 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizable and Robust Text-to-SQL Parsing
Oct 23, 2022



Text-to-SQL parsing tackles the problem of mapping natural language questions to executable SQL queries. In practice, text-to-SQL parsers often encounter various challenging scenarios, requiring them to be generalizable and robust. While most existing work addresses a particular generalization or robustness challenge, we aim to study it in a more comprehensive manner. In specific, we believe that text-to-SQL parsers should be (1) generalizable at three levels of generalization, namely i.i.d., zero-shot, and compositional, and (2) robust against input perturbations. To enhance these capabilities of the parser, we propose a novel TKK framework consisting of Task decomposition, Knowledge acquisition, and Knowledge composition to learn text-to-SQL parsing in stages. By dividing the learning process into multiple stages, our framework improves the parser's ability to acquire general SQL knowledge instead of capturing spurious patterns, making it more generalizable and robust. Experimental results under various generalization and robustness settings show that our framework is effective in all scenarios and achieves state-of-the-art performance on the Spider, SParC, and CoSQL datasets. Code can be found at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/tkk.
SPACE-3: Unified Dialog Model Pre-training for Task-Oriented Dialog Understanding and Generation
Sep 14, 2022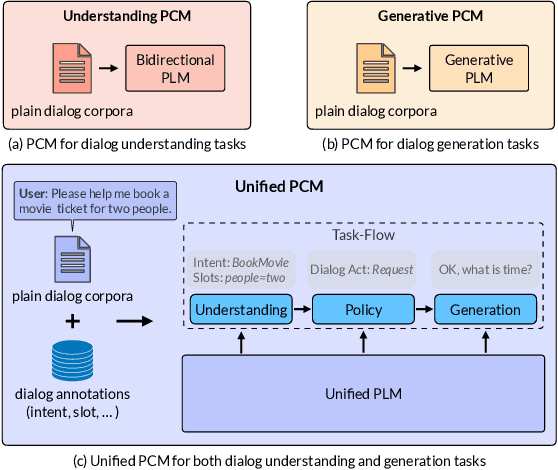
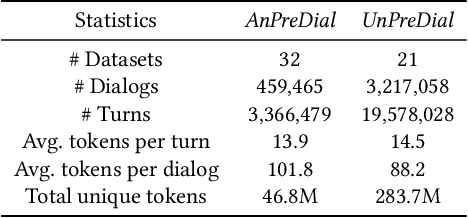

Recently, pre-training methods have shown remarkable success in task-oriented dialog (TOD) systems. However, most existing pre-trained models for TOD focus on either dialog understanding or dialog generation, but not both. In this paper, we propose SPACE-3, a novel unified semi-supervised pre-trained conversation model learning from large-scale dialog corpora with limited annotations, which can be effectively fine-tuned on a wide range of downstream dialog tasks. Specifically, SPACE-3 consists of four successive components in a single transformer to maintain a task-flow in TOD systems: (i) a dialog encoding module to encode dialog history, (ii) a dialog understanding module to extract semantic vectors from either user queries or system responses, (iii) a dialog policy module to generate a policy vector that contains high-level semantics of the response, and (iv) a dialog generation module to produce appropriate responses. We design a dedicated pre-training objective for each component. Concretely, we pre-train the dialog encoding module with span mask language modeling to learn contextualized dialog information. To capture the structured dialog semantics, we pre-train the dialog understanding module via a novel tree-induced semi-supervised contrastive learning objective with the help of extra dialog annotations. In addition, we pre-train the dialog policy module by minimizing the L2 distance between its output policy vector and the semantic vector of the response for policy optimization. Finally, the dialog generation model is pre-trained by language modeling. Results show that SPACE-3 achieves state-of-the-art performance on eight downstream dialog benchmarks, including intent prediction, dialog state tracking, and end-to-end dialog modeling. We also show that SPACE-3 has a stronger few-shot ability than existing models under the low-resource setting.
SPACE-2: Tree-Structured Semi-Supervised Contrastive Pre-training for Task-Oriented Dialog Understanding
Sep 14, 2022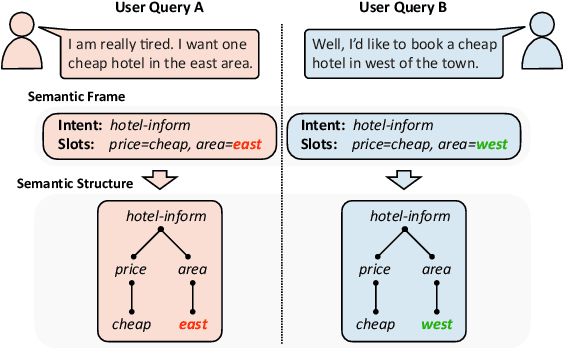
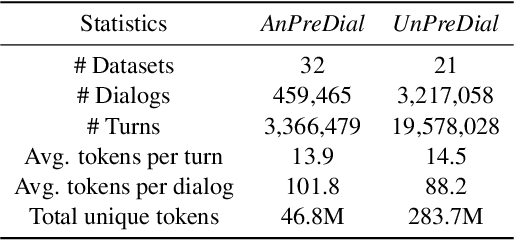
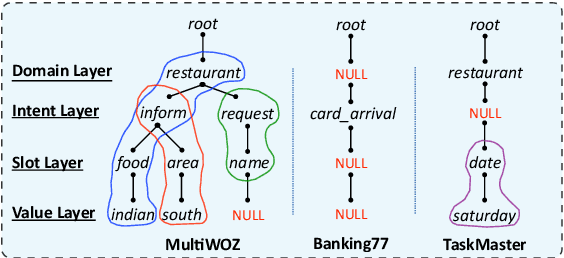
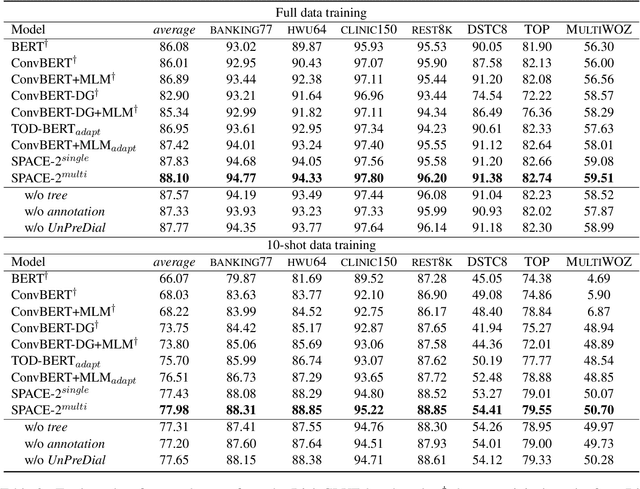
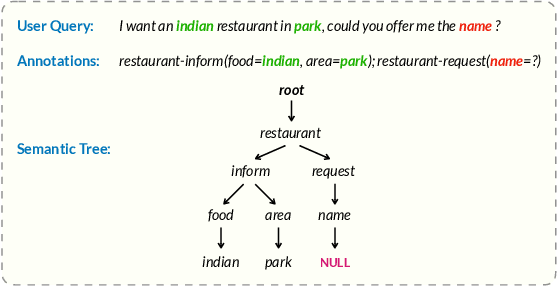
Pre-training methods with contrastive learning objectives have shown remarkable success in dialog understanding tasks. However, current contrastive learning solely considers the self-augmented dialog samples as positive samples and treats all other dialog samples as negative ones, which enforces dissimilar representations even for dialogs that are semantically related. In this paper, we propose SPACE-2, a tree-structured pre-trained conversation model, which learns dialog representations from limited labeled dialogs and large-scale unlabeled dialog corpora via semi-supervised contrastive pre-training. Concretely, we first define a general semantic tree structure (STS) to unify the inconsistent annotation schema across different dialog datasets, so that the rich structural information stored in all labeled data can be exploited. Then we propose a novel multi-view score function to increase the relevance of all possible dialogs that share similar STSs and only push away other completely different dialogs during supervised contrastive pre-training. To fully exploit unlabeled dialogs, a basic self-supervised contrastive loss is also added to refine the learned representations. Experiments show that our method can achieve new state-of-the-art results on the DialoGLUE benchmark consisting of seven datasets and four popular dialog understanding tasks. For reproducibility, we release the code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/space-2.
SUN: Exploring Intrinsic Uncertainties in Text-to-SQL Parsers
Sep 14, 2022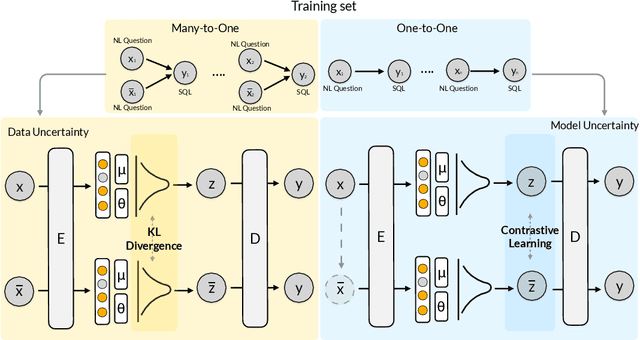
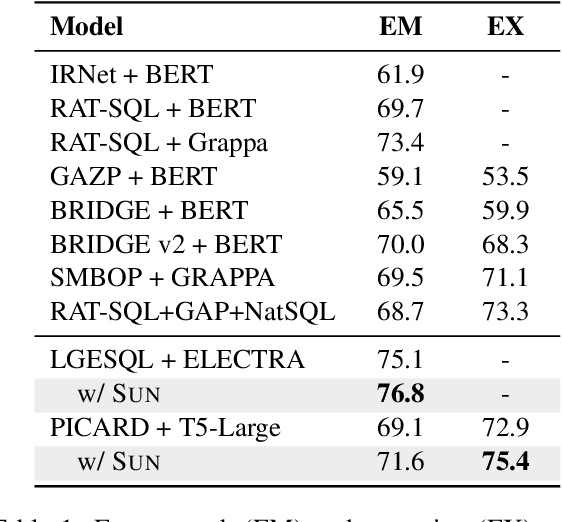
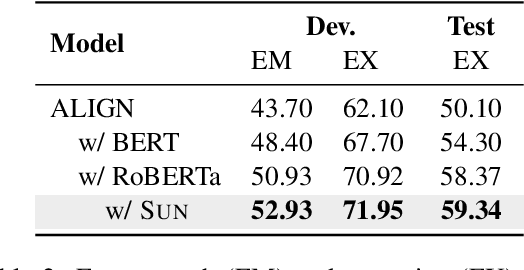
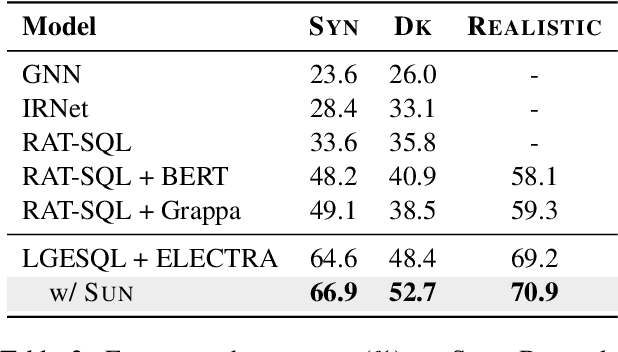
This paper aims to improve the performance of text-to-SQL parsing by exploring the intrinsic uncertainties in the neural network based approaches (called SUN). From the data uncertainty perspective, it is indisputable that a single SQL can be learned from multiple semantically-equivalent questions.Different from previous methods that are limited to one-to-one mapping, we propose a data uncertainty constraint to explore the underlying complementary semantic information among multiple semantically-equivalent questions (many-to-one) and learn the robust feature representations with reduced spurious associations. In this way, we can reduce the sensitivity of the learned representations and improve the robustness of the parser. From the model uncertainty perspective, there is often structural information (dependence) among the weights of neural networks. To improve the generalizability and stability of neural text-to-SQL parsers, we propose a model uncertainty constraint to refine the query representations by enforcing the output representations of different perturbed encoding networks to be consistent with each other. Extensive experiments on five benchmark datasets demonstrate that our method significantly outperforms strong competitors and achieves new state-of-the-art results. For reproducibility, we release our code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/sunsql.
Lifelong Learning for Question Answering with Hierarchical Prompts
Aug 31, 2022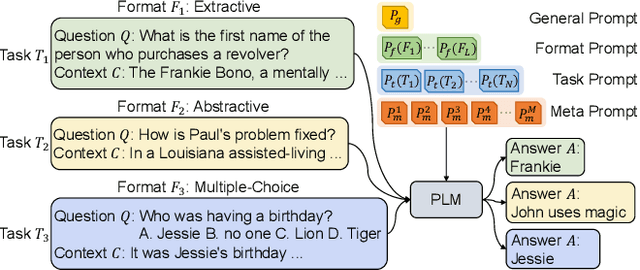
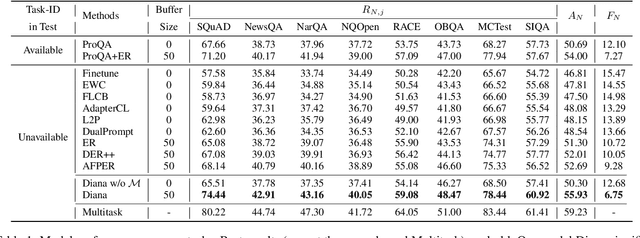
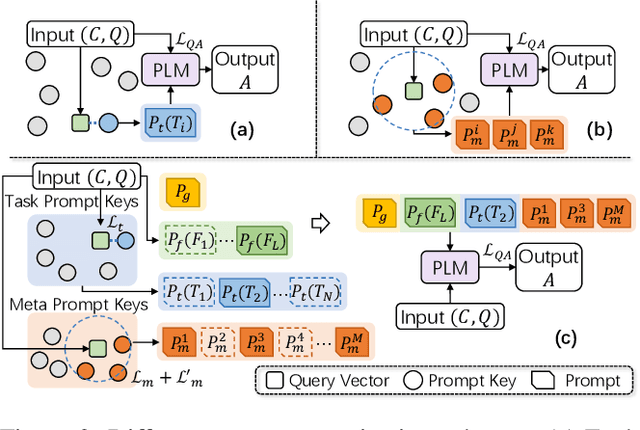
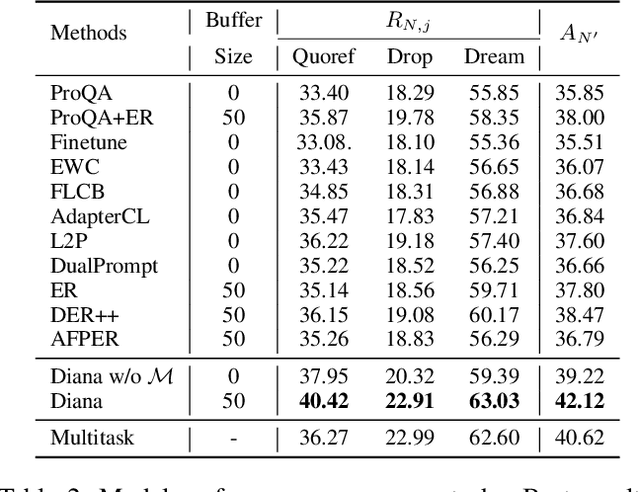
QA models with lifelong learning (LL) abilities are important for practical QA applications, and architecture-based LL methods are reported to be an effective implementation for these models. However, it is non-trivial to extend previous approaches to QA tasks since they either require access to task identities in the testing phase or do not explicitly model samples from unseen tasks. In this paper, we propose Diana: a dynamic architecture-based lifelong QA model that tries to learn a sequence of QA tasks with a prompt enhanced language model. Four types of hierarchically organized prompts are used in Diana to capture QA knowledge from different granularities. Specifically, we dedicate task-level prompts to capture task-specific knowledge to retain high LL performances and maintain instance-level prompts to learn knowledge shared across different input samples to improve the model's generalization performance. Moreover, we dedicate separate prompts to explicitly model unseen tasks and introduce a set of prompt key vectors to facilitate knowledge sharing between tasks. Extensive experiments demonstrate that Diana outperforms state-of-the-art lifelong QA models, especially in handling unseen tasks.
A Survey on Text-to-SQL Parsing: Concepts, Methods, and Future Directions
Aug 29, 2022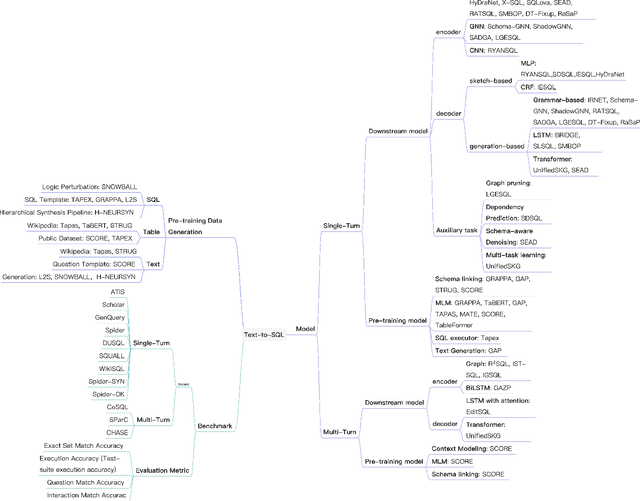


Text-to-SQL parsing is an essential and challenging task. The goal of text-to-SQL parsing is to convert a natural language (NL) question to its corresponding structured query language (SQL) based on the evidences provided by relational databases. Early text-to-SQL parsing systems from the database community achieved a noticeable progress with the cost of heavy human engineering and user interactions with the systems. In recent years, deep neural networks have significantly advanced this task by neural generation models, which automatically learn a mapping function from an input NL question to an output SQL query. Subsequently, the large pre-trained language models have taken the state-of-the-art of the text-to-SQL parsing task to a new level. In this survey, we present a comprehensive review on deep learning approaches for text-to-SQL parsing. First, we introduce the text-to-SQL parsing corpora which can be categorized as single-turn and multi-turn. Second, we provide a systematical overview of pre-trained language models and existing methods for text-to-SQL parsing. Third, we present readers with the challenges faced by text-to-SQL parsing and explore some potential future directions in this field.
Proton: Probing Schema Linking Information from Pre-trained Language Models for Text-to-SQL Parsing
Jun 28, 2022
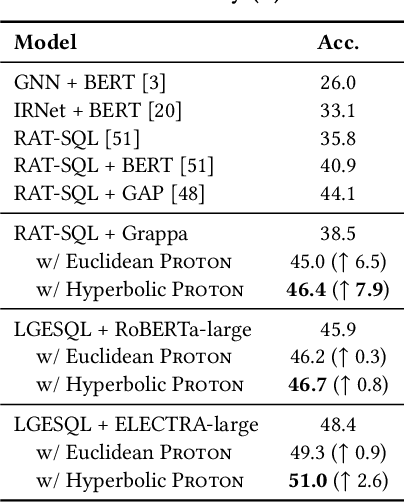
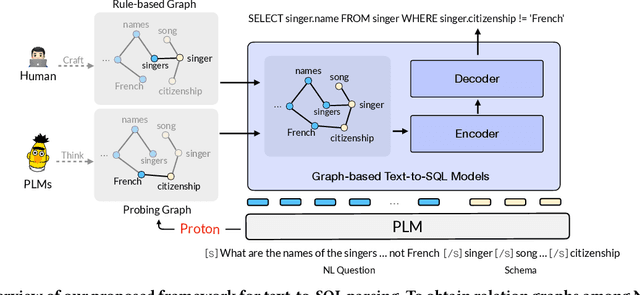
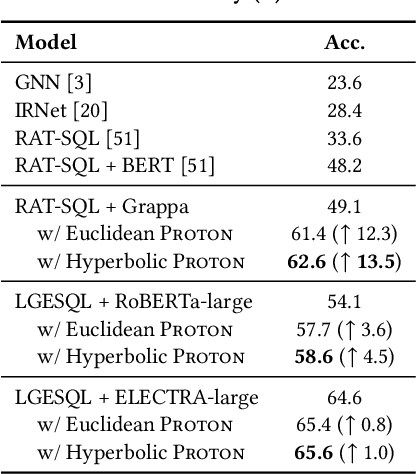
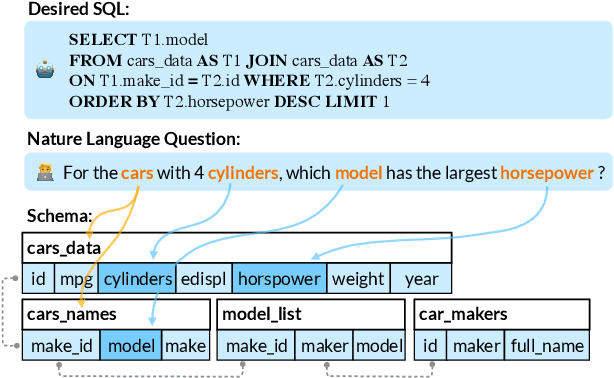
The importance of building text-to-SQL parsers which can be applied to new databases has long been acknowledged, and a critical step to achieve this goal is schema linking, i.e., properly recognizing mentions of unseen columns or tables when generating SQLs. In this work, we propose a novel framework to elicit relational structures from large-scale pre-trained language models (PLMs) via a probing procedure based on Poincar\'e distance metric, and use the induced relations to augment current graph-based parsers for better schema linking. Compared with commonly-used rule-based methods for schema linking, we found that probing relations can robustly capture semantic correspondences, even when surface forms of mentions and entities differ. Moreover, our probing procedure is entirely unsupervised and requires no additional parameters. Extensive experiments show that our framework sets new state-of-the-art performance on three benchmarks. We empirically verify that our probing procedure can indeed find desired relational structures through qualitative analysis.
Bi-VLDoc: Bidirectional Vision-Language Modeling for Visually-Rich Document Understanding
Jun 27, 2022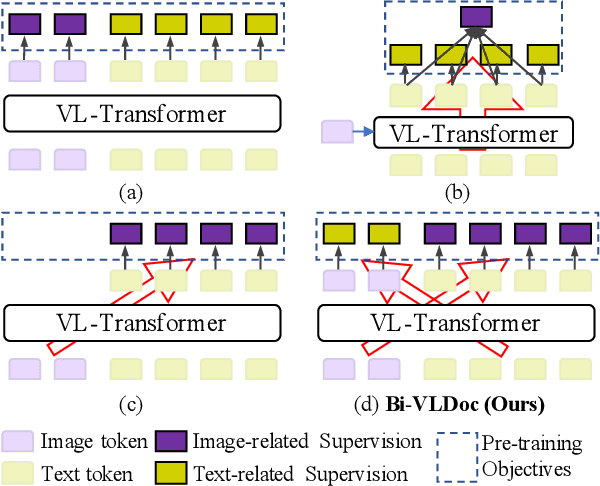
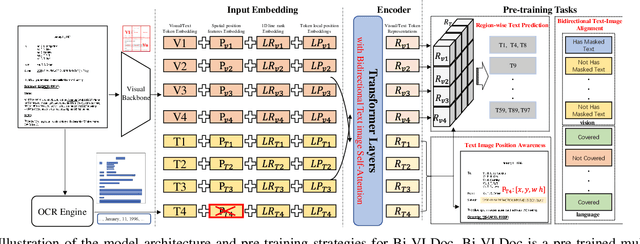
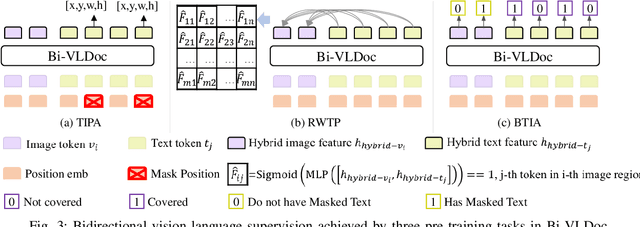
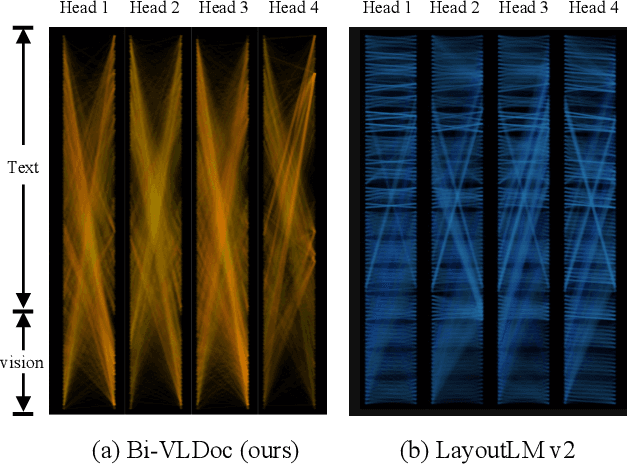
Multi-modal document pre-trained models have proven to be very effective in a variety of visually-rich document understanding (VrDU) tasks. Though existing document pre-trained models have achieved excellent performance on standard benchmarks for VrDU, the way they model and exploit the interactions between vision and language on documents has hindered them from better generalization ability and higher accuracy. In this work, we investigate the problem of vision-language joint representation learning for VrDU mainly from the perspective of supervisory signals. Specifically, a pre-training paradigm called Bi-VLDoc is proposed, in which a bidirectional vision-language supervision strategy and a vision-language hybrid-attention mechanism are devised to fully explore and utilize the interactions between these two modalities, to learn stronger cross-modal document representations with richer semantics. Benefiting from the learned informative cross-modal document representations, Bi-VLDoc significantly advances the state-of-the-art performance on three widely-used document understanding benchmarks, including Form Understanding (from 85.14% to 93.44%), Receipt Information Extraction (from 96.01% to 97.84%), and Document Classification (from 96.08% to 97.12%). On Document Visual QA, Bi-VLDoc achieves the state-of-the-art performance compared to previous single model methods.
Duplex Conversation: Towards Human-like Interaction in Spoken Dialogue Systems
Jun 09, 2022

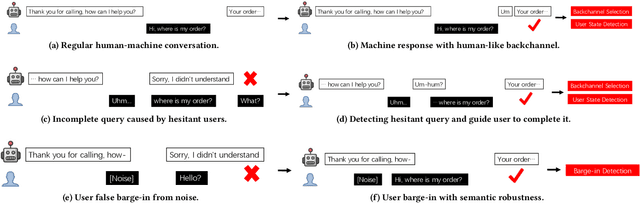
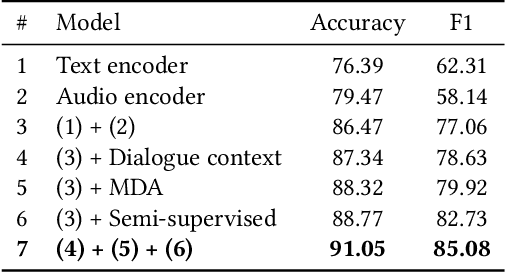
In this paper, we present Duplex Conversation, a multi-turn, multimodal spoken dialogue system that enables telephone-based agents to interact with customers like a human. We use the concept of full-duplex in telecommunication to demonstrate what a human-like interactive experience should be and how to achieve smooth turn-taking through three subtasks: user state detection, backchannel selection, and barge-in detection. Besides, we propose semi-supervised learning with multimodal data augmentation to leverage unlabeled data to increase model generalization. Experimental results on three sub-tasks show that the proposed method achieves consistent improvements compared with baselines. We deploy the Duplex Conversation to Alibaba intelligent customer service and share lessons learned in production. Online A/B experiments show that the proposed system can significantly reduce response latency by 50%.
Decoupling Knowledge from Memorization: Retrieval-augmented Prompt Learning
May 29, 2022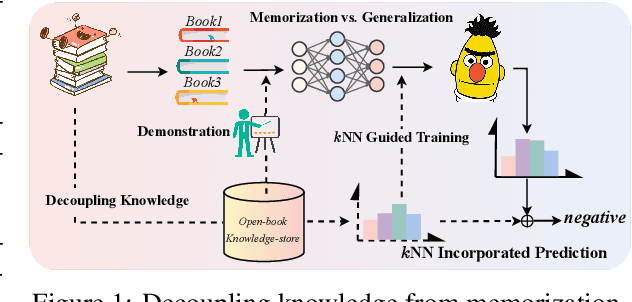
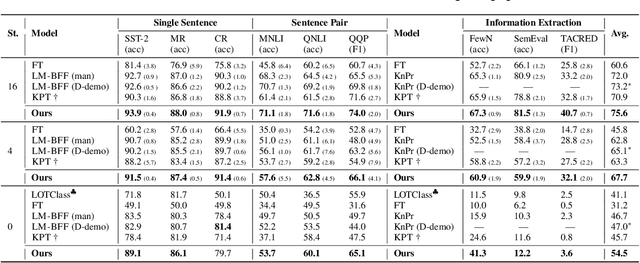
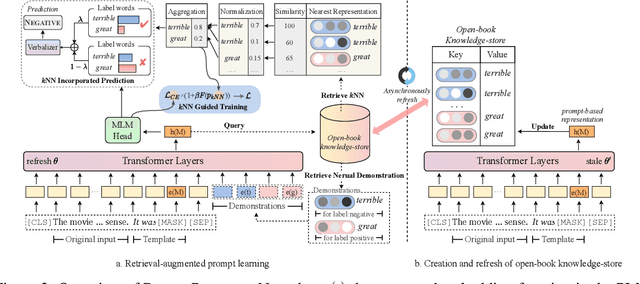
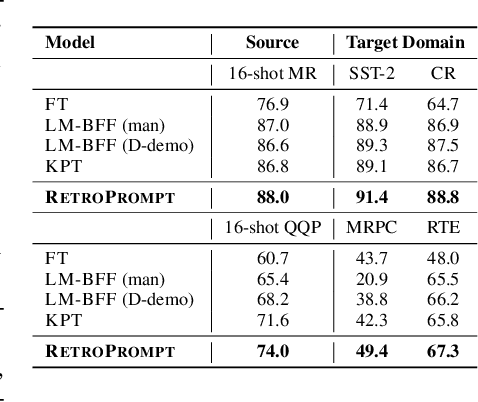
Prompt learning approaches have made waves in natural language processing by inducing better few-shot performance while they still follow a parametric-based learning paradigm; the oblivion and rote memorization problems in learning may encounter unstable generalization issues. Specifically, vanilla prompt learning may struggle to utilize atypical instances by rote during fully-supervised training or overfit shallow patterns with low-shot data. To alleviate such limitations, we develop RetroPrompt with the motivation of decoupling knowledge from memorization to help the model strike a balance between generalization and memorization. In contrast with vanilla prompt learning, RetroPrompt constructs an open-book knowledge-store from training instances and implements a retrieval mechanism during the process of input, training and inference, thus equipping the model with the ability to retrieve related contexts from the training corpus as cues for enhancement. Extensive experiments demonstrate that RetroPrompt can obtain better performance in both few-shot and zero-shot settings. Besides, we further illustrate that our proposed RetroPrompt can yield better generalization abilities with new datasets. Detailed analysis of memorization indeed reveals RetroPrompt can reduce the reliance of language models on memorization; thus, improving generalization for downstream tasks.