 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLauraTSE: Target Speaker Extraction using Auto-Regressive Decoder-Only Language Models
Apr 10, 2025


We propose LauraTSE, an Auto-Regressive Decoder-Only Language Model for Target Speaker Extraction (TSE) based on the LauraGPT backbone. It employs a small-scale auto-regressive decoder-only language model which takes the continuous representations for both the mixture and the reference speeches and produces the first few layers of the target speech's discrete codec representations. In addition, a one-step encoder-only language model reconstructs the sum of the predicted codec embeddings using both the mixture and the reference information. Our approach achieves superior or comparable performance to existing generative and discriminative TSE models. To the best of our knowledge, LauraTSE is the first single-task TSE model to leverage an auto-regressive decoder-only language model as the backbone.
Missing Premise exacerbates Overthinking: Are Reasoning Models losing Critical Thinking Skill?
Apr 09, 2025We find that the response length of reasoning LLMs, whether trained by reinforcement learning or supervised learning, drastically increases for ill-posed questions with missing premises (MiP), ending up with redundant and ineffective thinking. This newly introduced scenario exacerbates the general overthinking issue to a large extent, which we name as the MiP-Overthinking. Such failures are against the ``test-time scaling law'' but have been widely observed on multiple datasets we curated with MiP, indicating the harm of cheap overthinking and a lack of critical thinking. Surprisingly, LLMs not specifically trained for reasoning exhibit much better performance on the MiP scenario, producing much shorter responses that quickly identify ill-posed queries. This implies a critical flaw of the current training recipe for reasoning LLMs, which does not encourage efficient thinking adequately, leading to the abuse of thinking patterns. To further investigate the reasons behind such failures, we conduct fine-grained analyses of the reasoning length, overthinking patterns, and location of critical thinking on different types of LLMs. Moreover, our extended ablation study reveals that the overthinking is contagious through the distillation of reasoning models' responses. These results improve the understanding of overthinking and shed novel insights into mitigating the problem.
Sensing-Oriented Adaptive Resource Allocation Designs for OFDM-ISAC Systems
Apr 09, 2025



Orthogonal frequency division multiplexing - integrated sensing and communication (OFDM-ISAC) has emerged as a key enabler for future wireless networks, leveraging the widely adopted OFDM waveform to seamlessly integrate wireless communication and radar sensing within a unified framework. In this paper, we propose adaptive resource allocation strategies for OFDM-ISAC systems to achieve optimal trade-offs between diverse sensing requirements and communication quality-of-service (QoS). We first develop a comprehensive resource allocation framework for OFDM-ISAC systems, deriving closed-form expressions for key sensing performance metrics, including delay resolution, Doppler resolution, delay-Doppler peak sidelobe level (PSL), and received signal-to-noise ratio (SNR). Building on this theoretical foundation, we introduce two novel resource allocation algorithms tailored to distinct sensing objectives. The resolution-oriented algorithm aims to maximize the weighted delay-Doppler resolution while satisfying constraints on PSL, sensing SNR, communication sum-rate, and transmit power. The sidelobe-oriented algorithm focuses on minimizing delay-Doppler PSL while satisfying resolution, SNR, and communication constraints. To efficiently solve the resulting non-convex optimization problems, we develop two adaptive resource allocation algorithms based on Dinkelbach's transform and majorization-minimization (MM). Extensive simulations validate the effectiveness of the proposed sensing-oriented adaptive resource allocation strategies in enhancing resolution and sidelobe suppression. Remarkably, these strategies achieve sensing performance nearly identical to that of a radar-only scheme, which dedicates all resources to sensing. These results highlight the superior performance of the proposed methods in optimizing the trade-off between sensing and communication objectives within OFDM-ISAC systems.
MDK12-Bench: A Multi-Discipline Benchmark for Evaluating Reasoning in Multimodal Large Language Models
Apr 08, 2025Multimodal reasoning, which integrates language and visual cues into problem solving and decision making, is a fundamental aspect of human intelligence and a crucial step toward artificial general intelligence. However, the evaluation of multimodal reasoning capabilities in Multimodal Large Language Models (MLLMs) remains inadequate. Most existing reasoning benchmarks are constrained by limited data size, narrow domain coverage, and unstructured knowledge distribution. To close these gaps, we introduce MDK12-Bench, a multi-disciplinary benchmark assessing the reasoning capabilities of MLLMs via real-world K-12 examinations. Spanning six disciplines (math, physics, chemistry, biology, geography, and information science), our benchmark comprises 140K reasoning instances across diverse difficulty levels from primary school to 12th grade. It features 6,827 instance-level knowledge point annotations based on a well-organized knowledge structure, detailed answer explanations, difficulty labels and cross-year partitions, providing a robust platform for comprehensive evaluation. Additionally, we present a novel dynamic evaluation framework to mitigate data contamination issues by bootstrapping question forms, question types, and image styles during evaluation. Extensive experiment on MDK12-Bench reveals the significant limitation of current MLLMs in multimodal reasoning. The findings on our benchmark provide insights into the development of the next-generation models. Our data and codes are available at https://github.com/LanceZPF/MDK12.
Towards Visual Text Grounding of Multimodal Large Language Model
Apr 07, 2025

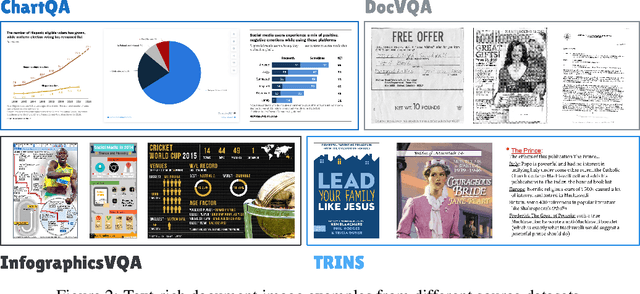

Despite the existing evolution of Multimodal Large Language Models (MLLMs), a non-neglectable limitation remains in their struggle with visual text grounding, especially in text-rich images of documents. Document images, such as scanned forms and infographics, highlight critical challenges due to their complex layouts and textual content. However, current benchmarks do not fully address these challenges, as they mostly focus on visual grounding on natural images, rather than text-rich document images. Thus, to bridge this gap, we introduce TRIG, a novel task with a newly designed instruction dataset for benchmarking and improving the Text-Rich Image Grounding capabilities of MLLMs in document question-answering. Specifically, we propose an OCR-LLM-human interaction pipeline to create 800 manually annotated question-answer pairs as a benchmark and a large-scale training set of 90$ synthetic data based on four diverse datasets. A comprehensive evaluation of various MLLMs on our proposed benchmark exposes substantial limitations in their grounding capability on text-rich images. In addition, we propose two simple and effective TRIG methods based on general instruction tuning and plug-and-play efficient embedding, respectively. By finetuning MLLMs on our synthetic dataset, they promisingly improve spatial reasoning and grounding capabilities.
Post-Incorporating Code Structural Knowledge into LLMs via In-Context Learning for Code Translation
Mar 28, 2025



Code translation migrates codebases across programming languages. Recently, large language models (LLMs) have achieved significant advancements in software mining. However, handling the syntactic structure of source code remains a challenge. Classic syntax-aware methods depend on intricate model architectures and loss functions, rendering their integration into LLM training resource-intensive. This paper employs in-context learning (ICL), which directly integrates task exemplars into the input context, to post-incorporate code structural knowledge into pre-trained LLMs. We revisit exemplar selection in ICL from an information-theoretic perspective, proposing that list-wise selection based on information coverage is more precise and general objective than traditional methods based on combining similarity and diversity. To address the challenges of quantifying information coverage, we introduce a surrogate measure, Coverage of Abstract Syntax Tree (CAST). Furthermore, we formulate the NP-hard CAST maximization for exemplar selection and prove that it is a standard submodular maximization problem. Therefore, we propose a greedy algorithm for CAST submodular maximization, which theoretically guarantees a (1-1/e)-approximate solution in polynomial time complexity. Our method is the first training-free and model-agnostic approach to post-incorporate code structural knowledge into existing LLMs at test time. Experimental results show that our method significantly improves LLMs performance and reveals two meaningful insights: 1) Code structural knowledge can be effectively post-incorporated into pre-trained LLMs during inference, despite being overlooked during training; 2) Scaling up model size or training data does not lead to the emergence of code structural knowledge, underscoring the necessity of explicitly considering code syntactic structure.
LeX-Art: Rethinking Text Generation via Scalable High-Quality Data Synthesis
Mar 27, 2025We introduce LeX-Art, a comprehensive suite for high-quality text-image synthesis that systematically bridges the gap between prompt expressiveness and text rendering fidelity. Our approach follows a data-centric paradigm, constructing a high-quality data synthesis pipeline based on Deepseek-R1 to curate LeX-10K, a dataset of 10K high-resolution, aesthetically refined 1024$\times$1024 images. Beyond dataset construction, we develop LeX-Enhancer, a robust prompt enrichment model, and train two text-to-image models, LeX-FLUX and LeX-Lumina, achieving state-of-the-art text rendering performance. To systematically evaluate visual text generation, we introduce LeX-Bench, a benchmark that assesses fidelity, aesthetics, and alignment, complemented by Pairwise Normalized Edit Distance (PNED), a novel metric for robust text accuracy evaluation. Experiments demonstrate significant improvements, with LeX-Lumina achieving a 79.81% PNED gain on CreateBench, and LeX-FLUX outperforming baselines in color (+3.18%), positional (+4.45%), and font accuracy (+3.81%). Our codes, models, datasets, and demo are publicly available.
Synthetic-to-Real Self-supervised Robust Depth Estimation via Learning with Motion and Structure Priors
Mar 26, 2025Self-supervised depth estimation from monocular cameras in diverse outdoor conditions, such as daytime, rain, and nighttime, is challenging due to the difficulty of learning universal representations and the severe lack of labeled real-world adverse data. Previous methods either rely on synthetic inputs and pseudo-depth labels or directly apply daytime strategies to adverse conditions, resulting in suboptimal results. In this paper, we present the first synthetic-to-real robust depth estimation framework, incorporating motion and structure priors to capture real-world knowledge effectively. In the synthetic adaptation, we transfer motion-structure knowledge inside cost volumes for better robust representation, using a frozen daytime model to train a depth estimator in synthetic adverse conditions. In the innovative real adaptation, which targets to fix synthetic-real gaps, models trained earlier identify the weather-insensitive regions with a designed consistency-reweighting strategy to emphasize valid pseudo-labels. We introduce a new regularization by gathering explicit depth distributions to constrain the model when facing real-world data. Experiments show that our method outperforms the state-of-the-art across diverse conditions in multi-frame and single-frame evaluations. We achieve improvements of 7.5% and 4.3% in AbsRel and RMSE on average for nuScenes and Robotcar datasets (daytime, nighttime, rain). In zero-shot evaluation of DrivingStereo (rain, fog), our method generalizes better than the previous ones.
EvAnimate: Event-conditioned Image-to-Video Generation for Human Animation
Mar 24, 2025



Conditional human animation transforms a static reference image into a dynamic sequence by applying motion cues such as poses. These motion cues are typically derived from video data but are susceptible to limitations including low temporal resolution, motion blur, overexposure, and inaccuracies under low-light conditions. In contrast, event cameras provide data streams with exceptionally high temporal resolution, a wide dynamic range, and inherent resistance to motion blur and exposure issues. In this work, we propose EvAnimate, a framework that leverages event streams as motion cues to animate static human images. Our approach employs a specialized event representation that transforms asynchronous event streams into 3-channel slices with controllable slicing rates and appropriate slice density, ensuring compatibility with diffusion models. Subsequently, a dual-branch architecture generates high-quality videos by harnessing the inherent motion dynamics of the event streams, thereby enhancing both video quality and temporal consistency. Specialized data augmentation strategies further enhance cross-person generalization. Finally, we establish a new benchmarking, including simulated event data for training and validation, and a real-world event dataset capturing human actions under normal and extreme scenarios. The experiment results demonstrate that EvAnimate achieves high temporal fidelity and robust performance in scenarios where traditional video-derived cues fall short.
A Learnability Analysis on Neuro-Symbolic Learning
Mar 21, 2025This paper analyzes the learnability of neuro-symbolic (NeSy) tasks within hybrid systems. We show that the learnability of NeSy tasks can be characterized by their derived constraint satisfaction problems (DCSPs). Specifically, a task is learnable if the corresponding DCSP has a unique solution; otherwise, it is unlearnable. For learnable tasks, we establish error bounds by exploiting the clustering property of the hypothesis space. Additionally, we analyze the asymptotic error for general NeSy tasks, showing that the expected error scales with the disagreement among solutions. Our results offer a principled approach to determining learnability and provide insights into the design of new algorithms.