 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing the extended Fourier Mellin Transformation Algorithm
Jul 19, 2023



With the increasing application of robots, stable and efficient Visual Odometry (VO) algorithms are becoming more and more important. Based on the Fourier Mellin Transformation (FMT) algorithm, the extended Fourier Mellin Transformation (eFMT) is an image registration approach that can be applied to downward-looking cameras, for example on aerial and underwater vehicles. eFMT extends FMT to multi-depth scenes and thus more application scenarios. It is a visual odometry method which estimates the pose transformation between three overlapping images. On this basis, we develop an optimized eFMT algorithm that improves certain aspects of the method and combines it with back-end optimization for the small loop of three consecutive frames. For this we investigate the extraction of uncertainty information from the eFMT registration, the related objective function and the graph-based optimization. Finally, we design a series of experiments to investigate the properties of this approach and compare it with other VO and SLAM (Simultaneous Localization and Mapping) algorithms. The results show the superior accuracy and speed of our o-eFMT approach, which is published as open source.
Spotlights: Probing Shapes from Spherical Viewpoints
May 25, 2022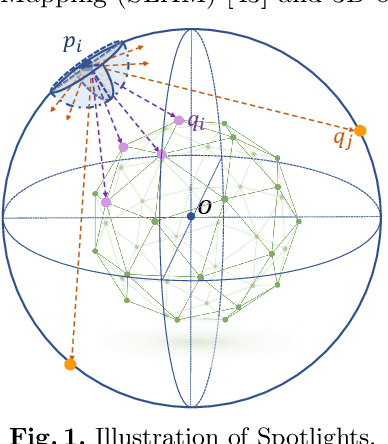
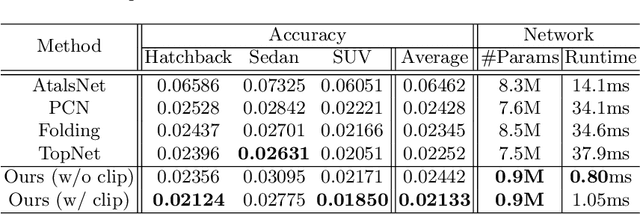
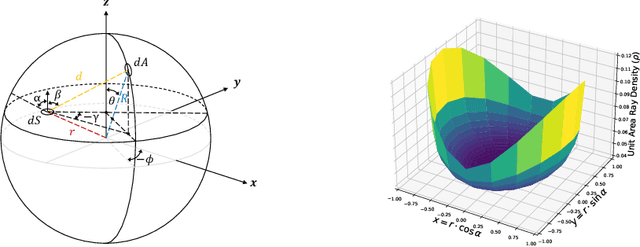
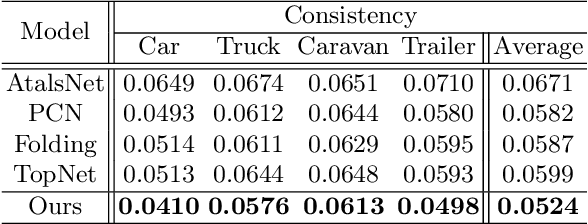
Recent years have witnessed the surge of learned representations that directly build upon point clouds. Though becoming increasingly expressive, most existing representations still struggle to generate ordered point sets. Inspired by spherical multi-view scanners, we propose a novel sampling model called Spotlights to represent a 3D shape as a compact 1D array of depth values. It simulates the configuration of cameras evenly distributed on a sphere, where each virtual camera casts light rays from its principal point through sample points on a small concentric spherical cap to probe for the possible intersections with the object surrounded by the sphere. The structured point cloud is hence given implicitly as a function of depths. We provide a detailed geometric analysis of this new sampling scheme and prove its effectiveness in the context of the point cloud completion task. Experimental results on both synthetic and real data demonstrate that our method achieves competitive accuracy and consistency while having a significantly reduced computational cost. Furthermore, we show superior performance on the downstream point cloud registration task over state-of-the-art completion methods.
Accurate calibration of multi-perspective cameras from a generalization of the hand-eye constraint
Feb 08, 2022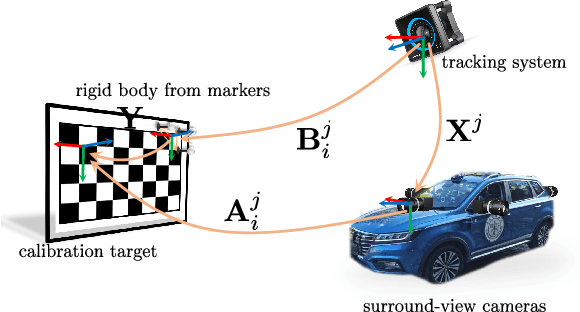
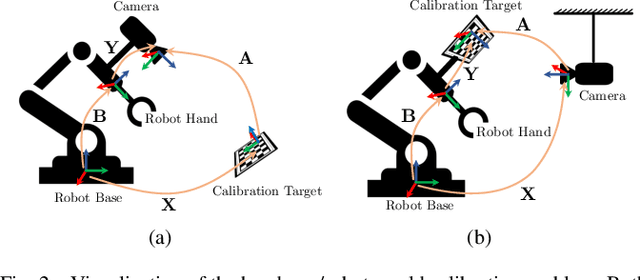
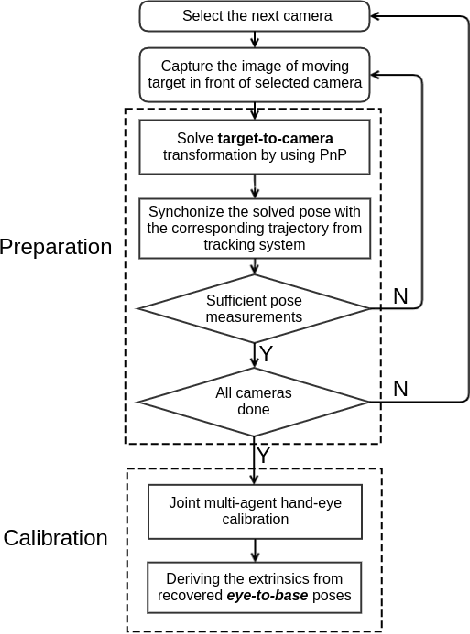
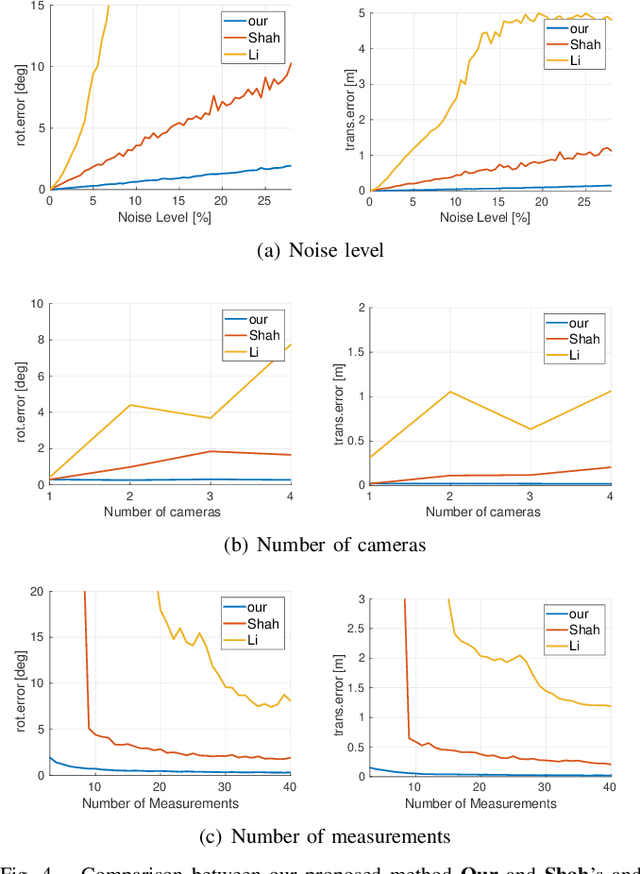
Multi-perspective cameras are quickly gaining importance in many applications such as smart vehicles and virtual or augmented reality. However, a large system size or absence of overlap in neighbouring fields-of-view often complicate their calibration. We present a novel solution which relies on the availability of an external motion capture system. Our core contribution consists of an extension to the hand-eye calibration problem which jointly solves multi-eye-to-base problems in closed form. We furthermore demonstrate its equivalence to the multi-eye-in-hand problem. The practical validity of our approach is supported by our experiments, indicating that the method is highly efficient and accurate, and outperforms existing closed-form alternatives.