 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Guided Transformer Tokenizer for Human Motion Generation
Feb 09, 2026In this paper, we focus on motion discrete tokenization, which converts raw motion into compact discrete tokens--a process proven crucial for efficient motion generation. In this paradigm, increasing the number of tokens is a common approach to improving motion reconstruction quality, but more tokens make it more difficult for generative models to learn. To maintain high reconstruction quality while reducing generation complexity, we propose leveraging language to achieve efficient motion tokenization, which we term Language-Guided Tokenization (LG-Tok). LG-Tok aligns natural language with motion at the tokenization stage, yielding compact, high-level semantic representations. This approach not only strengthens both tokenization and detokenization but also simplifies the learning of generative models. Furthermore, existing tokenizers predominantly adopt convolutional architectures, whose local receptive fields struggle to support global language guidance. To this end, we propose a Transformer-based Tokenizer that leverages attention mechanisms to enable effective alignment between language and motion. Additionally, we design a language-drop scheme, in which language conditions are randomly removed during training, enabling the detokenizer to support language-free guidance during generation. On the HumanML3D and Motion-X generation benchmarks, LG-Tok achieves Top-1 scores of 0.542 and 0.582, outperforming state-of-the-art methods (MARDM: 0.500 and 0.528), and with FID scores of 0.057 and 0.088, respectively, versus 0.114 and 0.147. LG-Tok-mini uses only half the tokens while maintaining competitive performance (Top-1: 0.521/0.588, FID: 0.085/0.071), validating the efficiency of our semantic representations.
Human Identification at a Distance: Challenges, Methods and Results on the Competition HID 2025
Feb 07, 2026Human identification at a distance (HID) is challenging because traditional biometric modalities such as face and fingerprints are often difficult to acquire in real-world scenarios. Gait recognition provides a practical alternative, as it can be captured reliably at a distance. To promote progress in gait recognition and provide a fair evaluation platform, the International Competition on Human Identification at a Distance (HID) has been organized annually since 2020. Since 2023, the competition has adopted the challenging SUSTech-Competition dataset, which features substantial variations in clothing, carried objects, and view angles. No dedicated training data are provided, requiring participants to train their models using external datasets. Each year, the competition applies a different random seed to generate distinct evaluation splits, which reduces the risk of overfitting and supports a fair assessment of cross-domain generalization. While HID 2023 and HID 2024 already used this dataset, HID 2025 explicitly examined whether algorithmic advances could surpass the accuracy limits observed previously. Despite the heightened difficulty, participants achieved further improvements, and the best-performing method reached 94.2% accuracy, setting a new benchmark on this dataset. We also analyze key technical trends and outline potential directions for future research in gait recognition.
Superman: Unifying Skeleton and Vision for Human Motion Perception and Generation
Feb 02, 2026Human motion analysis tasks, such as temporal 3D pose estimation, motion prediction, and motion in-betweening, play an essential role in computer vision. However, current paradigms suffer from severe fragmentation. First, the field is split between ``perception'' models that understand motion from video but only output text, and ``generation'' models that cannot perceive from raw visual input. Second, generative MLLMs are often limited to single-frame, static poses using dense, parametric SMPL models, failing to handle temporal motion. Third, existing motion vocabularies are built from skeleton data alone, severing the link to the visual domain. To address these challenges, we introduce Superman, a unified framework that bridges visual perception with temporal, skeleton-based motion generation. Our solution is twofold. First, to overcome the modality disconnect, we propose a Vision-Guided Motion Tokenizer. Leveraging the natural geometric alignment between 3D skeletons and visual data, this module pioneers robust joint learning from both modalities, creating a unified, cross-modal motion vocabulary. Second, grounded in this motion language, a single, unified MLLM architecture is trained to handle all tasks. This module flexibly processes diverse, temporal inputs, unifying 3D skeleton pose estimation from video (perception) with skeleton-based motion prediction and in-betweening (generation). Extensive experiments on standard benchmarks, including Human3.6M, demonstrate that our unified method achieves state-of-the-art or competitive performance across all motion tasks. This showcases a more efficient and scalable path for generative motion analysis using skeletons.
Trustworthy Evaluation of Robotic Manipulation: A New Benchmark and AutoEval Methods
Jan 26, 2026Driven by the rapid evolution of Vision-Action and Vision-Language-Action models, imitation learning has significantly advanced robotic manipulation capabilities. However, evaluation methodologies have lagged behind, hindering the establishment of Trustworthy Evaluation for these behaviors. Current paradigms rely on binary success rates, failing to address the critical dimensions of trust: Source Authenticity (i.e., distinguishing genuine policy behaviors from human teleoperation) and Execution Quality (e.g., smoothness and safety). To bridge these gaps, we propose a solution that combines the Eval-Actions benchmark and the AutoEval architecture. First, we construct the Eval-Actions benchmark to support trustworthiness analysis. Distinct from existing datasets restricted to successful human demonstrations, Eval-Actions integrates VA and VLA policy execution trajectories alongside human teleoperation data, explicitly including failure scenarios. This dataset is structured around three core supervision signals: Expert Grading (EG), Rank-Guided preferences (RG), and Chain-of-Thought (CoT). Building on this, we propose the AutoEval architecture: AutoEval leverages Spatio-Temporal Aggregation for semantic assessment, augmented by an auxiliary Kinematic Calibration Signal to refine motion smoothness; AutoEval Plus (AutoEval-P) incorporates the Group Relative Policy Optimization (GRPO) paradigm to enhance logical reasoning capabilities. Experiments show AutoEval achieves Spearman's Rank Correlation Coefficients (SRCC) of 0.81 and 0.84 under the EG and RG protocols, respectively. Crucially, the framework possesses robust source discrimination capabilities, distinguishing between policy-generated and teleoperated videos with 99.6% accuracy, thereby establishing a rigorous standard for trustworthy robotic evaluation. Our project and code are available at https://term-bench.github.io/.
PoseMoE: Mixture-of-Experts Network for Monocular 3D Human Pose Estimation
Dec 18, 2025The lifting-based methods have dominated monocular 3D human pose estimation by leveraging detected 2D poses as intermediate representations. The 2D component of the final 3D human pose benefits from the detected 2D poses, whereas its depth counterpart must be estimated from scratch. The lifting-based methods encode the detected 2D pose and unknown depth in an entangled feature space, explicitly introducing depth uncertainty to the detected 2D pose, thereby limiting overall estimation accuracy. This work reveals that the depth representation is pivotal for the estimation process. Specifically, when depth is in an initial, completely unknown state, jointly encoding depth features with 2D pose features is detrimental to the estimation process. In contrast, when depth is initially refined to a more dependable state via network-based estimation, encoding it together with 2D pose information is beneficial. To address this limitation, we present a Mixture-of-Experts network for monocular 3D pose estimation named PoseMoE. Our approach introduces: (1) A mixture-of-experts network where specialized expert modules refine the well-detected 2D pose features and learn the depth features. This mixture-of-experts design disentangles the feature encoding process for 2D pose and depth, therefore reducing the explicit influence of uncertain depth features on 2D pose features. (2) A cross-expert knowledge aggregation module is proposed to aggregate cross-expert spatio-temporal contextual information. This step enhances features through bidirectional mapping between 2D pose and depth. Extensive experiments show that our proposed PoseMoE outperforms the conventional lifting-based methods on three widely used datasets: Human3.6M, MPI-INF-3DHP, and 3DPW.
KLO-Net: A Dynamic K-NN Attention U-Net with CSP Encoder for Efficient Prostate Gland Segmentation from MRI
Dec 15, 2025



Real-time deployment of prostate MRI segmentation on clinical workstations is often bottlenecked by computational load and memory footprint. Deep learning-based prostate gland segmentation approaches remain challenging due to anatomical variability. To bridge this efficiency gap while still maintaining reliable segmentation accuracy, we propose KLO-Net, a dynamic K-Nearest Neighbor attention U-Net with Cross Stage Partial, i.e., CSP, encoder for efficient prostate gland segmentation from MRI scan. Unlike the regular K-NN attention mechanism, the proposed dynamic K-NN attention mechanism allows the model to adaptively determine the number of attention connections for each spatial location within a slice. In addition, CSP blocks address the computational load to reduce memory consumption. To evaluate the model's performance, comprehensive experiments and ablation studies are conducted on two public datasets, i.e., PROMISE12 and PROSTATEx, to validate the proposed architecture. The detailed comparative analysis demonstrates the model's advantage in computational efficiency and segmentation quality.
H$_{2}$OT: Hierarchical Hourglass Tokenizer for Efficient Video Pose Transformers
Sep 08, 2025



Transformers have been successfully applied in the field of video-based 3D human pose estimation. However, the high computational costs of these video pose transformers (VPTs) make them impractical on resource-constrained devices. In this paper, we present a hierarchical plug-and-play pruning-and-recovering framework, called Hierarchical Hourglass Tokenizer (H$_{2}$OT), for efficient transformer-based 3D human pose estimation from videos. H$_{2}$OT begins with progressively pruning pose tokens of redundant frames and ends with recovering full-length sequences, resulting in a few pose tokens in the intermediate transformer blocks and thus improving the model efficiency. It works with two key modules, namely, a Token Pruning Module (TPM) and a Token Recovering Module (TRM). TPM dynamically selects a few representative tokens to eliminate the redundancy of video frames, while TRM restores the detailed spatio-temporal information based on the selected tokens, thereby expanding the network output to the original full-length temporal resolution for fast inference. Our method is general-purpose: it can be easily incorporated into common VPT models on both seq2seq and seq2frame pipelines while effectively accommodating different token pruning and recovery strategies. In addition, our H$_{2}$OT reveals that maintaining the full pose sequence is unnecessary, and a few pose tokens of representative frames can achieve both high efficiency and estimation accuracy. Extensive experiments on multiple benchmark datasets demonstrate both the effectiveness and efficiency of the proposed method. Code and models are available at https://github.com/NationalGAILab/HoT.
UST-SSM: Unified Spatio-Temporal State Space Models for Point Cloud Video Modeling
Aug 20, 2025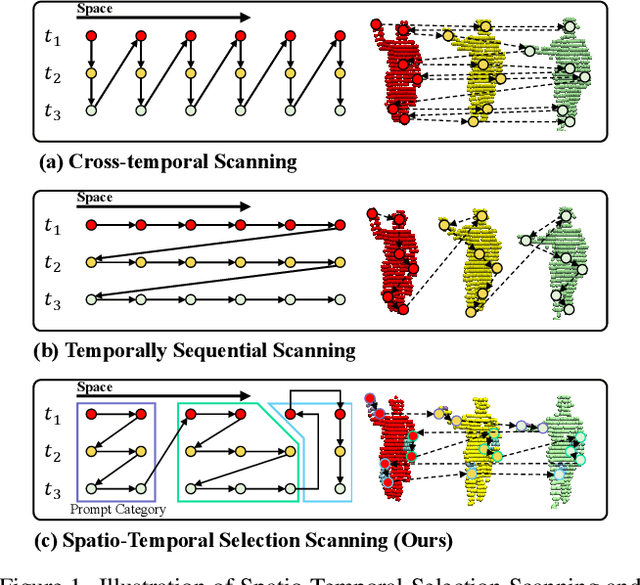
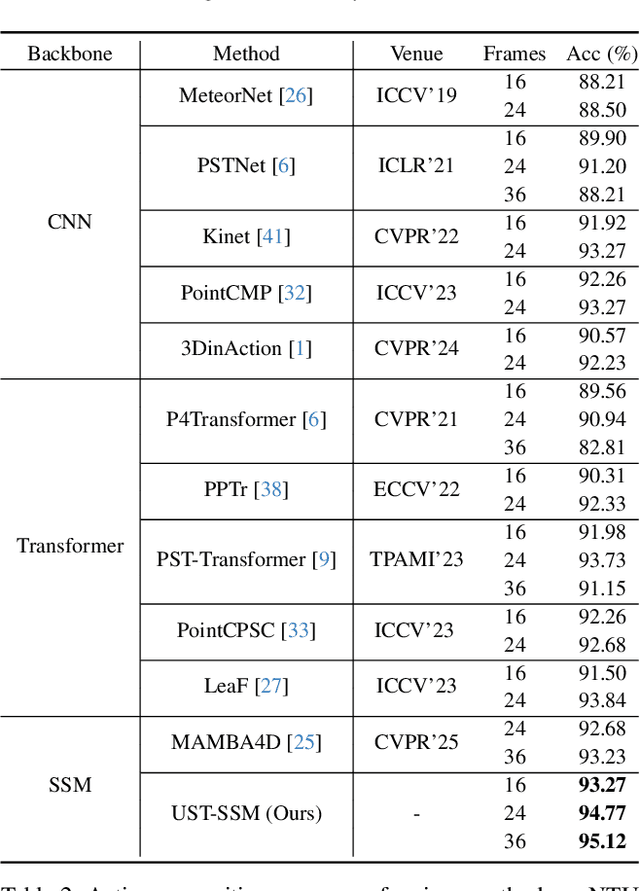
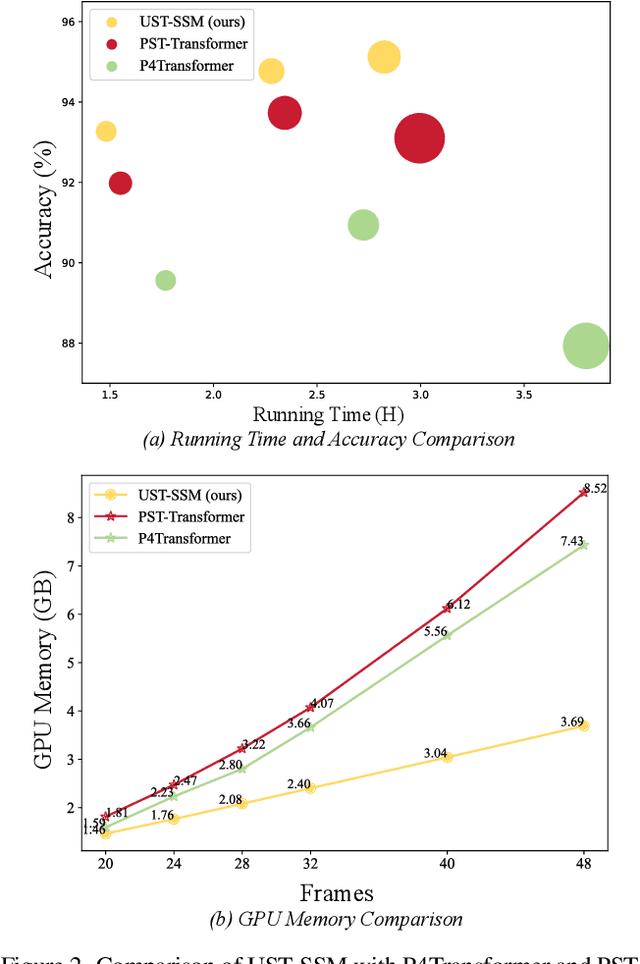
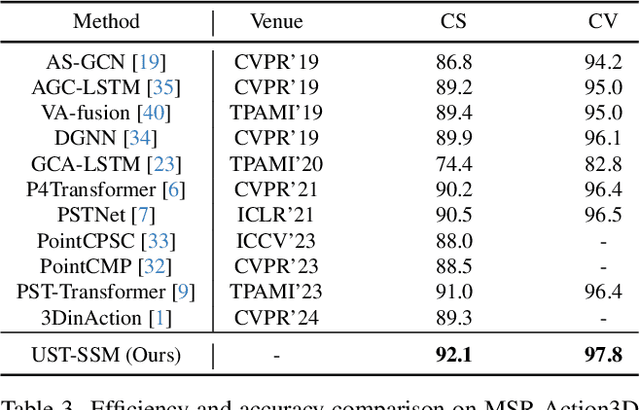
Point cloud videos capture dynamic 3D motion while reducing the effects of lighting and viewpoint variations, making them highly effective for recognizing subtle and continuous human actions. Although Selective State Space Models (SSMs) have shown good performance in sequence modeling with linear complexity, the spatio-temporal disorder of point cloud videos hinders their unidirectional modeling when directly unfolding the point cloud video into a 1D sequence through temporally sequential scanning. To address this challenge, we propose the Unified Spatio-Temporal State Space Model (UST-SSM), which extends the latest advancements in SSMs to point cloud videos. Specifically, we introduce Spatial-Temporal Selection Scanning (STSS), which reorganizes unordered points into semantic-aware sequences through prompt-guided clustering, thereby enabling the effective utilization of points that are spatially and temporally distant yet similar within the sequence. For missing 4D geometric and motion details, Spatio-Temporal Structure Aggregation (STSA) aggregates spatio-temporal features and compensates. To improve temporal interaction within the sampled sequence, Temporal Interaction Sampling (TIS) enhances fine-grained temporal dependencies through non-anchor frame utilization and expanded receptive fields. Experimental results on the MSR-Action3D, NTU RGB+D, and Synthia 4D datasets validate the effectiveness of our method. Our code is available at https://github.com/wangzy01/UST-SSM.
Human-in-Context: Unified Cross-Domain 3D Human Motion Modeling via In-Context Learning
Aug 14, 2025This paper aims to model 3D human motion across domains, where a single model is expected to handle multiple modalities, tasks, and datasets. Existing cross-domain models often rely on domain-specific components and multi-stage training, which limits their practicality and scalability. To overcome these challenges, we propose a new setting to train a unified cross-domain model through a single process, eliminating the need for domain-specific components and multi-stage training. We first introduce Pose-in-Context (PiC), which leverages in-context learning to create a pose-centric cross-domain model. While PiC generalizes across multiple pose-based tasks and datasets, it encounters difficulties with modality diversity, prompting strategy, and contextual dependency handling. We thus propose Human-in-Context (HiC), an extension of PiC that broadens generalization across modalities, tasks, and datasets. HiC combines pose and mesh representations within a unified framework, expands task coverage, and incorporates larger-scale datasets. Additionally, HiC introduces a max-min similarity prompt sampling strategy to enhance generalization across diverse domains and a network architecture with dual-branch context injection for improved handling of contextual dependencies. Extensive experimental results show that HiC performs better than PiC in terms of generalization, data scale, and performance across a wide range of domains. These results demonstrate the potential of HiC for building a unified cross-domain 3D human motion model with improved flexibility and scalability. The source codes and models are available at https://github.com/BradleyWang0416/Human-in-Context.
Masked Clustering Prediction for Unsupervised Point Cloud Pre-training
Aug 12, 2025



Vision transformers (ViTs) have recently been widely applied to 3D point cloud understanding, with masked autoencoding as the predominant pre-training paradigm. However, the challenge of learning dense and informative semantic features from point clouds via standard ViTs remains underexplored. We propose MaskClu, a novel unsupervised pre-training method for ViTs on 3D point clouds that integrates masked point modeling with clustering-based learning. MaskClu is designed to reconstruct both cluster assignments and cluster centers from masked point clouds, thus encouraging the model to capture dense semantic information. Additionally, we introduce a global contrastive learning mechanism that enhances instance-level feature learning by contrasting different masked views of the same point cloud. By jointly optimizing these complementary objectives, i.e., dense semantic reconstruction, and instance-level contrastive learning. MaskClu enables ViTs to learn richer and more semantically meaningful representations from 3D point clouds. We validate the effectiveness of our method via multiple 3D tasks, including part segmentation, semantic segmentation, object detection, and classification, where MaskClu sets new competitive results. The code and models will be released at:https://github.com/Amazingren/maskclu.