conducted on both synthetic and real datasets, demonstrating the superior performance of our method over previous state-of-the-art RGB-based approaches, especially in terms of rotation accuracy.
Cross-modal Place Recognition in Image Databases using Event-based Sensors
Jul 03, 2023Visual place recognition is an important problem towards global localization in many robotics tasks. One of the biggest challenges is that it may suffer from illumination or appearance changes in surrounding environments. Event cameras are interesting alternatives to frame-based sensors as their high dynamic range enables robust perception in difficult illumination conditions. However, current event-based place recognition methods only rely on event information, which restricts downstream applications of VPR. In this paper, we present the first cross-modal visual place recognition framework that is capable of retrieving regular images from a database given an event query. Our method demonstrates promising results with respect to the state-of-the-art frame-based and event-based methods on the Brisbane-Event-VPR dataset under different scenarios. We also verify the effectiveness of the combination of retrieval and classification, which can boost performance by a large margin.
Incremental Semantic Localization using Hierarchical Clustering of Object Association Sets
Aug 28, 2022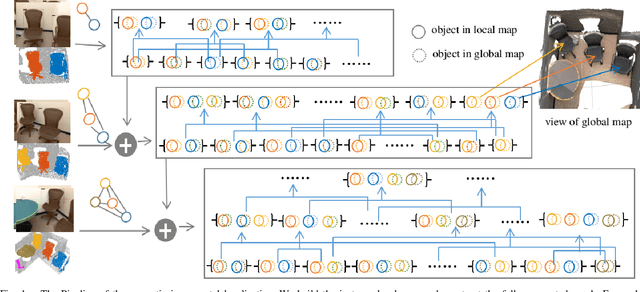
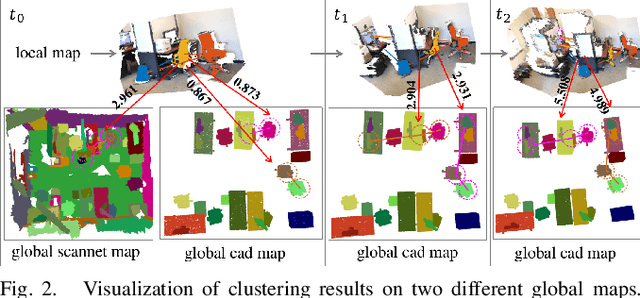
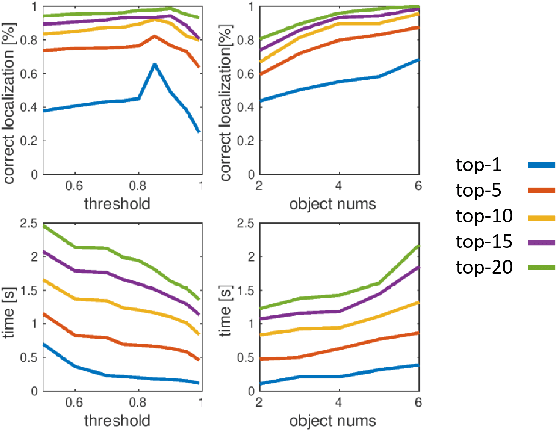
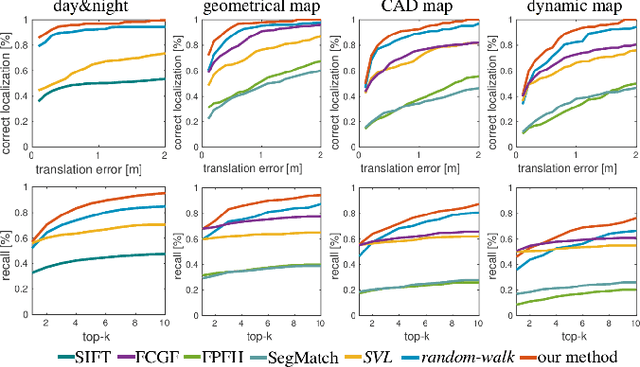
We present a novel approach for relocalization or place recognition, a fundamental problem to be solved in many robotics, automation, and AR applications. Rather than relying on often unstable appearance information, we consider a situation in which the reference map is given in the form of localized objects. Our localization framework relies on 3D semantic object detections, which are then associated to objects in the map. Possible pair-wise association sets are grown based on hierarchical clustering using a merge metric that evaluates spatial compatibility. The latter notably uses information about relative object configurations, which is invariant with respect to global transformations. Association sets are furthermore updated and expanded as the camera incrementally explores the environment and detects further objects. We test our algorithm in several challenging situations including dynamic scenes, large view-point changes, and scenes with repeated instances. Our experiments demonstrate that our approach outperforms prior art in terms of both robustness and accuracy.
Accurate Instance-Level CAD Model Retrieval in a Large-Scale Database
Jul 04, 2022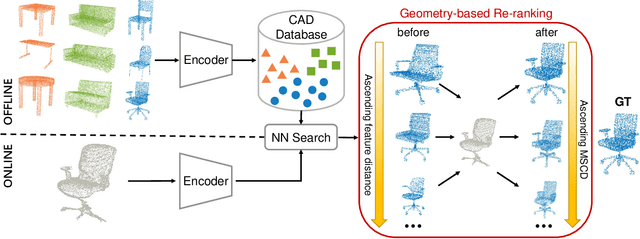
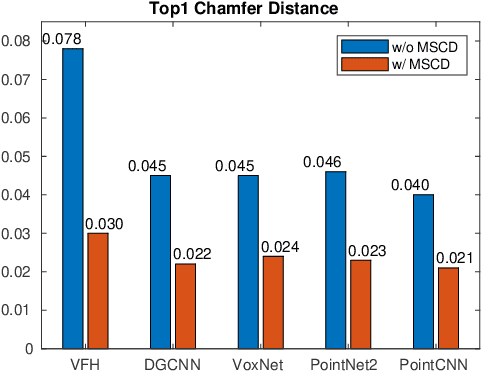
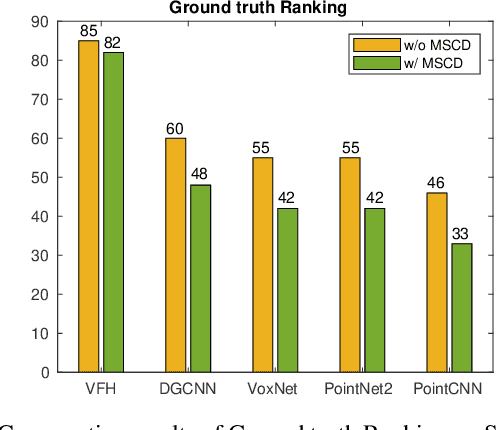
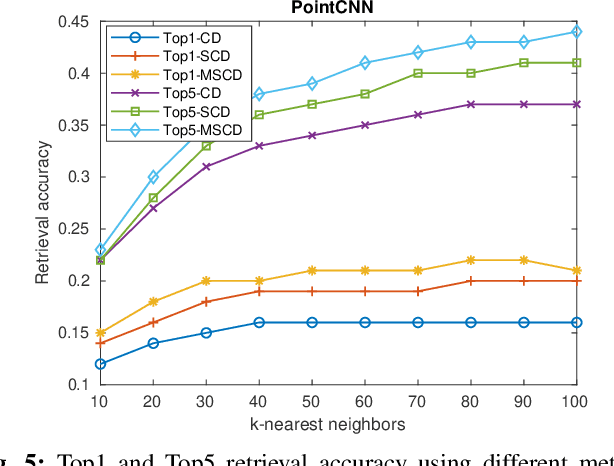
We present a new solution to the fine-grained retrieval of clean CAD models from a large-scale database in order to recover detailed object shape geometries for RGBD scans. Unlike previous work simply indexing into a moderately small database using an object shape descriptor and accepting the top retrieval result, we argue that in the case of a large-scale database a more accurate model may be found within a neighborhood of the descriptor. More importantly, we propose that the distinctiveness deficiency of shape descriptors at the instance level can be compensated by a geometry-based re-ranking of its neighborhood. Our approach first leverages the discriminative power of learned representations to distinguish between different categories of models and then uses a novel robust point set distance metric to re-rank the CAD neighborhood, enabling fine-grained retrieval in a large shape database. Evaluation on a real-world dataset shows that our geometry-based re-ranking is a conceptually simple but highly effective method that can lead to a significant improvement in retrieval accuracy compared to the state-of-the-art.
Spotlights: Probing Shapes from Spherical Viewpoints
May 25, 2022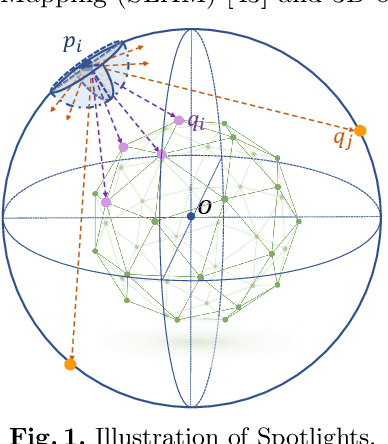
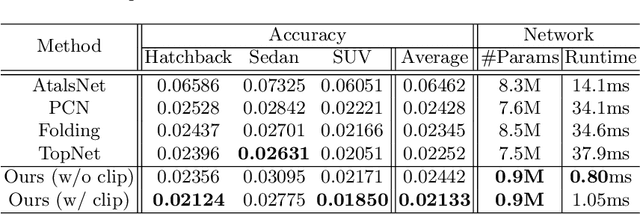
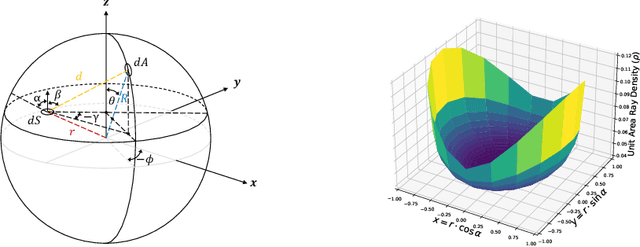
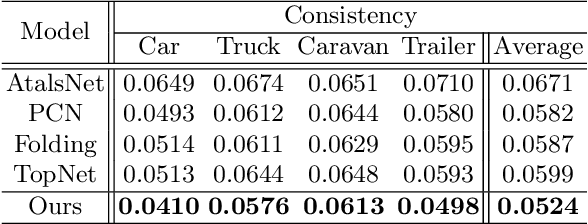
Recent years have witnessed the surge of learned representations that directly build upon point clouds. Though becoming increasingly expressive, most existing representations still struggle to generate ordered point sets. Inspired by spherical multi-view scanners, we propose a novel sampling model called Spotlights to represent a 3D shape as a compact 1D array of depth values. It simulates the configuration of cameras evenly distributed on a sphere, where each virtual camera casts light rays from its principal point through sample points on a small concentric spherical cap to probe for the possible intersections with the object surrounded by the sphere. The structured point cloud is hence given implicitly as a function of depths. We provide a detailed geometric analysis of this new sampling scheme and prove its effectiveness in the context of the point cloud completion task. Experimental results on both synthetic and real data demonstrate that our method achieves competitive accuracy and consistency while having a significantly reduced computational cost. Furthermore, we show superior performance on the downstream point cloud registration task over state-of-the-art completion methods.