 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategory-Aware Dynamic Label Assignment with High-Quality Oriented Proposal
Jul 03, 2024



Objects in aerial images are typically embedded in complex backgrounds and exhibit arbitrary orientations. When employing oriented bounding boxes (OBB) to represent arbitrary oriented objects, the periodicity of angles could lead to discontinuities in label regression values at the boundaries, inducing abrupt fluctuations in the loss function. To address this problem, an OBB representation based on the complex plane is introduced in the oriented detection framework, and a trigonometric loss function is proposed. Moreover, leveraging prior knowledge of complex background environments and significant differences in large objects in aerial images, a conformer RPN head is constructed to predict angle information. The proposed loss function and conformer RPN head jointly generate high-quality oriented proposals. A category-aware dynamic label assignment based on predicted category feedback is proposed to address the limitations of solely relying on IoU for proposal label assignment. This method makes negative sample selection more representative, ensuring consistency between classification and regression features. Experiments were conducted on four realistic oriented detection datasets, and the results demonstrate superior performance in oriented object detection with minimal parameter tuning and time costs. Specifically, mean average precision (mAP) scores of 82.02%, 71.99%, 69.87%, and 98.77% were achieved on the DOTA-v1.0, DOTA-v1.5, DIOR-R, and HRSC2016 datasets, respectively.
Breaking Language Barriers: Cross-Lingual Continual Pre-Training at Scale
Jul 02, 2024



In recent years, Large Language Models (LLMs) have made significant strides towards Artificial General Intelligence. However, training these models from scratch requires substantial computational resources and vast amounts of text data. In this paper, we explore an alternative approach to constructing an LLM for a new language by continually pretraining (CPT) from existing pretrained LLMs, instead of using randomly initialized parameters. Based on parallel experiments on 40 model sizes ranging from 40M to 5B parameters, we find that 1) CPT converges faster and saves significant resources in a scalable manner; 2) CPT adheres to an extended scaling law derived from Hoffmann et al. (2022) with a joint data-parameter scaling term; 3) The compute-optimal data-parameter allocation for CPT markedly differs based on our estimated scaling factors; 4) The effectiveness of transfer at scale is influenced by training duration and linguistic properties, while robust to data replaying, a method that effectively mitigates catastrophic forgetting in CPT. We hope our findings provide deeper insights into the transferability of LLMs at scale for the research community.
TCAN: Text-oriented Cross Attention Network for Multimodal Sentiment Analysis
Apr 06, 2024



Multimodal Sentiment Analysis (MSA) endeavors to understand human sentiment by leveraging language, visual, and acoustic modalities. Despite the remarkable performance exhibited by previous MSA approaches, the presence of inherent multimodal heterogeneities poses a challenge, with the contribution of different modalities varying considerably. Past research predominantly focused on improving representation learning techniques and feature fusion strategies. However, many of these efforts overlooked the variation in semantic richness among different modalities, treating each modality uniformly. This approach may lead to underestimating the significance of strong modalities while overemphasizing the importance of weak ones. Motivated by these insights, we introduce a Text-oriented Cross-Attention Network (TCAN), emphasizing the predominant role of the text modality in MSA. Specifically, for each multimodal sample, by taking unaligned sequences of the three modalities as inputs, we initially allocate the extracted unimodal features into a visual-text and an acoustic-text pair. Subsequently, we implement self-attention on the text modality and apply text-queried cross-attention to the visual and acoustic modalities. To mitigate the influence of noise signals and redundant features, we incorporate a gated control mechanism into the framework. Additionally, we introduce unimodal joint learning to gain a deeper understanding of homogeneous emotional tendencies across diverse modalities through backpropagation. Experimental results demonstrate that TCAN consistently outperforms state-of-the-art MSA methods on two datasets (CMU-MOSI and CMU-MOSEI).
Building Open-Ended Embodied Agent via Language-Policy Bidirectional Adaptation
Dec 12, 2023Building open-ended learning agents involves challenges in pre-trained language model (LLM) and reinforcement learning (RL) approaches. LLMs struggle with context-specific real-time interactions, while RL methods face efficiency issues for exploration. To this end, we propose OpenContra, a co-training framework that cooperates LLMs and GRL to construct an open-ended agent capable of comprehending arbitrary human instructions. The implementation comprises two stages: (1) fine-tuning an LLM to translate human instructions into structured goals, and curriculum training a goal-conditioned RL policy to execute arbitrary goals; (2) collaborative training to make the LLM and RL policy learn to adapt each, achieving open-endedness on instruction space. We conduct experiments on Contra, a battle royale FPS game with a complex and vast goal space. The results show that an agent trained with OpenContra comprehends arbitrary human instructions and completes goals with a high completion ratio, which proves that OpenContra may be the first practical solution for constructing open-ended embodied agents.
LLMaAA: Making Large Language Models as Active Annotators
Oct 31, 2023



Prevalent supervised learning methods in natural language processing (NLP) are notoriously data-hungry, which demand large amounts of high-quality annotated data. In practice, acquiring such data is a costly endeavor. Recently, the superior few-shot performance of large language models (LLMs) has propelled the development of dataset generation, where the training data are solely synthesized from LLMs. However, such an approach usually suffers from low-quality issues, and requires orders of magnitude more labeled data to achieve satisfactory performance. To fully exploit the potential of LLMs and make use of massive unlabeled data, we propose LLMaAA, which takes LLMs as annotators and puts them into an active learning loop to determine what to annotate efficiently. To learn robustly with pseudo labels, we optimize both the annotation and training processes: (1) we draw k-NN examples from a small demonstration pool as in-context examples, and (2) we adopt the example reweighting technique to assign training samples with learnable weights. Compared with previous approaches, LLMaAA features both efficiency and reliability. We conduct experiments and analysis on two classic NLP tasks, named entity recognition and relation extraction. With LLMaAA, task-specific models trained from LLM-generated labels can outperform the teacher within only hundreds of annotated examples, which is much more cost-effective than other baselines.
Two is Better Than One: Answering Complex Questions by Multiple Knowledge Sources with Generalized Links
Sep 11, 2023



Incorporating multiple knowledge sources is proven to be beneficial for answering complex factoid questions. To utilize multiple knowledge bases (KB), previous works merge all KBs into a single graph via entity alignment and reduce the problem to question-answering (QA) over the fused KB. In reality, various link relations between KBs might be adopted in QA over multi-KBs. In addition to the identity between the alignable entities (i.e. full link), unalignable entities expressing the different aspects or types of an abstract concept may also be treated identical in a question (i.e. partial link). Hence, the KB fusion in prior works fails to represent all types of links, restricting their ability to comprehend multi-KBs for QA. In this work, we formulate the novel Multi-KB-QA task that leverages the full and partial links among multiple KBs to derive correct answers, a benchmark with diversified link and query types is also constructed to efficiently evaluate Multi-KB-QA performance. Finally, we propose a method for Multi-KB-QA that encodes all link relations in the KB embedding to score and rank candidate answers. Experiments show that our method markedly surpasses conventional KB-QA systems in Multi-KB-QA, justifying the necessity of devising this task.
On Realization of Intelligent Decision-Making in the Real World: A Foundation Decision Model Perspective
Dec 24, 2022Our situated environment is full of uncertainty and highly dynamic, thus hindering the widespread adoption of machine-led Intelligent Decision-Making (IDM) in real world scenarios. This means IDM should have the capability of continuously learning new skills and efficiently generalizing across wider applications. IDM benefits from any new approaches and theoretical breakthroughs that exhibit Artificial General Intelligence (AGI) breaking the barriers between tasks and applications. Recent research has well-examined neural architecture, Transformer, as a backbone foundation model and its generalization to various tasks, including computer vision, natural language processing, and reinforcement learning. We therefore argue that a foundation decision model (FDM) can be established by formulating various decision-making tasks as a sequence decoding task using the Transformer architecture; this would be a promising solution to advance the applications of IDM in more complex real world tasks. In this paper, we elaborate on how a foundation decision model improves the efficiency and generalization of IDM. We also discuss potential applications of a FDM in multi-agent game AI, production scheduling, and robotics tasks. Finally, through a case study, we demonstrate our realization of the FDM, DigitalBrain (DB1) with 1.2 billion parameters, which achieves human-level performance over 453 tasks, including text generation, images caption, video games playing, robotic control, and traveling salesman problems. As a foundation decision model, DB1 would be a baby step towards more autonomous and efficient real world IDM applications.
Instance Regularization for Discriminative Language Model Pre-training
Oct 11, 2022
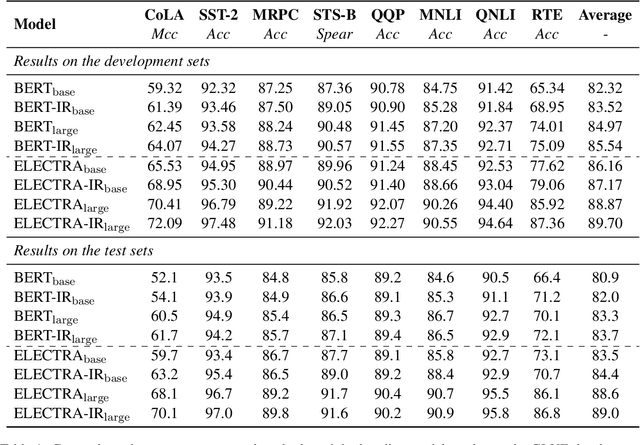
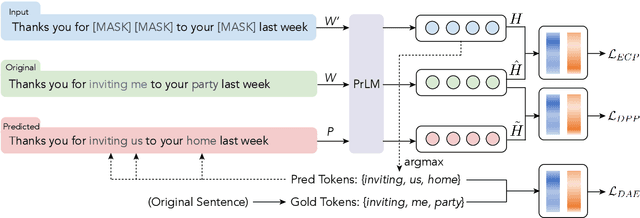
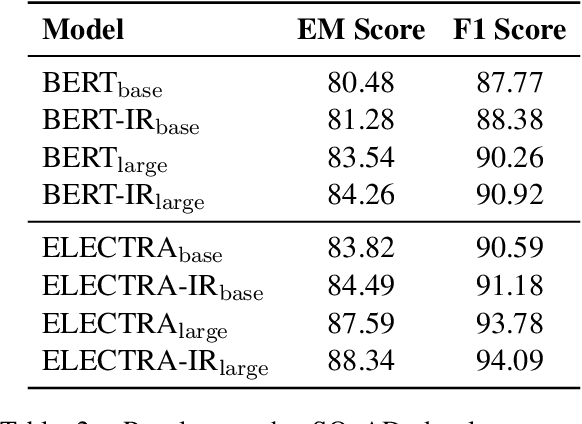
Discriminative pre-trained language models (PrLMs) can be generalized as denoising auto-encoders that work with two procedures, ennoising and denoising. First, an ennoising process corrupts texts with arbitrary noising functions to construct training instances. Then, a denoising language model is trained to restore the corrupted tokens. Existing studies have made progress by optimizing independent strategies of either ennoising or denosing. They treat training instances equally throughout the training process, with little attention on the individual contribution of those instances. To model explicit signals of instance contribution, this work proposes to estimate the complexity of restoring the original sentences from corrupted ones in language model pre-training. The estimations involve the corruption degree in the ennoising data construction process and the prediction confidence in the denoising counterpart. Experimental results on natural language understanding and reading comprehension benchmarks show that our approach improves pre-training efficiency, effectiveness, and robustness. Code is publicly available at https://github.com/cooelf/InstanceReg
HORIZON: A High-Resolution Panorama Synthesis Framework
Oct 10, 2022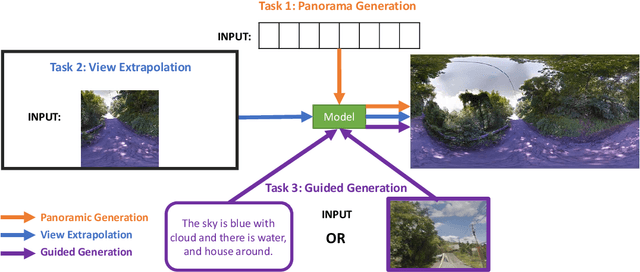
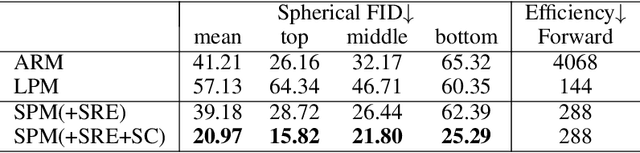
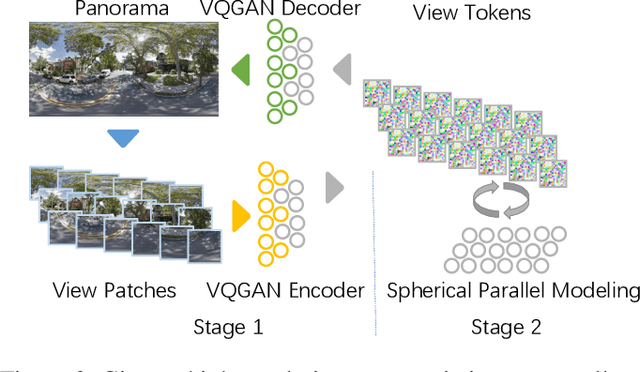

Panorama synthesis aims to generate a visual scene with all 360-degree views and enables an immersive virtual world. If the panorama synthesis process can be semantically controlled, we can then build an interactive virtual world and form an unprecedented human-computer interaction experience. Existing panoramic synthesis methods mainly focus on dealing with the inherent challenges brought by panoramas' spherical structure such as the projection distortion and the in-continuity problem when stitching edges, but is hard to effectively control semantics. The recent success of visual synthesis like DALL.E generates promising 2D flat images with semantic control, however, it is hard to directly be applied to panorama synthesis which inevitably generates distorted content. Besides, both of the above methods can not effectively synthesize high-resolution panoramas either because of quality or inference speed. In this work, we propose a new generation framework for high-resolution panorama images. The contributions include 1) alleviating the spherical distortion and edge in-continuity problem through spherical modeling, 2) supporting semantic control through both image and text hints, and 3) effectively generating high-resolution panoramas through parallel decoding. Our experimental results on a large-scale high-resolution Street View dataset validated the superiority of our approach quantitatively and qualitatively.
Pre-Training a Graph Recurrent Network for Language Representation
Sep 08, 2022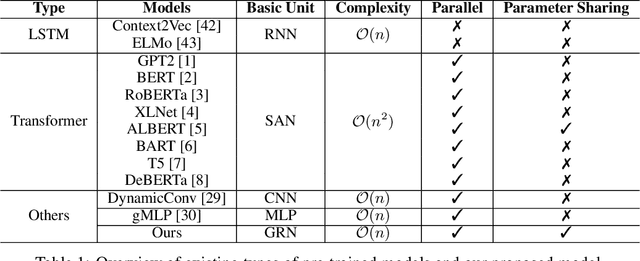
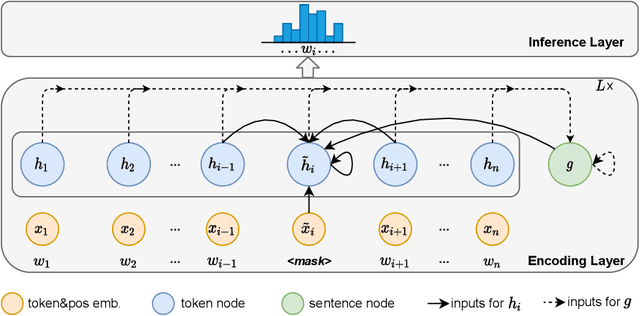
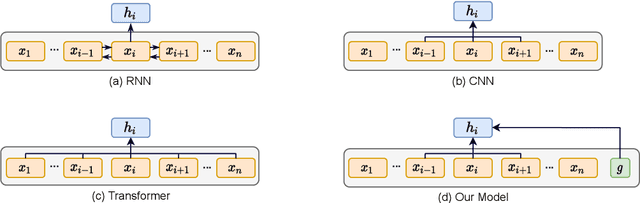
Transformer-based pre-trained models have gained much advance in recent years, becoming one of the most important backbones in natural language processing. Recent work shows that the attention mechanism inside Transformer may not be necessary, both convolutional neural networks and multi-layer perceptron based models have also been investigated as Transformer alternatives. In this paper, we consider a graph recurrent network for language model pre-training, which builds a graph structure for each sequence with local token-level communications, together with a sentence-level representation decoupled from other tokens. The original model performs well in domain-specific text classification under supervised training, however, its potential in learning transfer knowledge by self-supervised way has not been fully exploited. We fill this gap by optimizing the architecture and verifying its effectiveness in more general language understanding tasks, for both English and Chinese languages. As for model efficiency, instead of the quadratic complexity in Transformer-based models, our model has linear complexity and performs more efficiently during inference. Moreover, we find that our model can generate more diverse outputs with less contextualized feature redundancy than existing attention-based models.