 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Model as Simulated Patients for Clinical Education
Apr 25, 2024



Simulated Patients (SPs) play a crucial role in clinical medical education by providing realistic scenarios for student practice. However, the high cost of training and hiring qualified SPs, along with the heavy workload and potential risks they face in consistently portraying actual patients, limit students' access to this type of clinical training. Consequently, the integration of computer program-based simulated patients has emerged as a valuable educational tool in recent years. With the rapid development of Large Language Models (LLMs), their exceptional capabilities in conversational artificial intelligence and role-playing have been demonstrated, making them a feasible option for implementing Virtual Simulated Patient (VSP). In this paper, we present an integrated model-agnostic framework called CureFun that harnesses the potential of LLMs in clinical medical education. This framework facilitates natural conversations between students and simulated patients, evaluates their dialogue, and provides suggestions to enhance students' clinical inquiry skills. Through comprehensive evaluations, our approach demonstrates more authentic and professional SP-scenario dialogue flows compared to other LLM-based chatbots, thus proving its proficiency in simulating patients. Additionally, leveraging CureFun's evaluation ability, we assess several medical LLMs and discuss the possibilities and limitations of using LLMs as virtual doctors from the perspective of their diagnostic abilities.
Two is Better Than One: Answering Complex Questions by Multiple Knowledge Sources with Generalized Links
Sep 11, 2023



Incorporating multiple knowledge sources is proven to be beneficial for answering complex factoid questions. To utilize multiple knowledge bases (KB), previous works merge all KBs into a single graph via entity alignment and reduce the problem to question-answering (QA) over the fused KB. In reality, various link relations between KBs might be adopted in QA over multi-KBs. In addition to the identity between the alignable entities (i.e. full link), unalignable entities expressing the different aspects or types of an abstract concept may also be treated identical in a question (i.e. partial link). Hence, the KB fusion in prior works fails to represent all types of links, restricting their ability to comprehend multi-KBs for QA. In this work, we formulate the novel Multi-KB-QA task that leverages the full and partial links among multiple KBs to derive correct answers, a benchmark with diversified link and query types is also constructed to efficiently evaluate Multi-KB-QA performance. Finally, we propose a method for Multi-KB-QA that encodes all link relations in the KB embedding to score and rank candidate answers. Experiments show that our method markedly surpasses conventional KB-QA systems in Multi-KB-QA, justifying the necessity of devising this task.
ADMUS: A Progressive Question Answering Framework Adaptable to Multiple Knowledge Sources
Aug 09, 2023With the introduction of deep learning models, semantic parsingbased knowledge base question answering (KBQA) systems have achieved high performance in handling complex questions. However, most existing approaches primarily focus on enhancing the model's effectiveness on individual benchmark datasets, disregarding the high costs of adapting the system to disparate datasets in real-world scenarios (e.g., multi-tenant platform). Therefore, we present ADMUS, a progressive knowledge base question answering framework designed to accommodate a wide variety of datasets, including multiple languages, diverse backbone knowledge bases, and disparate question answering datasets. To accomplish the purpose, we decouple the architecture of conventional KBQA systems and propose this dataset-independent framework. Our framework supports the seamless integration of new datasets with minimal effort, only requiring creating a dataset-related micro-service at a negligible cost. To enhance the usability of ADUMS, we design a progressive framework consisting of three stages, ranges from executing exact queries, generating approximate queries and retrieving open-domain knowledge referring from large language models. An online demonstration of ADUMS is available at: https://answer.gstore.cn/pc/index.html
Joint Channel Estimation and Turbo Equalization of Single-Carrier Systems over Time-Varying Channels
May 16, 2023



Block transmission systems have been proven successful over frequency-selective channels. For time-varying channel such as in high-speed mobile communication and underwater communication, existing equalizers assume that channels over different data frames are independent. However, the real-world channels over different data frames are correlated, thereby indicating potentials for performance improvement. In this paper, we propose a joint channel estimation and equalization/decoding algorithm for a single-carrier system that exploits temporal correlations of channel between transmitted data frames. Leveraging the concept of dynamic compressive sensing, our method can utilize the information of several data frames to achieve better performance. The information not only passes between the channel and symbol, but also the channels over different data frames. Numerical simulations using an extensively validated underwater acoustic model with a time-varying channel establish that the proposed algorithm outperforms the former bilinear generalized approximate message passing equalizer and classic minimum mean square error turbo equalizer in bit error rate and channel estimation normalized mean square error. The algorithm idea we present can also find applications in other bilinear multiple measurements vector compressive sensing problems.
Crake: Causal-Enhanced Table-Filler for Question Answering over Large Scale Knowledge Base
Jul 08, 2022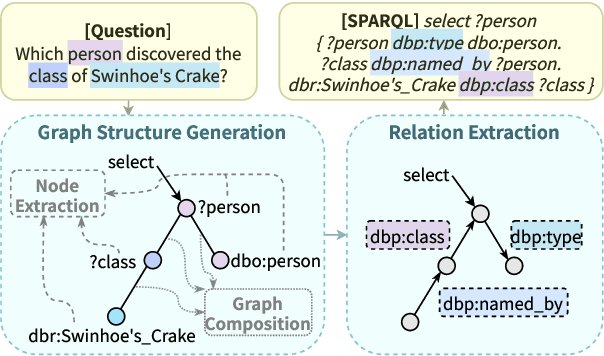

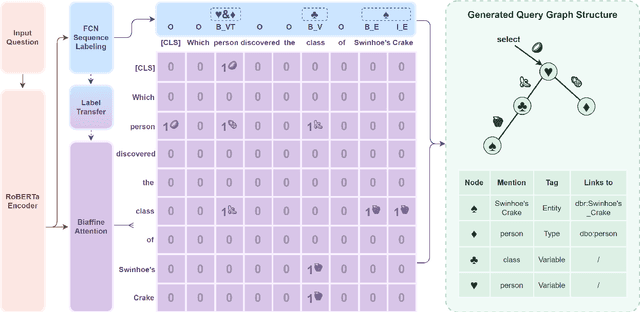
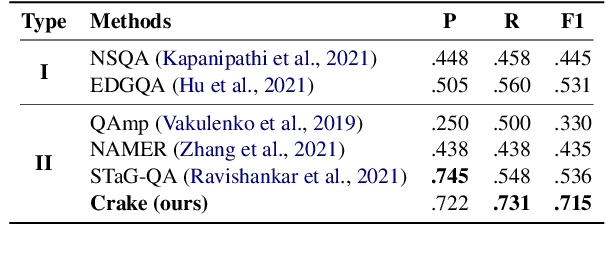
Semantic parsing solves knowledge base (KB) question answering (KBQA) by composing a KB query, which generally involves node extraction (NE) and graph composition (GC) to detect and connect related nodes in a query. Despite the strong causal effects between NE and GC, previous works fail to directly model such causalities in their pipeline, hindering the learning of subtask correlations. Also, the sequence-generation process for GC in previous works induces ambiguity and exposure bias, which further harms accuracy. In this work, we formalize semantic parsing into two stages. In the first stage (graph structure generation), we propose a causal-enhanced table-filler to overcome the issues in sequence-modelling and to learn the internal causalities. In the second stage (relation extraction), an efficient beam-search algorithm is presented to scale complex queries on large-scale KBs. Experiments on LC-QuAD 1.0 indicate that our method surpasses previous state-of-the-arts by a large margin (17%) while remaining time and space efficiency. The code and models are available at https://github.com/AOZMH/Crake.
Overview of the CCKS 2019 Knowledge Graph Evaluation Track: Entity, Relation, Event and QA
Mar 09, 2020Knowledge graph models world knowledge as concepts, entities, and the relationships between them, which has been widely used in many real-world tasks. CCKS 2019 held an evaluation track with 6 tasks and attracted more than 1,600 teams. In this paper, we give an overview of the knowledge graph evaluation tract at CCKS 2019. By reviewing the task definition, successful methods, useful resources, good strategies and research challenges associated with each task in CCKS 2019, this paper can provide a helpful reference for developing knowledge graph applications and conducting future knowledge graph researches.