 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Open-Ended Embodied Agent via Language-Policy Bidirectional Adaptation
Dec 12, 2023Building open-ended learning agents involves challenges in pre-trained language model (LLM) and reinforcement learning (RL) approaches. LLMs struggle with context-specific real-time interactions, while RL methods face efficiency issues for exploration. To this end, we propose OpenContra, a co-training framework that cooperates LLMs and GRL to construct an open-ended agent capable of comprehending arbitrary human instructions. The implementation comprises two stages: (1) fine-tuning an LLM to translate human instructions into structured goals, and curriculum training a goal-conditioned RL policy to execute arbitrary goals; (2) collaborative training to make the LLM and RL policy learn to adapt each, achieving open-endedness on instruction space. We conduct experiments on Contra, a battle royale FPS game with a complex and vast goal space. The results show that an agent trained with OpenContra comprehends arbitrary human instructions and completes goals with a high completion ratio, which proves that OpenContra may be the first practical solution for constructing open-ended embodied agents.
Spreeze: High-Throughput Parallel Reinforcement Learning Framework
Dec 11, 2023



The promotion of large-scale applications of reinforcement learning (RL) requires efficient training computation. While existing parallel RL frameworks encompass a variety of RL algorithms and parallelization techniques, the excessively burdensome communication frameworks hinder the attainment of the hardware's limit for final throughput and training effects on a single desktop. In this paper, we propose Spreeze, a lightweight parallel framework for RL that efficiently utilizes a single desktop hardware resource to approach the throughput limit. We asynchronously parallelize the experience sampling, network update, performance evaluation, and visualization operations, and employ multiple efficient data transmission techniques to transfer various types of data between processes. The framework can automatically adjust the parallelization hyperparameters based on the computing ability of the hardware device in order to perform efficient large-batch updates. Based on the characteristics of the "Actor-Critic" RL algorithm, our framework uses dual GPUs to independently update the network of actors and critics in order to further improve throughput. Simulation results show that our framework can achieve up to 15,000Hz experience sampling and 370,000Hz network update frame rate using only a personal desktop computer, which is an order of magnitude higher than other mainstream parallel RL frameworks, resulting in a 73% reduction of training time. Our work on fully utilizing the hardware resources of a single desktop computer is fundamental to enabling efficient large-scale distributed RL training.
Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition
Aug 05, 2022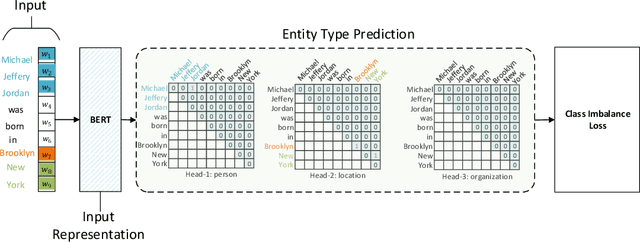
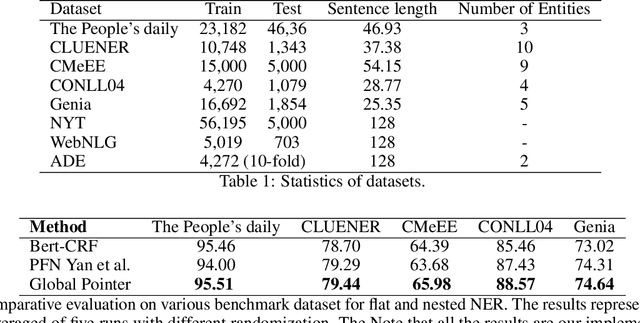
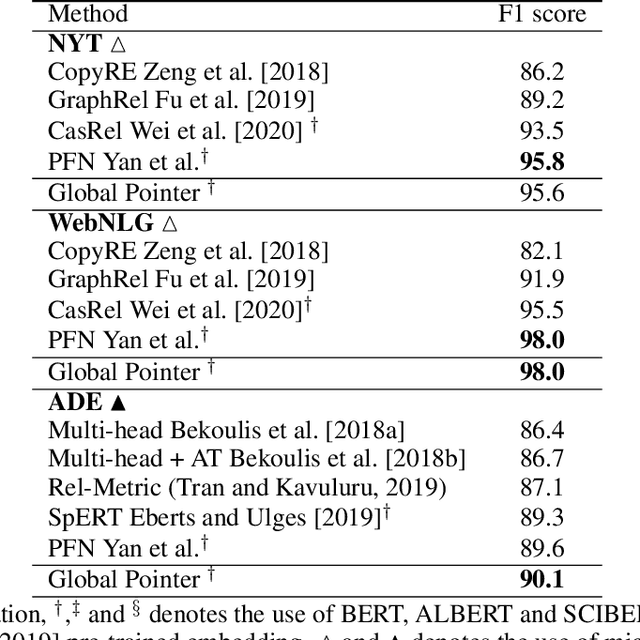

Named entity recognition (NER) task aims at identifying entities from a piece of text that belong to predefined semantic types such as person, location, organization, etc. The state-of-the-art solutions for flat entities NER commonly suffer from capturing the fine-grained semantic information in underlying texts. The existing span-based approaches overcome this limitation, but the computation time is still a concern. In this work, we propose a novel span-based NER framework, namely Global Pointer (GP), that leverages the relative positions through a multiplicative attention mechanism. The ultimate goal is to enable a global view that considers the beginning and the end positions to predict the entity. To this end, we design two modules to identify the head and the tail of a given entity to enable the inconsistency between the training and inference processes. Moreover, we introduce a novel classification loss function to address the imbalance label problem. In terms of parameters, we introduce a simple but effective approximate method to reduce the training parameters. We extensively evaluate GP on various benchmark datasets. Our extensive experiments demonstrate that GP can outperform the existing solution. Moreover, the experimental results show the efficacy of the introduced loss function compared to softmax and entropy alternatives.