 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Evolving Reason-Reflect-Rectify for Reflective Visual Generation
May 19, 2026Text-to-Image (T2I) models and Unified Multimodal Models (UMMs) have achieved remarkable progress in visual generation. However, their reliance on a single-pass generation paradigm limits their ability to handle complex prompts requiring iterative refinement. To enable multi-round Reflective Visual Generation (RVG), we formalize the Reason-Reflect-Rectify (R^3) loop as a core framework and introduce R^3-Bench, a benchmark of over 600 expert-annotated instances that quantifies iterative reasoning and rectification capabilities. Evaluation on R^3-Bench reveals a critical gap: while state-of-the-art models can identify generation errors, they fail to generate actionable rectification instructions. To bridge this gap, we propose R^3-Refiner, a dual-stage framework leveraging Group Relative Policy Optimization (GRPO) and a Hierarchical Reward Mechanism (HRM) to better align rectification with reflective reasoning. Experiments show that R^3-Refiner achieves significant improvements on R^3-Bench (+12.0% in Reflective Verdict Score, +9.0% in Rectification Score), and can be seamlessly integrated with various MLLMs to enhance the generation quality of different T2I models on GenEval++ and T2I-CompBench. Code is available at https://github.com/xiaomoguhz/R3-Bench.
Threshold-Guided Optimization for Visual Generative Models
May 06, 2026Aligning large visual generative models with human feedback is often performed through pairwise preference optimization. While such approaches are conceptually simple, they fundamentally rely on annotated pairs, limiting scalability in settings where feedback is collected as independent scalar ratings. In this work, we revisit the KL-regularized alignment objective and show that the optimal policy implicitly compares each sample's reward to an instance-specific baseline that is generally intractable. We propose a threshold-guided alignment framework that replaces this oracle baseline with a data-driven global threshold estimated from empirical score statistics. This formulation turns alignment into a binary decision task on unpaired data, enabling effective optimization directly from scalar feedback. We also incorporate a confidence weighting term to emphasize samples whose scores deviate strongly from the threshold, improving sample efficiency. Experiments across both diffusion and masked generative paradigms, spanning three test sets and five reward models, show that our method consistently improves preference alignment over previous methods. These results position our threshold-guided framework as a simple yet principled alternative for aligning visual generative models without paired comparisons.
Praxium: Diagnosing Cloud Anomalies with AI-based Telemetry and Dependency Analysis
Mar 25, 2026As the modern microservice architecture for cloud applications grows in popularity, cloud services are becoming increasingly complex and more vulnerable to misconfiguration and software bugs. Traditional approaches rely on expert input to diagnose and fix microservice anomalies, which lacks scalability in the face of the continuous integration and continuous deployment (CI/CD) paradigm. Microservice rollouts, containing new software installations, have complex interactions with the components of an application. Consequently, this added difficulty in attributing anomalous behavior to any specific installation or rollout results in potentially slower resolution times. To address the gaps in current diagnostic methods, this paper introduces Praxium, a framework for anomaly detection and root cause inference. Praxium aids administrators in evaluating target metric performance in the context of dependency installation information provided by a software discovery tool, PraxiPaaS. Praxium continuously monitors telemetry data to identify anomalies, then conducts root cause analysis via causal impact on recent software installations, in order to provide site reliability engineers (SRE) relevant information about an observed anomaly. In this paper, we demonstrate that Praxium is capable of effective anomaly detection and root cause inference, and we provide an analysis on effective anomaly detection hyperparameter tuning as needed in a practical setting. Across 75 total trials using four synthetic anomalies, anomaly detection consistently performs at >0.97 macro-F1. In addition, we show that causal impact analysis reliably infers the correct root cause of anomalies, even as package installations occur at increasingly shorter intervals.
Recover to Predict: Progressive Retrospective Learning for Variable-Length Trajectory Prediction
Mar 11, 2026Trajectory prediction is critical for autonomous driving, enabling safe and efficient planning in dense, dynamic traffic. Most existing methods optimize prediction accuracy under fixed-length observations. However, real-world driving often yields variable-length, incomplete observations, posing a challenge to these methods. A common strategy is to directly map features from incomplete observations to those from complete ones. This one-shot mapping, however, struggles to learn accurate representations for short trajectories due to significant information gaps. To address this issue, we propose a Progressive Retrospective Framework (PRF), which gradually aligns features from incomplete observations with those from complete ones via a cascade of retrospective units. Each unit consists of a Retrospective Distillation Module (RDM) and a Retrospective Prediction Module (RPM), where RDM distills features and RPM recovers previous timesteps using the distilled features. Moreover, we propose a Rolling-Start Training Strategy (RSTS) that enhances data efficiency during PRF training. PRF is plug-and-play with existing methods. Extensive experiments on datasets Argoverse 2 and Argoverse 1 demonstrate the effectiveness of PRF. Code is available at https://github.com/zhouhao94/PRF.
Superman: Unifying Skeleton and Vision for Human Motion Perception and Generation
Feb 02, 2026Human motion analysis tasks, such as temporal 3D pose estimation, motion prediction, and motion in-betweening, play an essential role in computer vision. However, current paradigms suffer from severe fragmentation. First, the field is split between ``perception'' models that understand motion from video but only output text, and ``generation'' models that cannot perceive from raw visual input. Second, generative MLLMs are often limited to single-frame, static poses using dense, parametric SMPL models, failing to handle temporal motion. Third, existing motion vocabularies are built from skeleton data alone, severing the link to the visual domain. To address these challenges, we introduce Superman, a unified framework that bridges visual perception with temporal, skeleton-based motion generation. Our solution is twofold. First, to overcome the modality disconnect, we propose a Vision-Guided Motion Tokenizer. Leveraging the natural geometric alignment between 3D skeletons and visual data, this module pioneers robust joint learning from both modalities, creating a unified, cross-modal motion vocabulary. Second, grounded in this motion language, a single, unified MLLM architecture is trained to handle all tasks. This module flexibly processes diverse, temporal inputs, unifying 3D skeleton pose estimation from video (perception) with skeleton-based motion prediction and in-betweening (generation). Extensive experiments on standard benchmarks, including Human3.6M, demonstrate that our unified method achieves state-of-the-art or competitive performance across all motion tasks. This showcases a more efficient and scalable path for generative motion analysis using skeletons.
UM-Text: A Unified Multimodal Model for Image Understanding
Jan 13, 2026With the rapid advancement of image generation, visual text editing using natural language instructions has received increasing attention. The main challenge of this task is to fully understand the instruction and reference image, and thus generate visual text that is style-consistent with the image. Previous methods often involve complex steps of specifying the text content and attributes, such as font size, color, and layout, without considering the stylistic consistency with the reference image. To address this, we propose UM-Text, a unified multimodal model for context understanding and visual text editing by natural language instructions. Specifically, we introduce a Visual Language Model (VLM) to process the instruction and reference image, so that the text content and layout can be elaborately designed according to the context information. To generate an accurate and harmonious visual text image, we further propose the UM-Encoder to combine the embeddings of various condition information, where the combination is automatically configured by VLM according to the input instruction. During training, we propose a regional consistency loss to offer more effective supervision for glyph generation on both latent and RGB space, and design a tailored three-stage training strategy to further enhance model performance. In addition, we contribute the UM-DATA-200K, a large-scale visual text image dataset on diverse scenes for model training. Extensive qualitative and quantitative results on multiple public benchmarks demonstrate that our method achieves state-of-the-art performance.
RePainter: Empowering E-commerce Object Removal via Spatial-matting Reinforcement Learning
Oct 09, 2025In web data, product images are central to boosting user engagement and advertising efficacy on e-commerce platforms, yet the intrusive elements such as watermarks and promotional text remain major obstacles to delivering clear and appealing product visuals. Although diffusion-based inpainting methods have advanced, they still face challenges in commercial settings due to unreliable object removal and limited domain-specific adaptation. To tackle these challenges, we propose Repainter, a reinforcement learning framework that integrates spatial-matting trajectory refinement with Group Relative Policy Optimization (GRPO). Our approach modulates attention mechanisms to emphasize background context, generating higher-reward samples and reducing unwanted object insertion. We also introduce a composite reward mechanism that balances global, local, and semantic constraints, effectively reducing visual artifacts and reward hacking. Additionally, we contribute EcomPaint-100K, a high-quality, large-scale e-commerce inpainting dataset, and a standardized benchmark EcomPaint-Bench for fair evaluation. Extensive experiments demonstrate that Repainter significantly outperforms state-of-the-art methods, especially in challenging scenes with intricate compositions. We will release our code and weights upon acceptance.
IntelliLung: Advancing Safe Mechanical Ventilation using Offline RL with Hybrid Actions and Clinically Aligned Rewards
Jun 17, 2025Invasive mechanical ventilation (MV) is a life-sustaining therapy for critically ill patients in the intensive care unit (ICU). However, optimizing its settings remains a complex and error-prone process due to patient-specific variability. While Offline Reinforcement Learning (RL) shows promise for MV control, current stateof-the-art (SOTA) methods struggle with the hybrid (continuous and discrete) nature of MV actions. Discretizing the action space limits available actions due to exponential growth in combinations and introduces distribution shifts that can compromise safety. In this paper, we propose optimizations that build upon prior work in action space reduction to address the challenges of discrete action spaces. We also adapt SOTA offline RL algorithms (IQL and EDAC) to operate directly on hybrid action spaces, thereby avoiding the pitfalls of discretization. Additionally, we introduce a clinically grounded reward function based on ventilator-free days and physiological targets, which provides a more meaningful optimization objective compared to traditional sparse mortality-based rewards. Our findings demonstrate that AI-assisted MV optimization may enhance patient safety and enable individualized lung support, representing a significant advancement toward intelligent, data-driven critical care solutions.
HiFiTTS-2: A Large-Scale High Bandwidth Speech Dataset
Jun 04, 2025This paper introduces HiFiTTS-2, a large-scale speech dataset designed for high-bandwidth speech synthesis. The dataset is derived from LibriVox audiobooks, and contains approximately 36.7k hours of English speech for 22.05 kHz training, and 31.7k hours for 44.1 kHz training. We present our data processing pipeline, including bandwidth estimation, segmentation, text preprocessing, and multi-speaker detection. The dataset is accompanied by detailed utterance and audiobook metadata generated by our pipeline, enabling researchers to apply data quality filters to adapt the dataset to various use cases. Experimental results demonstrate that our data pipeline and resulting dataset can facilitate the training of high-quality, zero-shot text-to-speech (TTS) models at high bandwidths.
Efficient and Direct Duplex Modeling for Speech-to-Speech Language Model
May 21, 2025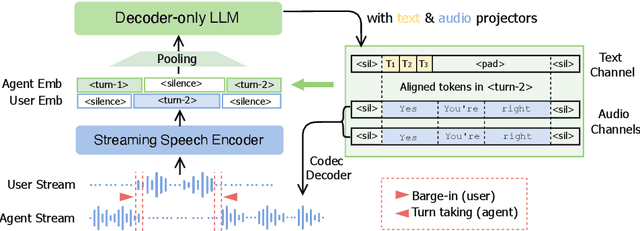
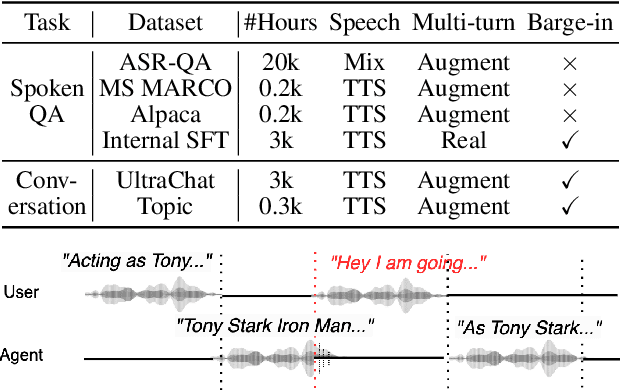
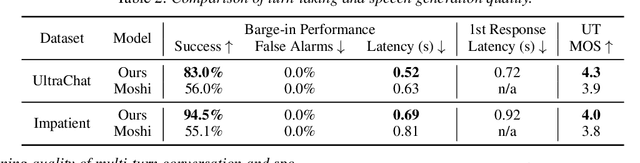
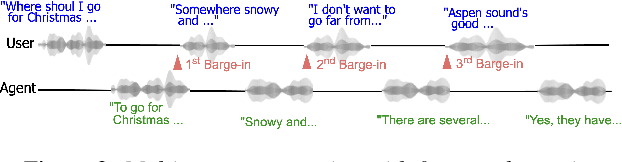
Spoken dialogue is an intuitive form of human-computer interaction, yet current speech language models often remain constrained to turn-based exchanges, lacking real-time adaptability such as user barge-in. We propose a novel duplex speech to speech (S2S) architecture featuring continuous user inputs and codec agent outputs with channel fusion that directly models simultaneous user and agent streams. Using a pretrained streaming encoder for user input enables the first duplex S2S model without requiring speech pretrain. Separate architectures for agent and user modeling facilitate codec fine-tuning for better agent voices and halve the bitrate (0.6 kbps) compared to previous works. Experimental results show that the proposed model outperforms previous duplex models in reasoning, turn-taking, and barge-in abilities. The model requires significantly less speech data, as speech pretrain is skipped, which markedly simplifies the process of building a duplex S2S model from any LLMs. Finally, it is the first openly available duplex S2S model with training and inference code to foster reproducibility.