 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Best Combination for Efficient N:M Sparsity
Jun 14, 2022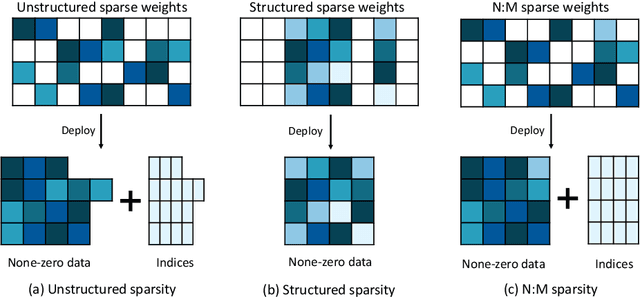
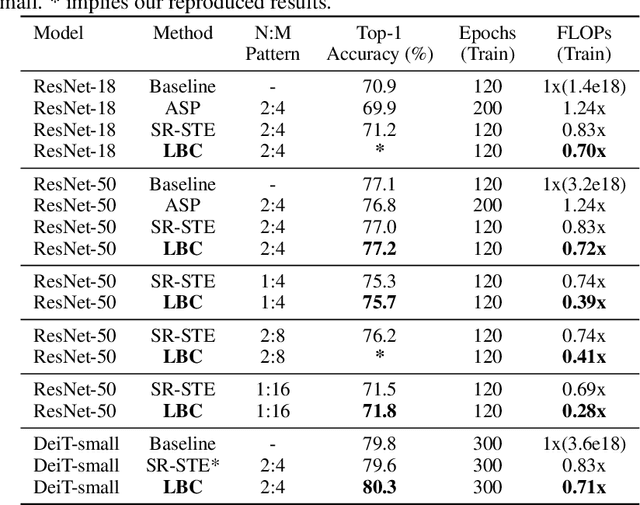
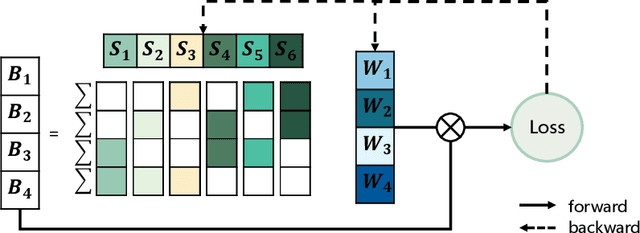
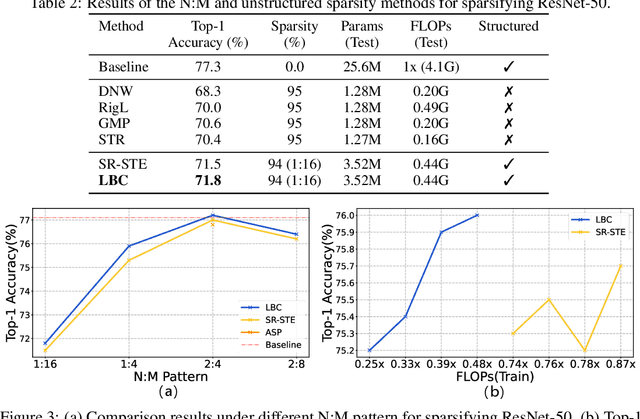
By forcing at most N out of M consecutive weights to be non-zero, the recent N:M network sparsity has received increasing attention for its two attractive advantages: 1) Promising performance at a high sparsity. 2) Significant speedups on NVIDIA A100 GPUs. Recent studies require an expensive pre-training phase or a heavy dense-gradient computation. In this paper, we show that the N:M learning can be naturally characterized as a combinatorial problem which searches for the best combination candidate within a finite collection. Motivated by this characteristic, we solve N:M sparsity in an efficient divide-and-conquer manner. First, we divide the weight vector into $C_{\text{M}}^{\text{N}}$ combination subsets of a fixed size N. Then, we conquer the combinatorial problem by assigning each combination a learnable score that is jointly optimized with its associate weights. We prove that the introduced scoring mechanism can well model the relative importance between combination subsets. And by gradually removing low-scored subsets, N:M fine-grained sparsity can be efficiently optimized during the normal training phase. Comprehensive experiments demonstrate that our learning best combination (LBC) performs consistently better than off-the-shelf N:M sparsity methods across various networks. Our code is released at \url{https://github.com/zyxxmu/LBC}.
Super Vision Transformer
May 26, 2022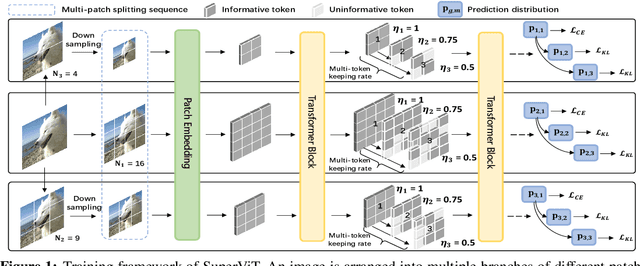
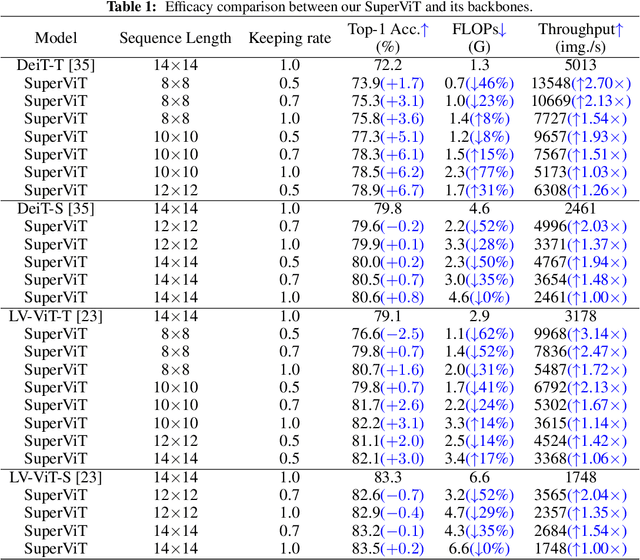
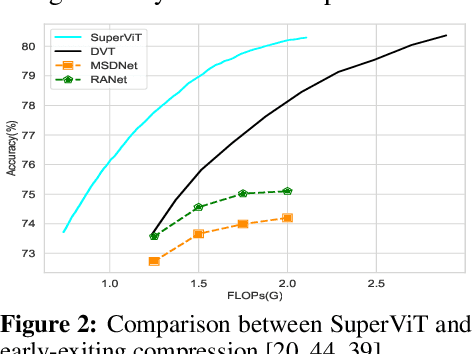
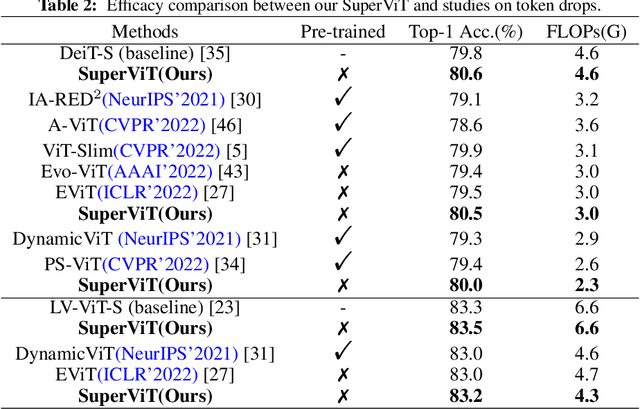
We attempt to reduce the computational costs in vision transformers (ViTs), which increase quadratically in the token number. We present a novel training paradigm that trains only one ViT model at a time, but is capable of providing improved image recognition performance with various computational costs. Here, the trained ViT model, termed super vision transformer (SuperViT), is empowered with the versatile ability to solve incoming patches of multiple sizes as well as preserve informative tokens with multiple keeping rates (the ratio of keeping tokens) to achieve good hardware efficiency for inference, given that the available hardware resources often change from time to time. Experimental results on ImageNet demonstrate that our SuperViT can considerably reduce the computational costs of ViT models with even performance increase. For example, we reduce 2x FLOPs of DeiT-S while increasing the Top-1 accuracy by 0.2% and 0.7% for 1.5x reduction. Also, our SuperViT significantly outperforms existing studies on efficient vision transformers. For example, when consuming the same amount of FLOPs, our SuperViT surpasses the recent state-of-the-art (SoTA) EViT by 1.1% when using DeiT-S as their backbones. The project of this work is made publicly available at https://github.com/lmbxmu/SuperViT.
Shadow-Aware Dynamic Convolution for Shadow Removal
May 10, 2022
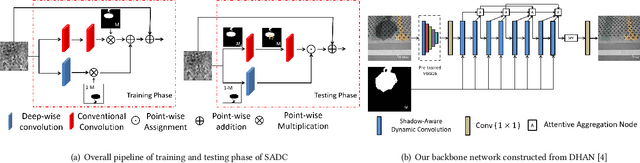
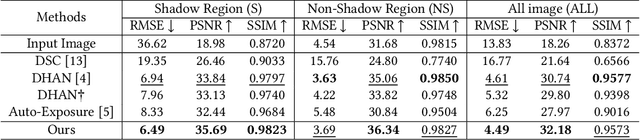
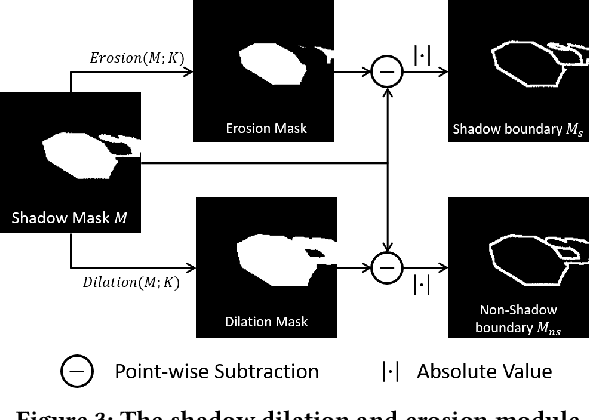
With a wide range of shadows in many collected images, shadow removal has aroused increasing attention since uncontaminated images are of vital importance for many downstream multimedia tasks. Current methods consider the same convolution operations for both shadow and non-shadow regions while ignoring the large gap between the color mappings for the shadow region and the non-shadow region, leading to poor quality of reconstructed images and a heavy computation burden. To solve this problem, this paper introduces a novel plug-and-play Shadow-Aware Dynamic Convolution (SADC) module to decouple the interdependence between the shadow region and the non-shadow region. Inspired by the fact that the color mapping of the non-shadow region is easier to learn, our SADC processes the non-shadow region with a lightweight convolution module in a computationally cheap manner and recovers the shadow region with a more complicated convolution module to ensure the quality of image reconstruction. Given that the non-shadow region often contains more background color information, we further develop a novel intra-convolution distillation loss to strengthen the information flow from the non-shadow region to the shadow region. Extensive experiments on the ISTD and SRD datasets show our method achieves better performance in shadow removal over many state-of-the-arts. Our code is available at https://github.com/xuyimin0926/SADC.
End-to-End Zero-Shot HOI Detection via Vision and Language Knowledge Distillation
Apr 01, 2022
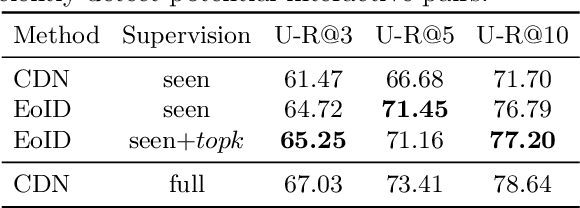
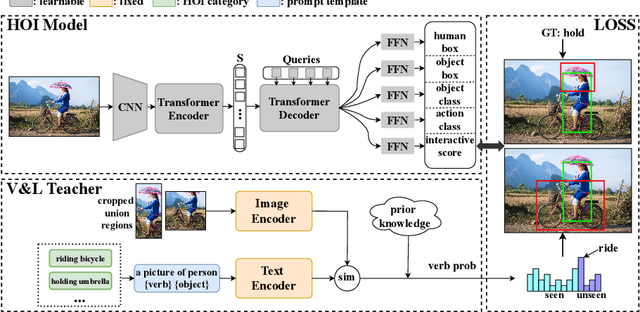

Most existing Human-Object Interaction~(HOI) Detection methods rely heavily on full annotations with predefined HOI categories, which is limited in diversity and costly to scale further. We aim at advancing zero-shot HOI detection to detect both seen and unseen HOIs simultaneously. The fundamental challenges are to discover potential human-object pairs and identify novel HOI categories. To overcome the above challenges, we propose a novel end-to-end zero-shot HOI Detection (EoID) framework via vision-language knowledge distillation. We first design an Interactive Score module combined with a Two-stage Bipartite Matching algorithm to achieve interaction distinguishment for human-object pairs in an action-agnostic manner. Then we transfer the distribution of action probability from the pretrained vision-language teacher as well as the seen ground truth to the HOI model to attain zero-shot HOI classification. Extensive experiments on HICO-Det dataset demonstrate that our model discovers potential interactive pairs and enables the recognition of unseen HOIs. Finally, our method outperforms the previous SOTA by 8.92% on unseen mAP and 10.18% on overall mAP under UA setting, by 6.02% on unseen mAP and 9.1% on overall mAP under UC setting. Moreover, our method is generalizable to large-scale object detection data to further scale up the action sets. The source code will be available at: https://github.com/mrwu-mac/EoID.
SeqTR: A Simple yet Universal Network for Visual Grounding
Mar 30, 2022
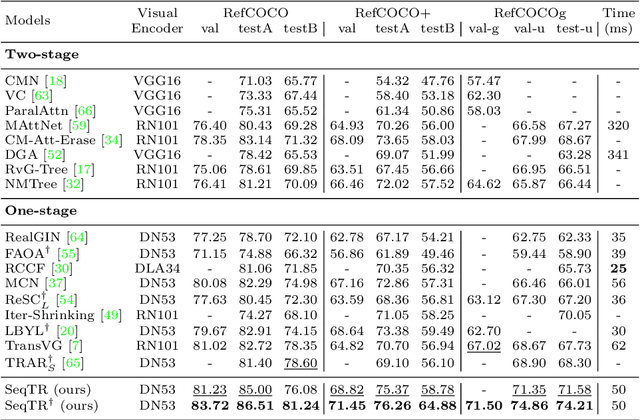
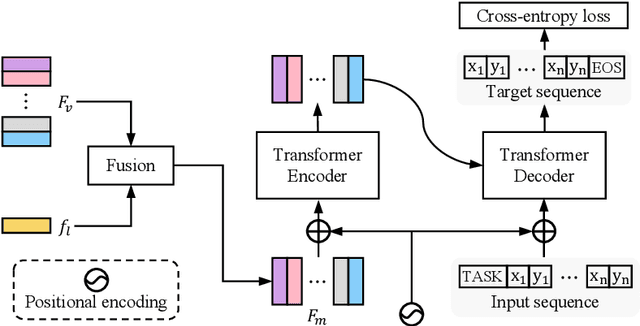
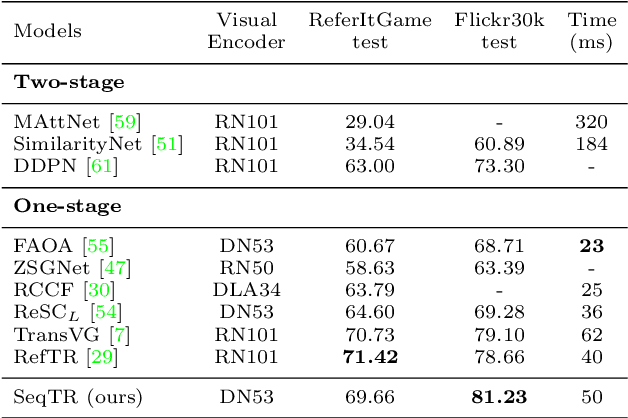
In this paper, we propose a simple yet universal network termed SeqTR for visual grounding tasks, e.g., phrase localization, referring expression comprehension (REC) and segmentation (RES). The canonical paradigms for visual grounding often require substantial expertise in designing network architectures and loss functions, making them hard to generalize across tasks. To simplify and unify the modeling, we cast visual grounding as a point prediction problem conditioned on image and text inputs, where either the bounding box or binary mask is represented as a sequence of discrete coordinate tokens. Under this paradigm, visual grounding tasks are unified in our SeqTR network without task-specific branches or heads, e.g., the convolutional mask decoder for RES, which greatly reduces the complexity of multi-task modeling. In addition, SeqTR also shares the same optimization objective for all tasks with a simple cross-entropy loss, further reducing the complexity of deploying hand-crafted loss functions. Experiments on five benchmark datasets demonstrate that the proposed SeqTR outperforms (or is on par with) the existing state-of-the-arts, proving that a simple yet universal approach for visual grounding is indeed feasible.
ARM: Any-Time Super-Resolution Method
Mar 21, 2022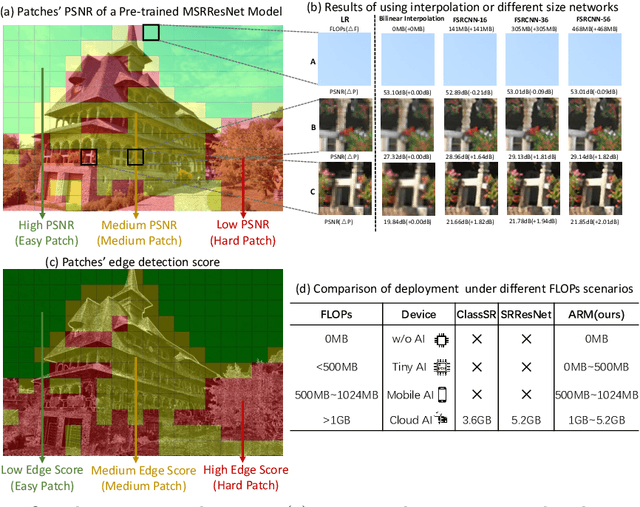
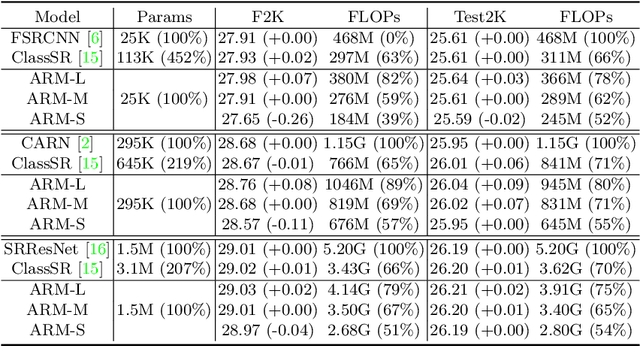

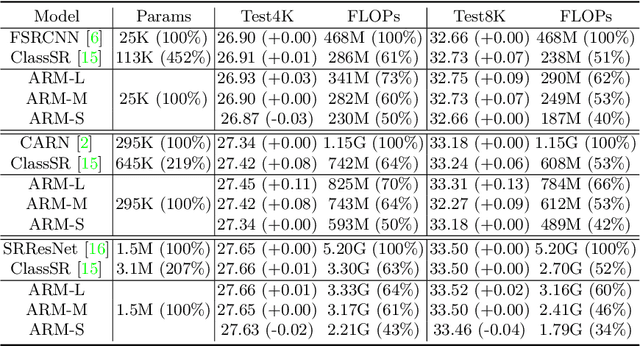
This paper proposes an Any-time super-Resolution Method (ARM) to tackle the over-parameterized single image super-resolution (SISR) models. Our ARM is motivated by three observations: (1) The performance of different image patches varies with SISR networks of different sizes. (2) There is a tradeoff between computation overhead and performance of the reconstructed image. (3) Given an input image, its edge information can be an effective option to estimate its PSNR. Subsequently, we train an ARM supernet containing SISR subnets of different sizes to deal with image patches of various complexity. To that effect, we construct an Edge-to-PSNR lookup table that maps the edge score of an image patch to the PSNR performance for each subnet, together with a set of computation costs for the subnets. In the inference, the image patches are individually distributed to different subnets for a better computation-performance tradeoff. Moreover, each SISR subnet shares weights of the ARM supernet, thus no extra parameters are introduced. The setting of multiple subnets can well adapt the computational cost of SISR model to the dynamically available hardware resources, allowing the SISR task to be in service at any time. Extensive experiments on resolution datasets of different sizes with popular SISR networks as backbones verify the effectiveness and the versatility of our ARM. The source code is available at \url{https://github.com/chenbong/ARM-Net}.
Dynamic Dual Trainable Bounds for Ultra-low Precision Super-Resolution Networks
Mar 10, 2022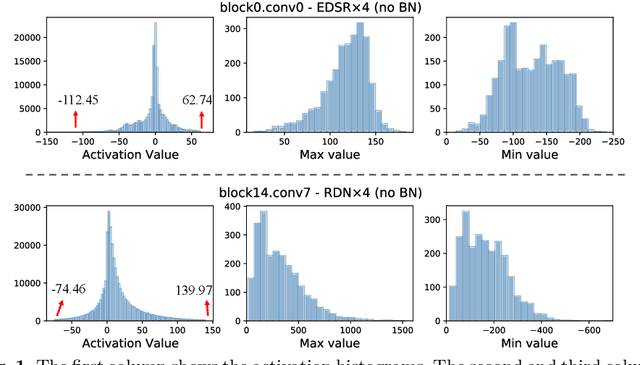
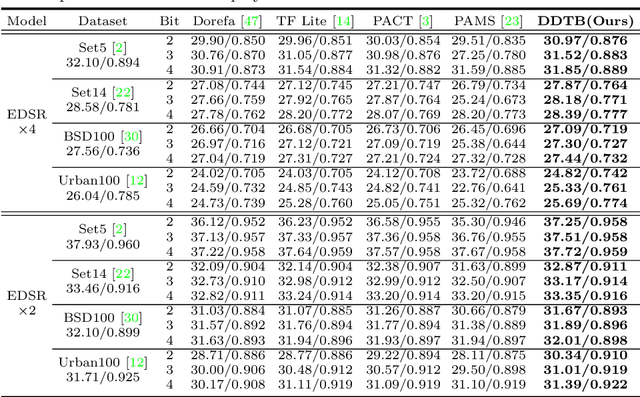
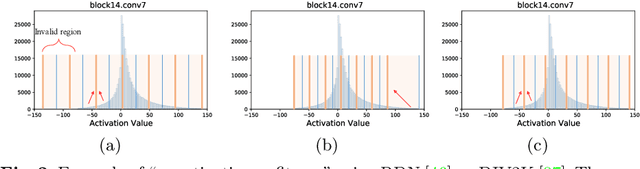
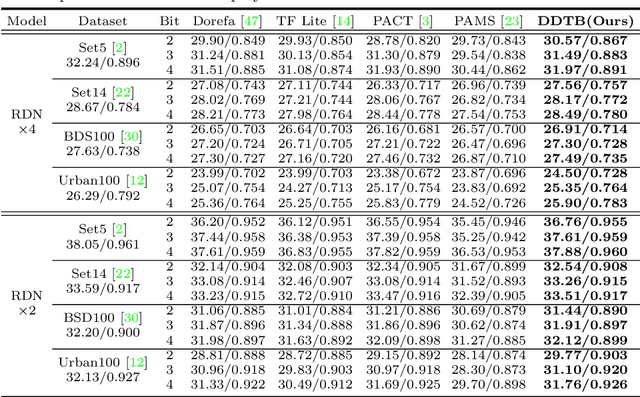
Light-weight super-resolution (SR) models have received considerable attention for their serviceability in mobile devices. Many efforts employ network quantization to compress SR models. However, these methods suffer from severe performance degradation when quantizing the SR models to ultra-low precision (e.g., 2-bit and 3-bit) with the low-cost layer-wise quantizer. In this paper, we identify that the performance drop comes from the contradiction between the layer-wise symmetric quantizer and the highly asymmetric activation distribution in SR models. This discrepancy leads to either a waste on the quantization levels or detail loss in reconstructed images. Therefore, we propose a novel activation quantizer, referred to as Dynamic Dual Trainable Bounds (DDTB), to accommodate the asymmetry of the activations. Specifically, DDTB innovates in: 1) A layer-wise quantizer with trainable upper and lower bounds to tackle the highly asymmetric activations. 2) A dynamic gate controller to adaptively adjust the upper and lower bounds at runtime to overcome the drastically varying activation ranges over different samples.To reduce the extra overhead, the dynamic gate controller is quantized to 2-bit and applied to only part of the SR networks according to the introduced dynamic intensity. Extensive experiments demonstrate that our DDTB exhibits significant performance improvements in ultra-low precision. For example, our DDTB achieves a 0.70dB PSNR increase on Urban100 benchmark when quantizing EDSR to 2-bit and scaling up output images to x4. Code is at \url{https://github.com/zysxmu/DDTB}.
Coarse-to-Fine Vision Transformer
Mar 08, 2022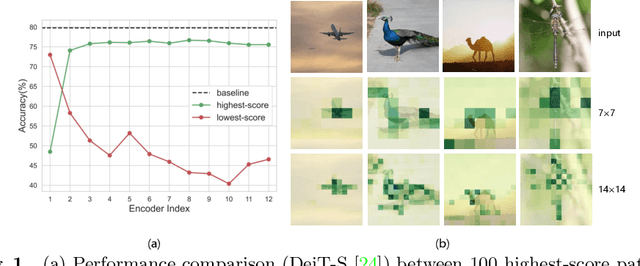
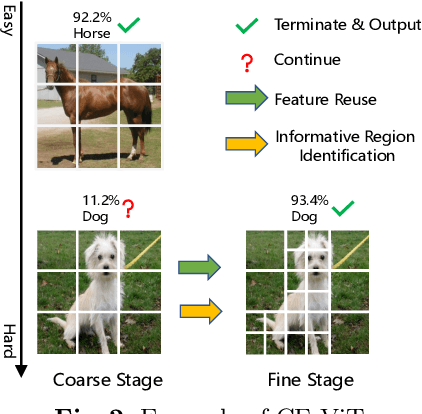
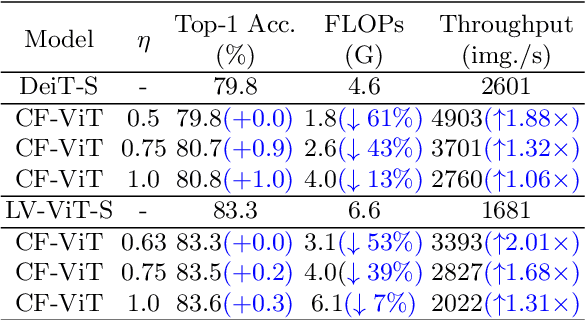
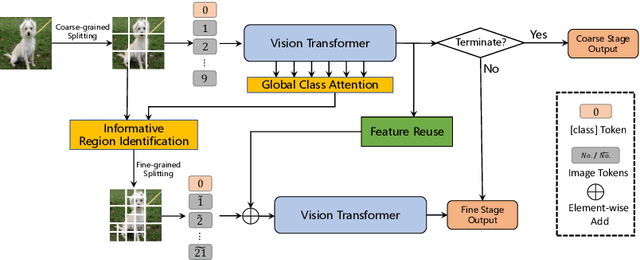
Vision Transformers (ViT) have made many breakthroughs in computer vision tasks. However, considerable redundancy arises in the spatial dimension of an input image, leading to massive computational costs. Therefore, We propose a coarse-to-fine vision transformer (CF-ViT) to relieve computational burden while retaining performance in this paper. Our proposed CF-ViT is motivated by two important observations in modern ViT models: (1) The coarse-grained patch splitting can locate informative regions of an input image. (2) Most images can be well recognized by a ViT model in a small-length token sequence. Therefore, our CF-ViT implements network inference in a two-stage manner. At coarse inference stage, an input image is split into a small-length patch sequence for a computationally economical classification. If not well recognized, the informative patches are identified and further re-split in a fine-grained granularity. Extensive experiments demonstrate the efficacy of our CF-ViT. For example, without any compromise on performance, CF-ViT reduces 53% FLOPs of LV-ViT, and also achieves 2.01x throughput.
Pruning Networks with Cross-Layer Ranking & k-Reciprocal Nearest Filters
Feb 15, 2022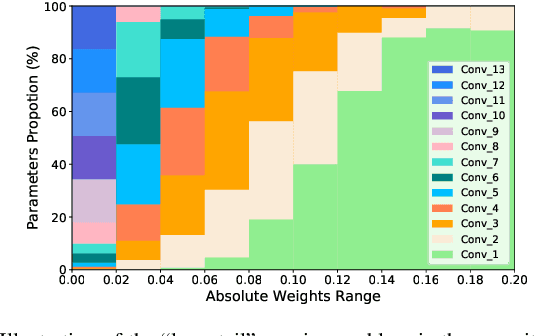
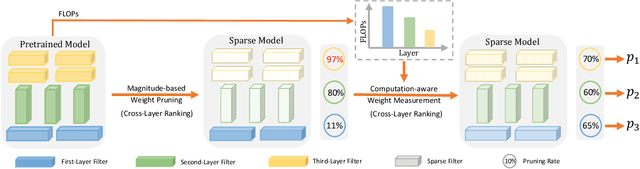
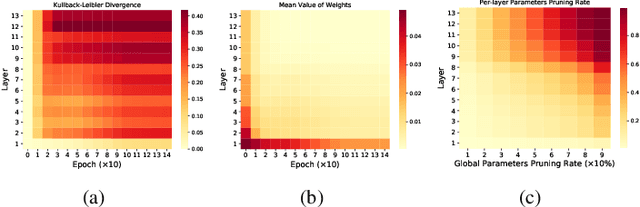
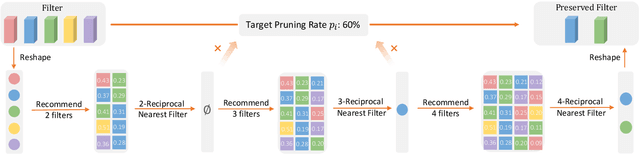
This paper focuses on filter-level network pruning. A novel pruning method, termed CLR-RNF, is proposed. We first reveal a "long-tail" long-tail pruning problem in magnitude-based weight pruning methods, and then propose a computation-aware measurement for individual weight importance, followed by a Cross-Layer Ranking (CLR) of weights to identify and remove the bottom-ranked weights. Consequently, the per-layer sparsity makes up of the pruned network structure in our filter pruning. Then, we introduce a recommendation-based filter selection scheme where each filter recommends a group of its closest filters. To pick the preserved filters from these recommended groups, we further devise a k-Reciprocal Nearest Filter (RNF) selection scheme where the selected filters fall into the intersection of these recommended groups. Both our pruned network structure and the filter selection are non-learning processes, which thus significantly reduce the pruning complexity, and differentiate our method from existing works. We conduct image classification on CIFAR-10 and ImageNet to demonstrate the superiority of our CLR-RNF over the state-of-the-arts. For example, on CIFAR-10, CLR-RNF removes 74.1% FLOPs and 95.0% parameters from VGGNet-16 with even 0.3\% accuracy improvements. On ImageNet, it removes 70.2% FLOPs and 64.8% parameters from ResNet-50 with only 1.7% top-5 accuracy drops. Our project is at https://github.com/lmbxmu/CLR-RNF.
Optimizing Gradient-driven Criteria in Network Sparsity: Gradient is All You Need
Jan 30, 2022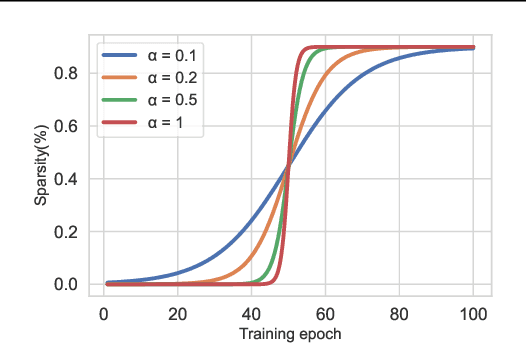
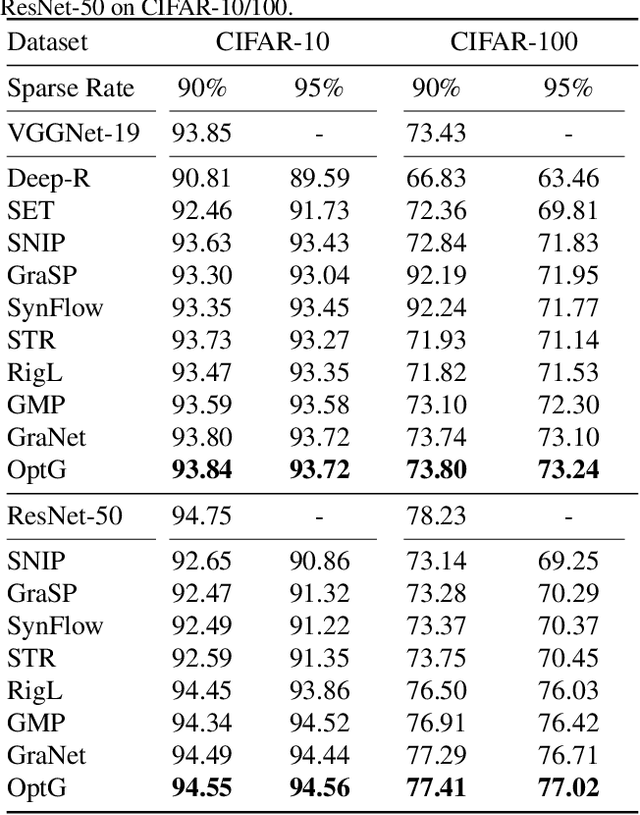
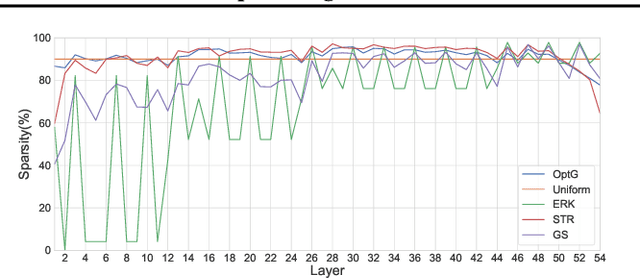
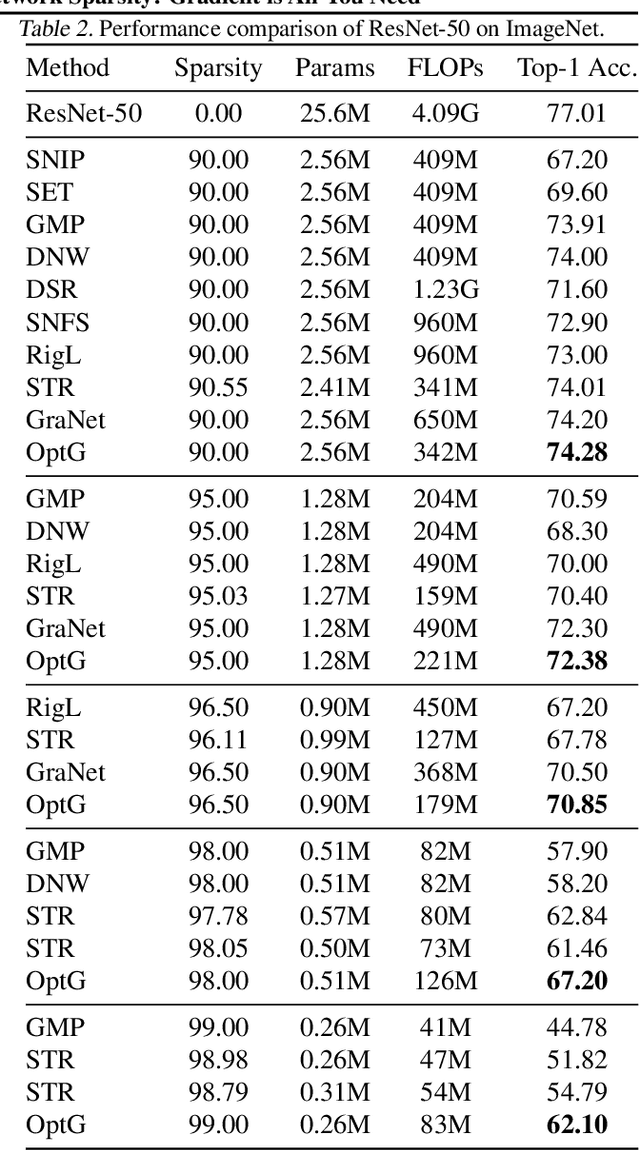
Network sparsity receives popularity mostly due to its capability to reduce the network complexity. Extensive studies excavate gradient-driven sparsity. Typically, these methods are constructed upon premise of weight independence, which however, is contrary to the fact that weights are mutually influenced. Thus, their performance remains to be improved. In this paper, we propose to further optimize gradient-driven sparsity (OptG) by solving this independence paradox. Our motive comes from the recent advances on supermask training which shows that sparse subnetworks can be located in a randomly initialized network by simply updating mask values without modifying any weight. We prove that supermask training is to accumulate the weight gradients and can partly solve the independence paradox. Consequently, OptG integrates supermask training into gradient-driven sparsity, and a specialized mask optimizer is designed to solve the independence paradox. Experiments show that OptG can well surpass many existing state-of-the-art competitors. Our code is available at \url{https://github.com/zyxxmu/OptG}.