 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronoMedicalWorld: A Medical World Model for Learning Patient Trajectories from Longitudinal Care Data
May 21, 2026Long-horizon clinical simulation -- predicting how a patient's physiology evolves over years under specified interventions -- is central to chronic-disease care, yet existing electronic health record (EHR) models are predominantly discriminative, and general-purpose large language models drift under repeated interventions. We propose the \textbf{ChronoMedicalWorld Model (CMWM)}, an action-conditioned latent world-model framework for learning patient trajectories from longitudinal care data. CMWM couples a joint-embedding state encoder with a wide action encoder that admits both structured intervention indicators and free-text communication embeddings, and trains a recurrent latent transition module under a six-term objective: next-observation supervision, next-latent prediction, SIGReg latent regularisation, and three physiology-aware shape priors (slope, continuity, large-jump penalty). A closed-loop rollout-prefix protocol matches training to deployment, so the model is optimised against the same multi-step error it exhibits at inference. As a concrete case study, we instantiate CMWM for annual estimated glomerular filtration rate (eGFR) trajectory forecasting in chronic kidney disease (CKD). On a 2{,}232-patient nephrology cohort, the CKD instantiation achieves a dynamic-50\% history rollout test mean absolute error (MAE) of 7.384 and root-mean-square error (RMSE) of 10.256, against 7.964 and 11.069 for a tuned GPT-5.5 structured-prompting baseline ($-7.28\%$ MAE, $-7.35\%$ RMSE), with the gain dominated by the dialogue portion of patient--health-coach communication. The framework is not CKD-specific: its architecture, loss design, and training protocol apply to any chronic condition that can be cast as periodic clinical state interleaved with structured and conversational interventions.
Breaking Language Barriers: Cross-Lingual Continual Pre-Training at Scale
Jul 02, 2024



In recent years, Large Language Models (LLMs) have made significant strides towards Artificial General Intelligence. However, training these models from scratch requires substantial computational resources and vast amounts of text data. In this paper, we explore an alternative approach to constructing an LLM for a new language by continually pretraining (CPT) from existing pretrained LLMs, instead of using randomly initialized parameters. Based on parallel experiments on 40 model sizes ranging from 40M to 5B parameters, we find that 1) CPT converges faster and saves significant resources in a scalable manner; 2) CPT adheres to an extended scaling law derived from Hoffmann et al. (2022) with a joint data-parameter scaling term; 3) The compute-optimal data-parameter allocation for CPT markedly differs based on our estimated scaling factors; 4) The effectiveness of transfer at scale is influenced by training duration and linguistic properties, while robust to data replaying, a method that effectively mitigates catastrophic forgetting in CPT. We hope our findings provide deeper insights into the transferability of LLMs at scale for the research community.
A Systematic Collection of Medical Image Datasets for Deep Learning
Jun 24, 2021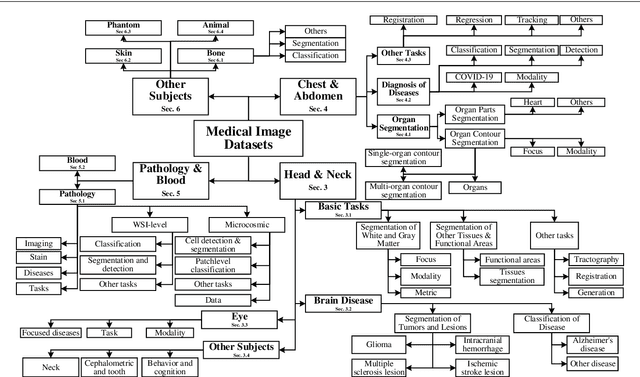
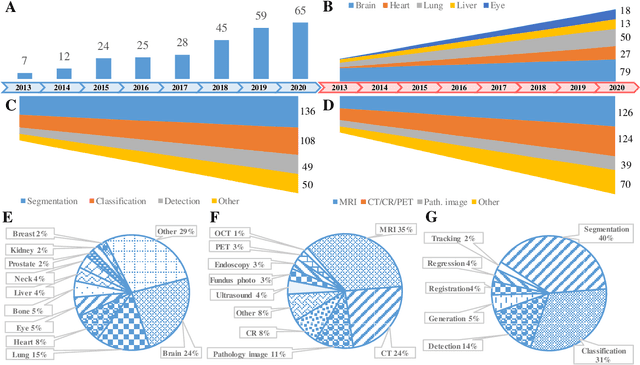
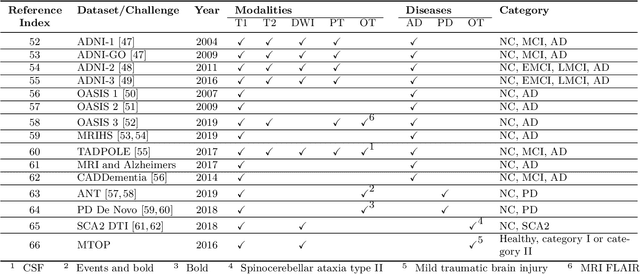
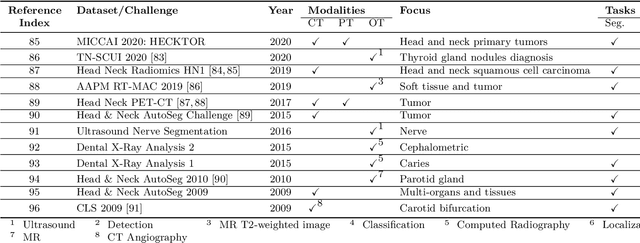
The astounding success made by artificial intelligence (AI) in healthcare and other fields proves that AI can achieve human-like performance. However, success always comes with challenges. Deep learning algorithms are data-dependent and require large datasets for training. The lack of data in the medical imaging field creates a bottleneck for the application of deep learning to medical image analysis. Medical image acquisition, annotation, and analysis are costly, and their usage is constrained by ethical restrictions. They also require many resources, such as human expertise and funding. That makes it difficult for non-medical researchers to have access to useful and large medical data. Thus, as comprehensive as possible, this paper provides a collection of medical image datasets with their associated challenges for deep learning research. We have collected information of around three hundred datasets and challenges mainly reported between 2013 and 2020 and categorized them into four categories: head & neck, chest & abdomen, pathology & blood, and ``others''. Our paper has three purposes: 1) to provide a most up to date and complete list that can be used as a universal reference to easily find the datasets for clinical image analysis, 2) to guide researchers on the methodology to test and evaluate their methods' performance and robustness on relevant datasets, 3) to provide a ``route'' to relevant algorithms for the relevant medical topics, and challenge leaderboards.
Toward Marker-free 3D Pose Estimation in Lifting: A Deep Multi-view Solution
Feb 06, 2018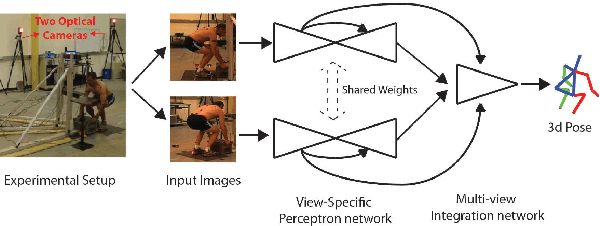
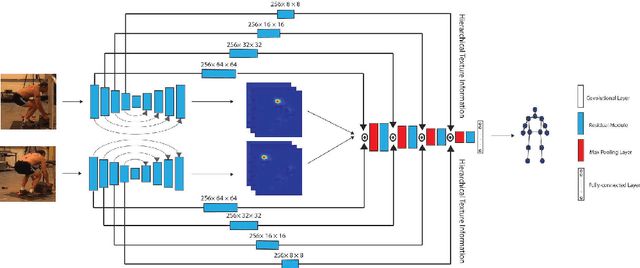
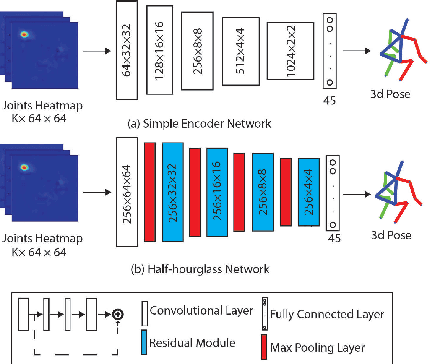
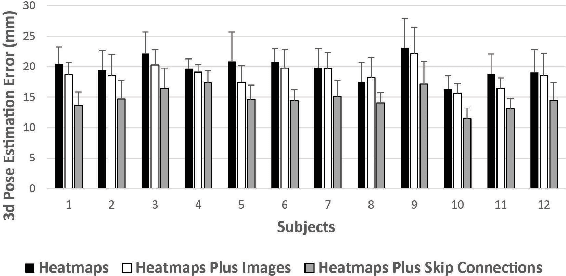
Lifting is a common manual material handling task performed in the workplaces. It is considered as one of the main risk factors for Work-related Musculoskeletal Disorders. To improve work place safety, it is necessary to assess musculoskeletal and biomechanical risk exposures associated with these tasks, which requires very accurate 3D pose. Existing approaches mainly utilize marker-based sensors to collect 3D information. However, these methods are usually expensive to setup, time-consuming in process, and sensitive to the surrounding environment. In this study, we propose a multi-view based deep perceptron approach to address aforementioned limitations. Our approach consists of two modules: a "view-specific perceptron" network extracts rich information independently from the image of view, which includes both 2D shape and hierarchical texture information; while a "multi-view integration" network synthesizes information from all available views to predict accurate 3D pose. To fully evaluate our approach, we carried out comprehensive experiments to compare different variants of our design. The results prove that our approach achieves comparable performance with former marker-based methods, i.e. an average error of $14.72 \pm 2.96$ mm on the lifting dataset. The results are also compared with state-of-the-art methods on HumanEva-I dataset, which demonstrates the superior performance of our approach.
Beam Search for Learning a Deep Convolutional Neural Network of 3D Shapes
Dec 14, 2016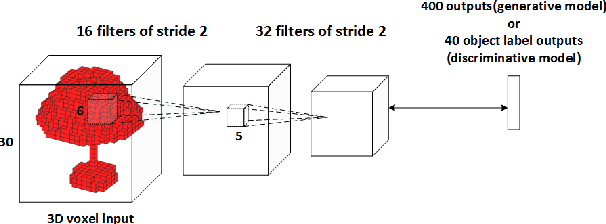
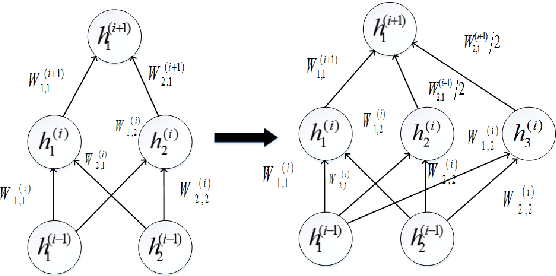
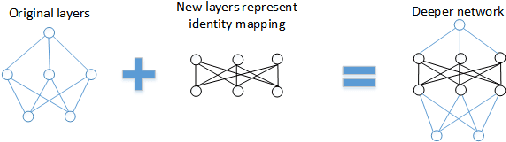
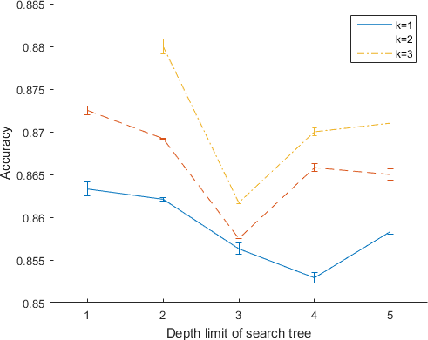
This paper addresses 3D shape recognition. Recent work typically represents a 3D shape as a set of binary variables corresponding to 3D voxels of a uniform 3D grid centered on the shape, and resorts to deep convolutional neural networks(CNNs) for modeling these binary variables. Robust learning of such CNNs is currently limited by the small datasets of 3D shapes available, an order of magnitude smaller than other common datasets in computer vision. Related work typically deals with the small training datasets using a number of ad hoc, hand-tuning strategies. To address this issue, we formulate CNN learning as a beam search aimed at identifying an optimal CNN architecture, namely, the number of layers, nodes, and their connectivity in the network, as well as estimating parameters of such an optimal CNN. Each state of the beam search corresponds to a candidate CNN. Two types of actions are defined to add new convolutional filters or new convolutional layers to a parent CNN, and thus transition to children states. The utility function of each action is efficiently computed by transferring parameter values of the parent CNN to its children, thereby enabling an efficient beam search. Our experimental evaluation on the 3D ModelNet dataset demonstrates that our model pursuit using the beam search yields a CNN with superior performance on 3D shape classification than the state of the art.