 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeng Wang
Hybrid Multimodal Feature Extraction, Mining and Fusion for Sentiment Analysis
Aug 05, 2022
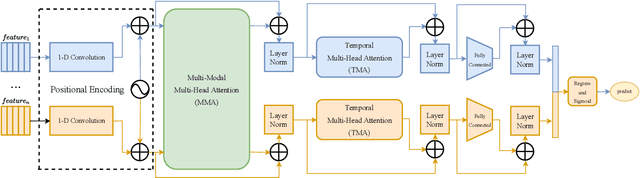
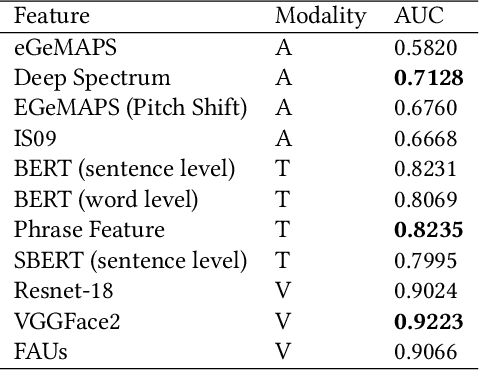
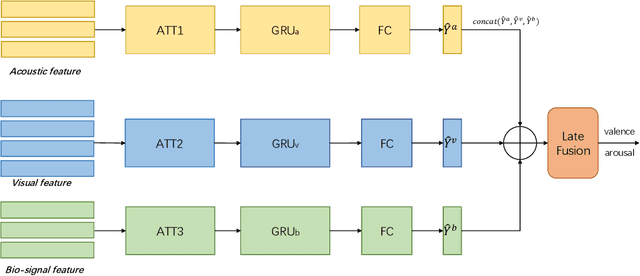
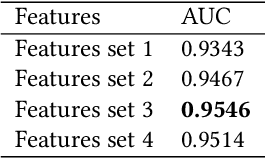
In this paper, we present our solutions for the Multimodal Sentiment Analysis Challenge (MuSe) 2022, which includes MuSe-Humor, MuSe-Reaction and MuSe-Stress Sub-challenges. The MuSe 2022 focuses on humor detection, emotional reactions and multimodal emotional stress utilising different modalities and data sets. In our work, different kinds of multimodal features are extracted, including acoustic, visual, text and biological features. These features are fused by TEMMA and GRU with self-attention mechanism frameworks. In this paper, 1) several new audio features, facial expression features and paragraph-level text embeddings are extracted for accuracy improvement. 2) we substantially improve the accuracy and reliability for multimodal sentiment prediction by mining and blending the multimodal features. 3) effective data augmentation strategies are applied in model training to alleviate the problem of sample imbalance and prevent the model form learning biased subject characters. For the MuSe-Humor sub-challenge, our model obtains the AUC score of 0.8932. For the MuSe-Reaction sub-challenge, the Pearson's Correlations Coefficient of our approach on the test set is 0.3879, which outperforms all other participants. For the MuSe-Stress sub-challenge, our approach outperforms the baseline in both arousal and valence on the test dataset, reaching a final combined result of 0.5151.
Downwash-aware Control Allocation for Over-actuated UAV Platforms
Jul 20, 2022



Tracking position and orientation independently affords more agile maneuver for over-actuated multirotor Unmanned Aerial Vehicles (UAVs) while introducing undesired downwash effects; downwash flows generated by thrust generators may counteract others due to close proximity, which significantly threatens the stability of the platform. The complexity of modeling aerodynamic airflow challenges control algorithms from properly compensating for such a side effect. Leveraging the input redundancies in over-actuated UAVs, we tackle this issue with a novel control allocation framework that considers downwash effects and explores the entire allocation space for an optimal solution. This optimal solution avoids downwash effects while providing high thrust efficiency within the hardware constraints. To the best of our knowledge, ours is the first formal derivation to investigate the downwash effects on over-actuated UAVs. We verify our framework on different hardware configurations in both simulation and experiment.
A Semantic-aware Attention and Visual Shielding Network for Cloth-changing Person Re-identification
Jul 18, 2022

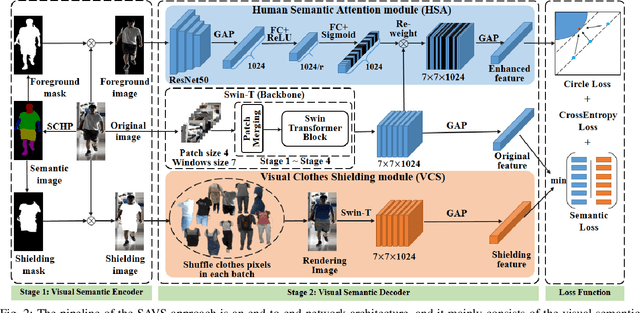

Cloth-changing person reidentification (ReID) is a newly emerging research topic that aims to retrieve pedestrians whose clothes are changed. Since the human appearance with different clothes exhibits large variations, it is very difficult for existing approaches to extract discriminative and robust feature representations. Current works mainly focus on body shape or contour sketches, but the human semantic information and the potential consistency of pedestrian features before and after changing clothes are not fully explored or are ignored. To solve these issues, in this work, a novel semantic-aware attention and visual shielding network for cloth-changing person ReID (abbreviated as SAVS) is proposed where the key idea is to shield clues related to the appearance of clothes and only focus on visual semantic information that is not sensitive to view/posture changes. Specifically, a visual semantic encoder is first employed to locate the human body and clothing regions based on human semantic segmentation information. Then, a human semantic attention module (HSA) is proposed to highlight the human semantic information and reweight the visual feature map. In addition, a visual clothes shielding module (VCS) is also designed to extract a more robust feature representation for the cloth-changing task by covering the clothing regions and focusing the model on the visual semantic information unrelated to the clothes. Most importantly, these two modules are jointly explored in an end-to-end unified framework. Extensive experiments demonstrate that the proposed method can significantly outperform state-of-the-art methods, and more robust features can be extracted for cloth-changing persons. Compared with FSAM (published in CVPR 2021), this method can achieve improvements of 32.7% (16.5%) and 14.9% (-) on the LTCC and PRCC datasets in terms of mAP (rank-1), respectively.
Audio-Visual Segmentation
Jul 11, 2022

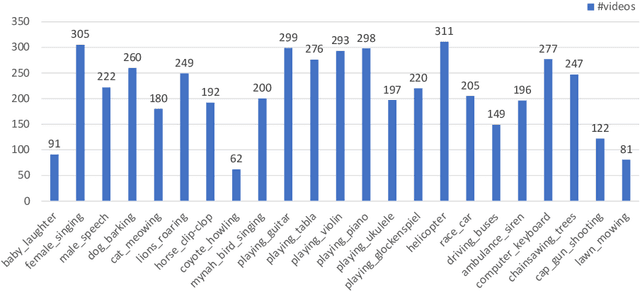
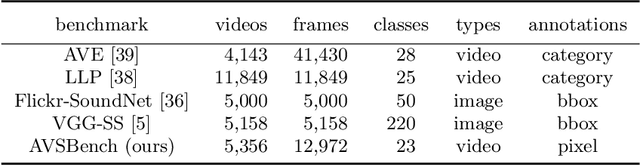
We propose to explore a new problem called audio-visual segmentation (AVS), in which the goal is to output a pixel-level map of the object(s) that produce sound at the time of the image frame. To facilitate this research, we construct the first audio-visual segmentation benchmark (AVSBench), providing pixel-wise annotations for the sounding objects in audible videos. Two settings are studied with this benchmark: 1) semi-supervised audio-visual segmentation with a single sound source and 2) fully-supervised audio-visual segmentation with multiple sound sources. To deal with the AVS problem, we propose a novel method that uses a temporal pixel-wise audio-visual interaction module to inject audio semantics as guidance for the visual segmentation process. We also design a regularization loss to encourage the audio-visual mapping during training. Quantitative and qualitative experiments on the AVSBench compare our approach to several existing methods from related tasks, demonstrating that the proposed method is promising for building a bridge between the audio and pixel-wise visual semantics. Code is available at https://github.com/OpenNLPLab/AVSBench.
Learning and generalization of one-hidden-layer neural networks, going beyond standard Gaussian data
Jul 07, 2022
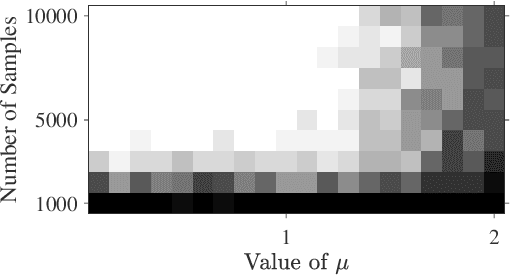
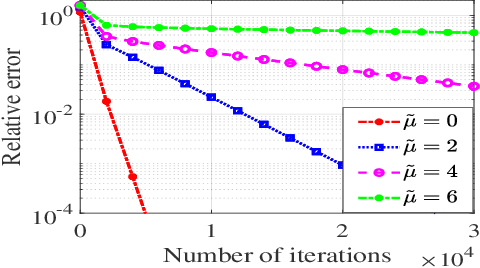
This paper analyzes the convergence and generalization of training a one-hidden-layer neural network when the input features follow the Gaussian mixture model consisting of a finite number of Gaussian distributions. Assuming the labels are generated from a teacher model with an unknown ground truth weight, the learning problem is to estimate the underlying teacher model by minimizing a non-convex risk function over a student neural network. With a finite number of training samples, referred to the sample complexity, the iterations are proved to converge linearly to a critical point with guaranteed generalization error. In addition, for the first time, this paper characterizes the impact of the input distributions on the sample complexity and the learning rate.
Generalization Guarantee of Training Graph Convolutional Networks with Graph Topology Sampling
Jul 07, 2022
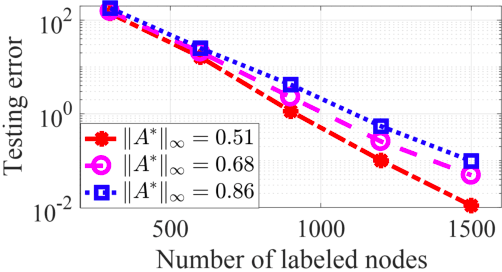
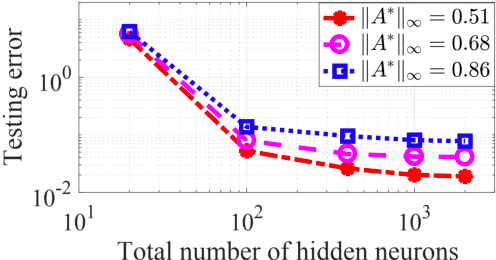

Graph convolutional networks (GCNs) have recently achieved great empirical success in learning graph-structured data. To address its scalability issue due to the recursive embedding of neighboring features, graph topology sampling has been proposed to reduce the memory and computational cost of training GCNs, and it has achieved comparable test performance to those without topology sampling in many empirical studies. To the best of our knowledge, this paper provides the first theoretical justification of graph topology sampling in training (up to) three-layer GCNs for semi-supervised node classification. We formally characterize some sufficient conditions on graph topology sampling such that GCN training leads to a diminishing generalization error. Moreover, our method tackles the nonconvex interaction of weights across layers, which is under-explored in the existing theoretical analyses of GCNs. This paper characterizes the impact of graph structures and topology sampling on the generalization performance and sample complexity explicitly, and the theoretical findings are also justified through numerical experiments.
Recent Results of Energy Disaggregation with Behind-the-Meter Solar Generation
Jul 07, 2022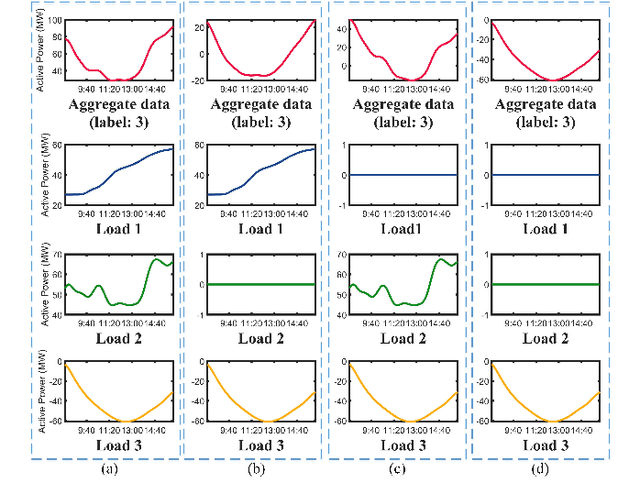
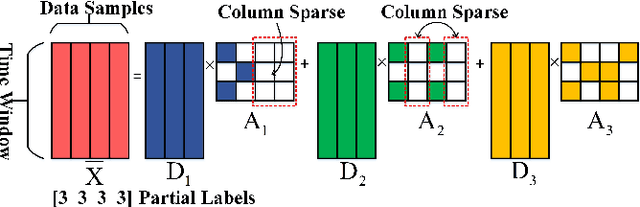
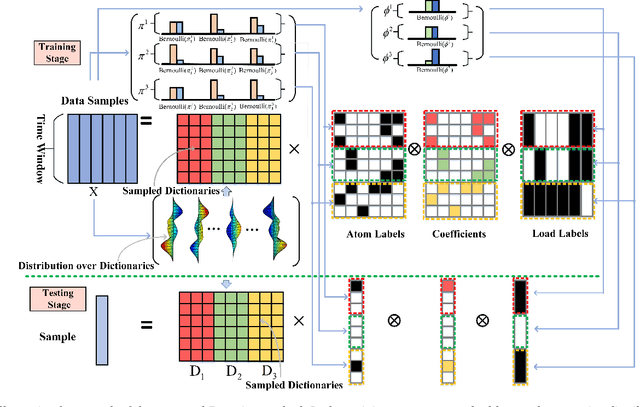
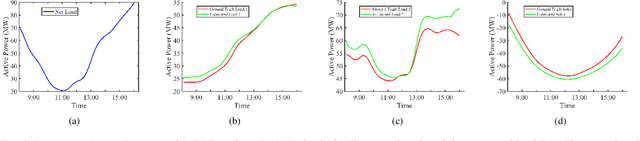
The rapid deployment of renewable generations such as photovoltaic (PV) generations brings great challenges to the resiliency of existing power systems. Because PV generations are volatile and typically invisible to the power system operator, estimating the generation and characterizing the uncertainty are in urgent need for operators to make insightful decisions. This paper summarizes our recent results on energy disaggregation at the substation level with Behind-the-Meter solar generation. We formulate the so-called ``partial label'' problem for energy disaggregation at substations, where the aggregate measurements contain the total consumption of multiple loads, and the existence of some loads is unknown. We develop two model-free disaggregation approaches based on deterministic dictionary learning and Bayesian dictionary learning, respectively. Unlike conventional methods which require fully annotated training data of individual loads, our approaches can extract load patterns given partially labeled aggregate data. Therefore, our partial label formulation is more applicable in the real world. Compared with deterministic dictionary learning, the Bayesian dictionary learning-based approach provides the uncertainty measure for the disaggregation results, at the cost of increased computational complexity. All the methods are validated by numerical experiments.
Solutions for Fine-grained and Long-tailed Snake Species Recognition in SnakeCLEF 2022
Jul 04, 2022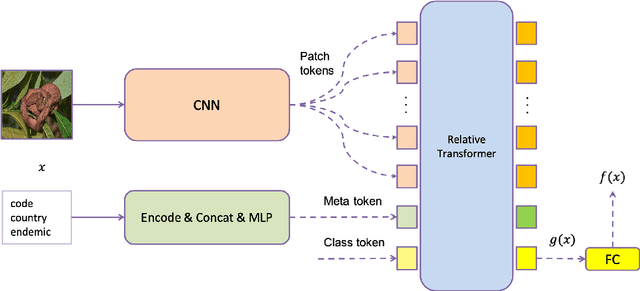
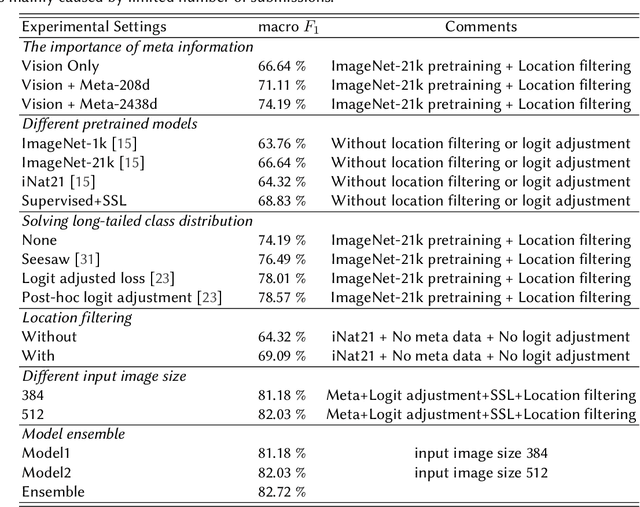

Automatic snake species recognition is important because it has vast potential to help lower deaths and disabilities caused by snakebites. We introduce our solution in SnakeCLEF 2022 for fine-grained snake species recognition on a heavy long-tailed class distribution. First, a network architecture is designed to extract and fuse features from multiple modalities, i.e. photograph from visual modality and geographic locality information from language modality. Then, logit adjustment based methods are studied to relieve the impact caused by the severe class imbalance. Next, a combination of supervised and self-supervised learning method is proposed to make full use of the dataset, including both labeled training data and unlabeled testing data. Finally, post processing strategies, such as multi-scale and multi-crop test-time-augmentation, location filtering and model ensemble, are employed for better performance. With an ensemble of several different models, a private score 82.65%, ranking the 3rd, is achieved on the final leaderboard.
TBraTS: Trusted Brain Tumor Segmentation
Jun 30, 2022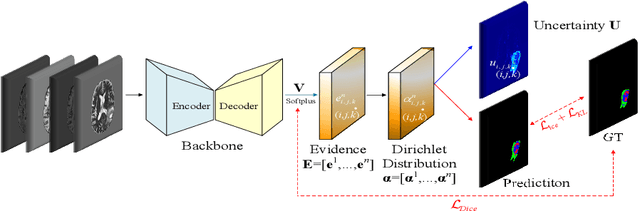

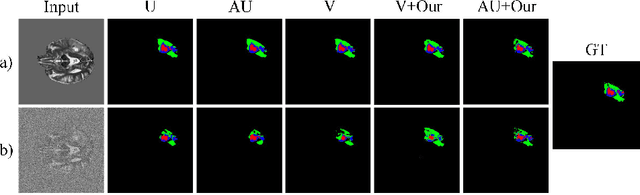
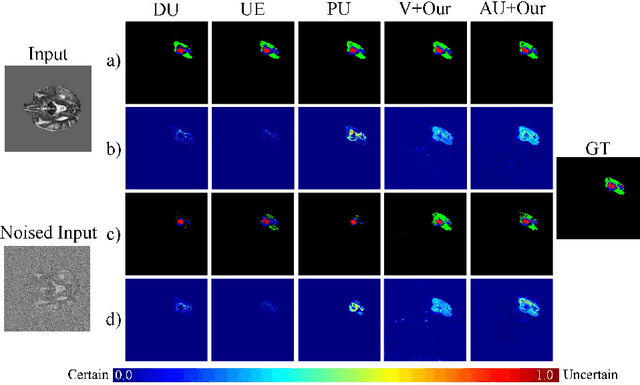
Despite recent improvements in the accuracy of brain tumor segmentation, the results still exhibit low levels of confidence and robustness. Uncertainty estimation is one effective way to change this situation, as it provides a measure of confidence in the segmentation results. In this paper, we propose a trusted brain tumor segmentation network which can generate robust segmentation results and reliable uncertainty estimations without excessive computational burden and modification of the backbone network. In our method, uncertainty is modeled explicitly using subjective logic theory, which treats the predictions of backbone neural network as subjective opinions by parameterizing the class probabilities of the segmentation as a Dirichlet distribution. Meanwhile, the trusted segmentation framework learns the function that gathers reliable evidence from the feature leading to the final segmentation results. Overall, our unified trusted segmentation framework endows the model with reliability and robustness to out-of-distribution samples. To evaluate the effectiveness of our model in robustness and reliability, qualitative and quantitative experiments are conducted on the BraTS 2019 dataset.
KTN: Knowledge Transfer Network for Learning Multi-person 2D-3D Correspondences
Jun 21, 2022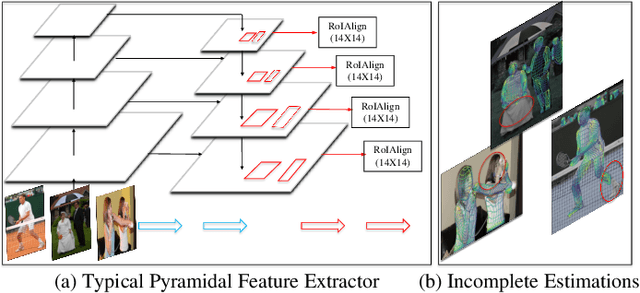
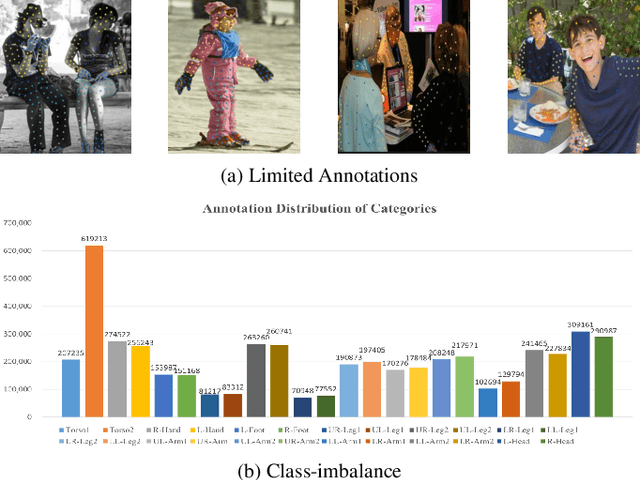
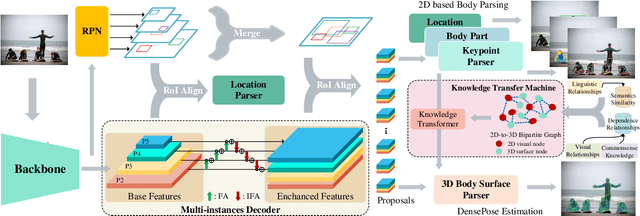
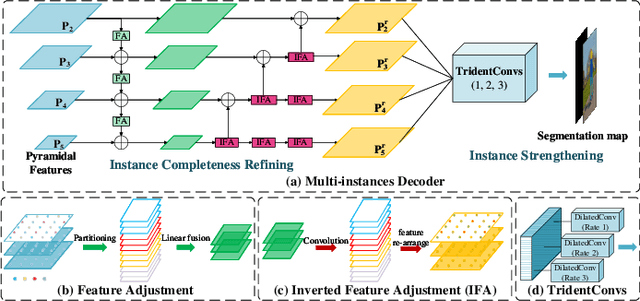
Human densepose estimation, aiming at establishing dense correspondences between 2D pixels of human body and 3D human body template, is a key technique in enabling machines to have an understanding of people in images. It still poses several challenges due to practical scenarios where real-world scenes are complex and only partial annotations are available, leading to incompelete or false estimations. In this work, we present a novel framework to detect the densepose of multiple people in an image. The proposed method, which we refer to Knowledge Transfer Network (KTN), tackles two main problems: 1) how to refine image representation for alleviating incomplete estimations, and 2) how to reduce false estimation caused by the low-quality training labels (i.e., limited annotations and class-imbalance labels). Unlike existing works directly propagating the pyramidal features of regions for densepose estimation, the KTN uses a refinement of pyramidal representation, where it simultaneously maintains feature resolution and suppresses background pixels, and this strategy results in a substantial increase in accuracy. Moreover, the KTN enhances the ability of 3D based body parsing with external knowledges, where it casts 2D based body parsers trained from sufficient annotations as a 3D based body parser through a structural body knowledge graph. In this way, it significantly reduces the adverse effects caused by the low-quality annotations. The effectiveness of KTN is demonstrated by its superior performance to the state-of-the-art methods on DensePose-COCO dataset. Extensive ablation studies and experimental results on representative tasks (e.g., human body segmentation, human part segmentation and keypoints detection) and two popular densepose estimation pipelines (i.e., RCNN and fully-convolutional frameworks), further indicate the generalizability of the proposed method.