 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharTide: Data-Centric Chart-to-Code Generation via Tri-Perspective Tuning and Inquiry-Driven Evolution
Apr 24, 2026Chart-to-code generation demands strict visual precision and syntactic correctness from Vision-Language Models (VLMs). However, existing approaches are fundamentally constrained by data-centric limitations: despite the availability of growing chart-to-code datasets, simply scaling homogeneous chart-code pairs conflates visual perception with program logic, preventing models from fully leveraging the richness of multimodal supervision. We present CharTide, a novel data-centric framework that systematically redesigns both training and alignment data for chart-to-code generation. First, we construct a 2M-sample dataset via a Tri-Perspective Tuning strategy, explicitly decoupling training into visual perception, pure-text code logic, and modality fusion streams, enabling a 7B model to surpass specialized baselines using only supervised data. Second, we reformulate alignment as a data verification problem rather than a heuristic scoring task. To this end, we introduce an Inquiry-Driven RL framework grounded in the principle of information invariance: a downstream model should yield consistent answers to identical visual queries across both original and generated charts. Moving beyond rigid rule matching or VLM scoring, we employ a frozen Inspector to objectively verify generated charts through atomic QA tasks, providing verifiable reward signals based on answer accuracy. Experiments on ChartMimic, Plot2Code, and ChartX show that CharTide-7B/8B significantly outperforms open-source baselines, surpasses GPT-4o, and is competitive with GPT-5.
SEA-Vision: A Multilingual Benchmark for Comprehensive Document and Scene Text Understanding in Southeast Asia
Mar 16, 2026Multilingual document and scene text understanding plays an important role in applications such as search, finance, and public services. However, most existing benchmarks focus on high-resource languages and fail to evaluate models in realistic multilingual environments. In Southeast Asia, the diversity of languages, complex writing systems, and highly varied document types make this challenge even greater. We introduce SEA-Vision, a benchmark that jointly evaluates Document Parsing and Text-Centric Visual Question Answering (TEC-VQA) across 11 Southeast Asian languages. SEA-Vision contains 15,234 document parsing pages from nine representative document types, annotated with hierarchical page-, block-, and line-level labels. It also provides 7,496 TEC-VQA question-answer pairs that probe text recognition, numerical calculation, comparative analysis, logical reasoning, and spatial understanding. To make such multilingual, multi-task annotation feasible, we design a hybrid pipeline for Document Parsing and TEC-VQA. It combines automated filtering and scoring with MLLM-assisted labeling and lightweight native-speaker verification, greatly reducing manual labeling while maintaining high quality. We evaluate several leading multimodal models and observe pronounced performance degradation on low-resource Southeast Asian languages, highlighting substantial remaining gaps in multilingual document and scene text understanding. We believe SEA-Vision will help drive global progress in document and scene text understanding.
CCCaption: Dual-Reward Reinforcement Learning for Complete and Correct Image Captioning
Feb 25, 2026Image captioning remains a fundamental task for vision language understanding, yet ground-truth supervision still relies predominantly on human-annotated references. Because human annotations reflect subjective preferences and expertise, ground-truth captions are often incomplete or even incorrect, which in turn limits caption models. We argue that caption quality should be assessed by two objective aspects: completeness (does the caption cover all salient visual facts?) and correctness (are the descriptions true with respect to the image?). To this end, we introduce CCCaption: a dual-reward reinforcement learning framework with a dedicated fine-tuning corpus that explicitly optimizes these properties to generate \textbf{C}omplete and \textbf{C}orrect \textbf{Captions}. For completeness, we use diverse LVLMs to disentangle the image into a set of visual queries, and reward captions that answer more of these queries, with a dynamic query sampling strategy to improve training efficiency. For correctness, we penalize captions that contain hallucinations by validating the authenticity of sub-caption queries, which are derived from the caption decomposition. Our symmetric dual-reward optimization jointly maximizes completeness and correctness, guiding models toward captions that better satisfy these objective criteria. Extensive experiments across standard captioning benchmarks show consistent improvements, offering a principled path to training caption models beyond human-annotation imitation.
Towards On-Policy SFT: Distribution Discriminant Theory and its Applications in LLM Training
Feb 12, 2026Supervised fine-tuning (SFT) is computationally efficient but often yields inferior generalization compared to reinforcement learning (RL). This gap is primarily driven by RL's use of on-policy data. We propose a framework to bridge this chasm by enabling On-Policy SFT. We first present \textbf{\textit{Distribution Discriminant Theory (DDT)}}, which explains and quantifies the alignment between data and the model-induced distribution. Leveraging DDT, we introduce two complementary techniques: (i) \textbf{\textit{In-Distribution Finetuning (IDFT)}}, a loss-level method to enhance generalization ability of SFT, and (ii) \textbf{\textit{Hinted Decoding}}, a data-level technique that can re-align the training corpus to the model's distribution. Extensive experiments demonstrate that our framework achieves generalization performance on par with prominent offline RL algorithms, including DPO and SimPO, while maintaining the efficiency of an SFT pipeline. The proposed framework thus offers a practical alternative in domains where RL is infeasible. We open-source the code here: https://github.com/zhangmiaosen2000/Towards-On-Policy-SFT
Annotation-Free Curb Detection Leveraging Altitude Difference Image
Sep 30, 2024



Road curbs are considered as one of the crucial and ubiquitous traffic features, which are essential for ensuring the safety of autonomous vehicles. Current methods for detecting curbs primarily rely on camera imagery or LiDAR point clouds. Image-based methods are vulnerable to fluctuations in lighting conditions and exhibit poor robustness, while methods based on point clouds circumvent the issues associated with lighting variations. However, it is the typical case that significant processing delays are encountered due to the voluminous amount of 3D points contained in each frame of the point cloud data. Furthermore, the inherently unstructured characteristics of point clouds poses challenges for integrating the latest deep learning advancements into point cloud data applications. To address these issues, this work proposes an annotation-free curb detection method leveraging Altitude Difference Image (ADI), which effectively mitigates the aforementioned challenges. Given that methods based on deep learning generally demand extensive, manually annotated datasets, which are both expensive and labor-intensive to create, we present an Automatic Curb Annotator (ACA) module. This module utilizes a deterministic curb detection algorithm to automatically generate a vast quantity of training data. Consequently, it facilitates the training of the curb detection model without necessitating any manual annotation of data. Finally, by incorporating a post-processing module, we manage to achieve state-of-the-art results on the KITTI 3D curb dataset with considerably reduced processing delays compared to existing methods, which underscores the effectiveness of our approach in curb detection tasks.
Transformer-empowered Multi-modal Item Embedding for Enhanced Image Search in E-Commerce
Nov 29, 2023



Over the past decade, significant advances have been made in the field of image search for e-commerce applications. Traditional image-to-image retrieval models, which focus solely on image details such as texture, tend to overlook useful semantic information contained within the images. As a result, the retrieved products might possess similar image details, but fail to fulfil the user's search goals. Moreover, the use of image-to-image retrieval models for products containing multiple images results in significant online product feature storage overhead and complex mapping implementations. In this paper, we report the design and deployment of the proposed Multi-modal Item Embedding Model (MIEM) to address these limitations. It is capable of utilizing both textual information and multiple images about a product to construct meaningful product features. By leveraging semantic information from images, MIEM effectively supplements the image search process, improving the overall accuracy of retrieval results. MIEM has become an integral part of the Shopee image search platform. Since its deployment in March 2023, it has achieved a remarkable 9.90% increase in terms of clicks per user and a 4.23% boost in terms of orders per user for the image search feature on the Shopee e-commerce platform.
Hearing Lips: Improving Lip Reading by Distilling Speech Recognizers
Nov 26, 2019

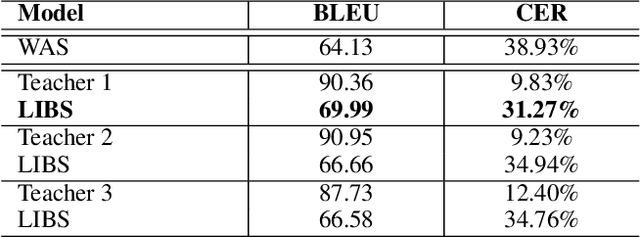

Lip reading has witnessed unparalleled development in recent years thanks to deep learning and the availability of large-scale datasets. Despite the encouraging results achieved, the performance of lip reading, unfortunately, remains inferior to the one of its counterpart speech recognition, due to the ambiguous nature of its actuations that makes it challenging to extract discriminant features from the lip movement videos. In this paper, we propose a new method, termed as Lip by Speech (LIBS), of which the goal is to strengthen lip reading by learning from speech recognizers. The rationale behind our approach is that the features extracted from speech recognizers may provide complementary and discriminant clues, which are formidable to be obtained from the subtle movements of the lips, and consequently facilitate the training of lip readers. This is achieved, specifically, by distilling multi-granularity knowledge from speech recognizers to lip readers. To conduct this cross-modal knowledge distillation, we utilize an efficacious alignment scheme to handle the inconsistent lengths of the audios and videos, as well as an innovative filtering strategy to refine the speech recognizer's prediction. The proposed method achieves the new state-of-the-art performance on the CMLR and LRS2 datasets, outperforming the baseline by a margin of 7.66% and 2.75% in character error rate, respectively.